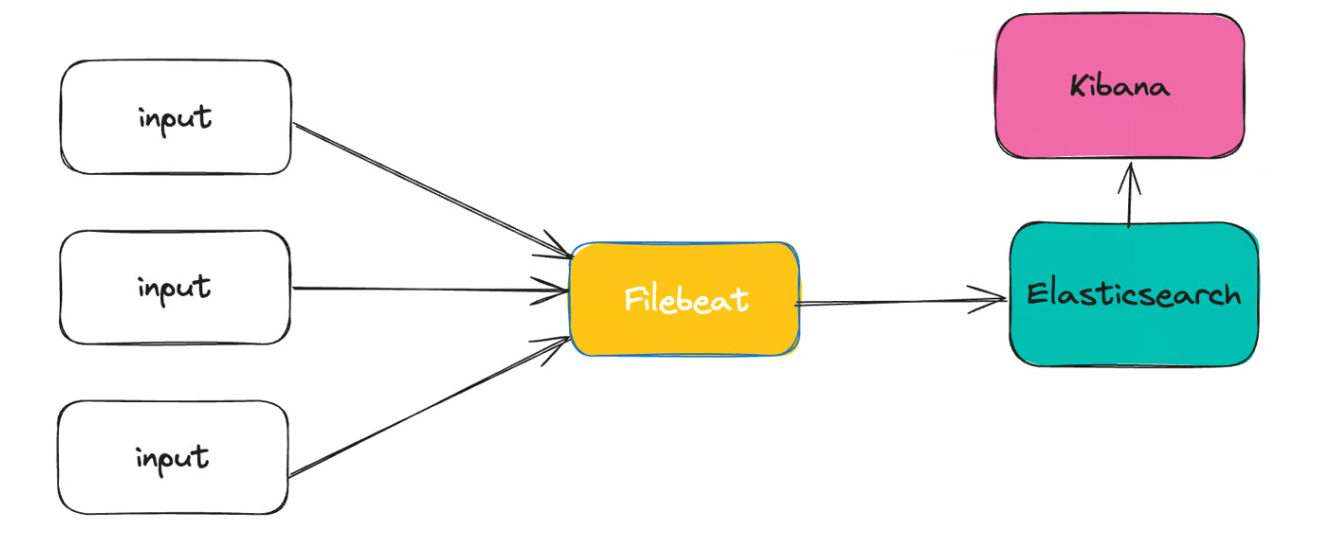
Filebeat
是一款功能强大的日志传送器,旨在简化从不同来源收集、处理和转发日志到不同目的地的过程。Filebeat
在开发时充分考虑了效率,可确保日志管理无缝且可靠。它的轻量级特性和处理大量数据的能力使其成为开发人员和系统管理员的首选。
在本综合指南中,您将深入探索 Filebeat
的功能。从基础知识开始,您将设置 Filebeat
以从各种来源收集日志。然后,您将深入研究高效处理这些日志的复杂性,从
Docker 容器收集日志并将其转发到不同的目标进行分析和监视。
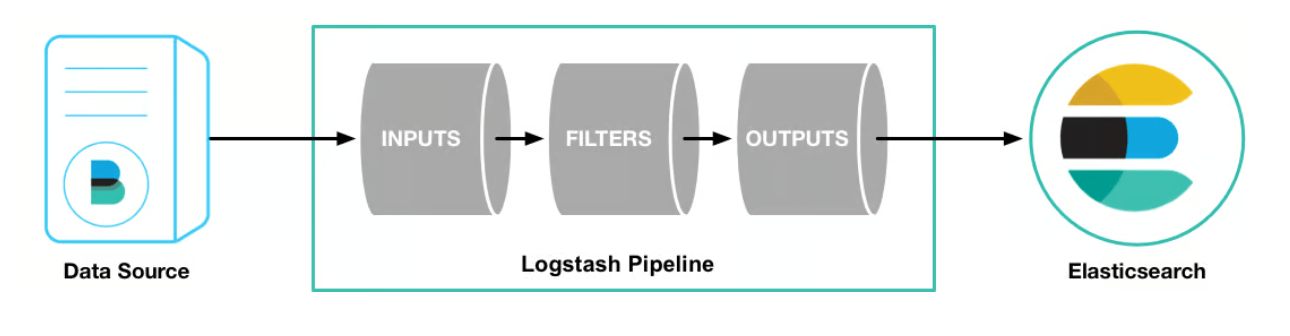
前言
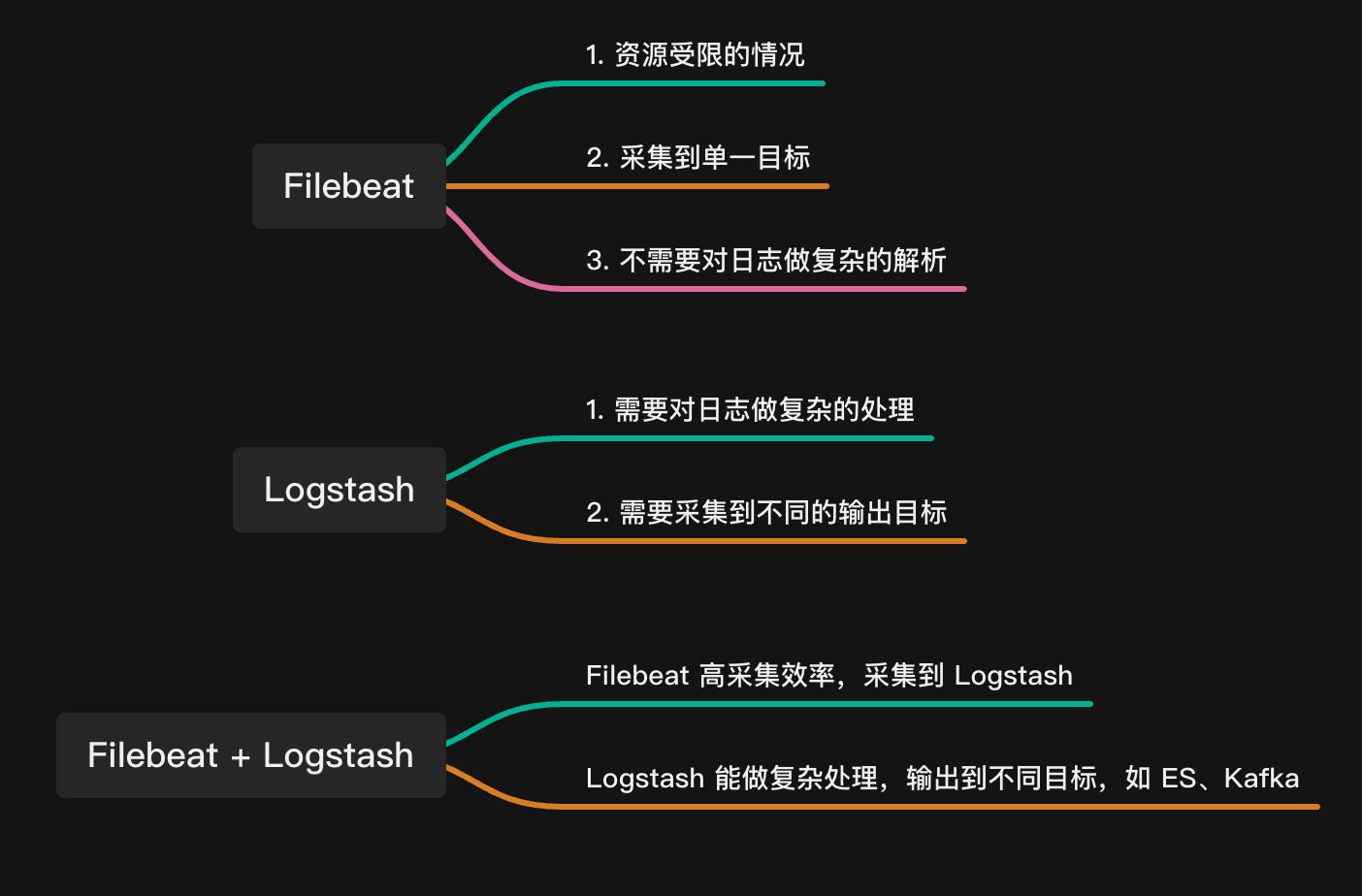
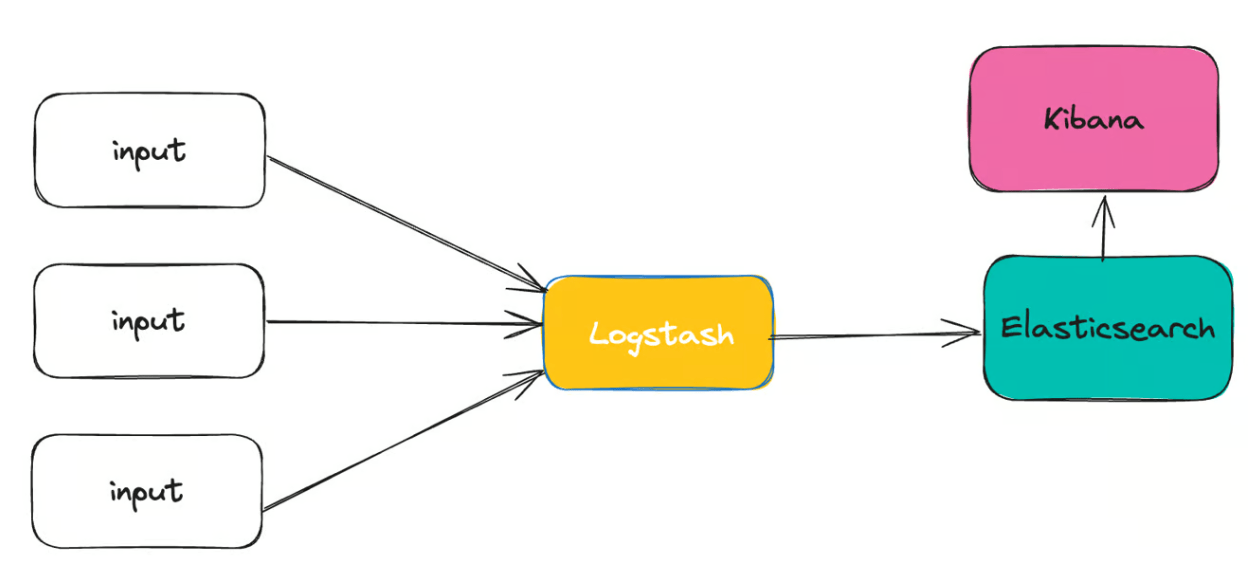
在上一篇文章《Filebeat
vs Logstash:日志采集工具对比》 中,我们对比了 Filebeat 和 Logstash
的一些优缺点,下面是一份简介版的总结:
我们可以看到,我们选择 Filebeat
一方面是因为它占用资源少,另外一方面是我们不需要对日志做复杂的处理,同时也不需要将日志发送到多个目的地。
环境准备
创建用以测试的目录:
1 2 mkdir log-processing-stack cd log-processing-stack
为演示应用程序创建一个子目录并移动到该目录中:
1 mkdir logify && cd logify
完成这些步骤后,您可以在下一节中创建演示日志记录应用程序。
开发演示日志记录应用程序
在本节中,你将使用 Bash
脚本语言构建一个基本的日志记录应用程序。应用程序将定期生成日志,模拟应用程序生成日志数据的真实场景。
在 logify 目录中,创建一个名为 logify.sh
的文件,并将以下内容添加到文件中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 # !/bin/bash filepath="/var/log/logify/app.log" create_log_entry() { local info_messages=("Connected to database" "Task completed successfully" "Operation finished" "Initialized application") local random_message=${info_messages[$RANDOM % ${#info_messages[@]}]} local http_status_code=200 local ip_address="127.0.0.1" local emailAddress="user@mail.com" local level=30 local pid=$$ local time=$(date +%s) local log='{"status": '$http_status_code', "ip": "'$ip_address'", "level": '$level', "emailAddress": "'$emailAddress'", "msg": "'$random_message'", "pid": '$pid', "timestamp": '$time'}' echo "$log" } while true; do log_record=$(create_log_entry) echo "${log_record}" >> "${filepath}" sleep 3 done
create_log_entry() 函数以 JSON
格式生成日志记录,包含严重性级别、消息、HTTP
状态代码和其他关键字段等基本详细信息。此外,它还包括敏感字段,例如电子邮件地址、和
IP 地址,这些字段是特意包含的,以展示 Filebeat
屏蔽字段中敏感数据的能力。
接下来,程序进入无限循环,重复调用 create_log_entry()
函数并将日志写入 /var/log/logify 目录中的指定文件。
添加完代码后,保存更改并使脚本可执行:
然后,创建 /var/log/logify
用于存储应用程序日志的目录:
1 sudo mkdir /var/log/logify
接下来,使用 $USER 环境变量将
/var/log/logify 目录的所有权分配给当前登录的用户:
1 sudo chown -R $USER:$USER /var/log/logify/
在后台运行 logify.sh 脚本:
命令末尾的 &
符号指示脚本在后台运行,允许您在日志记录应用程序独立运行时继续使用终端执行其他任务。
当程序启动时,它将显示如下所示的输出:
此处表示 91773 进程 ID,如果需要,该 ID
可用于稍后终止脚本。
若要查看 app.log 文件的内容,可以使用以下
tail 命令:
1 tail -n 4 /var/log/logify/app.log
此命令以 JSON 格式显示 app.log 文件中的最后 4
个日志条目:
1 2 3 4 { "status" : 200 , "ip" : "127.0.0.1" , "level" : 30 , "emailAddress" : "user@mail.com" , "msg" : "Connected to database" , "pid" : 6512 , "timestamp" : 1709286422 } { "status" : 200 , "ip" : "127.0.0.1" , "level" : 30 , "emailAddress" : "user@mail.com" , "msg" : "Initialized application" , "pid" : 6512 , "timestamp" : 1709286425 } { "status" : 200 , "ip" : "127.0.0.1" , "level" : 30 , "emailAddress" : "user@mail.com" , "msg" : "Initialized application" , "pid" : 6512 , "timestamp" : 1709286428 } { "status" : 200 , "ip" : "127.0.0.1" , "level" : 30 , "emailAddress" : "user@mail.com" , "msg" : "Operation finished" , "pid" : 6512 , "timestamp" : 1709286431 }
现在,您已成功创建用于生成示例日志条目的日志记录应用程序。
安装 Filebeat
我的系统是 MacOS,所以执行下面的命令即可:
1 2 curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.12.2-darwin-x86_64.tar.gz tar xzvf filebeat-8.12.2-darwin-x86_64.tar.gz
最后,进入 filebeat 目录下去执行 filebeat
命令:
1 2 cd filebeat-8.12.2-darwin-x86_64 ./filebeat version
输出:
1 filebeat version 8.12.2 (amd64), libbeat 8.12.2 [0b71acf2d6b4cb6617bff980ed6caf0477905efa built 2024-02-15 13:39:16 +0000 UTC]
Filebeat 的工作原理
在开始使用 Filebeat
之前,了解其工作原理至关重要。在本节中,我们将探讨其基本组件和流程,确保您在深入研究实际使用之前有一个坚实的基础:
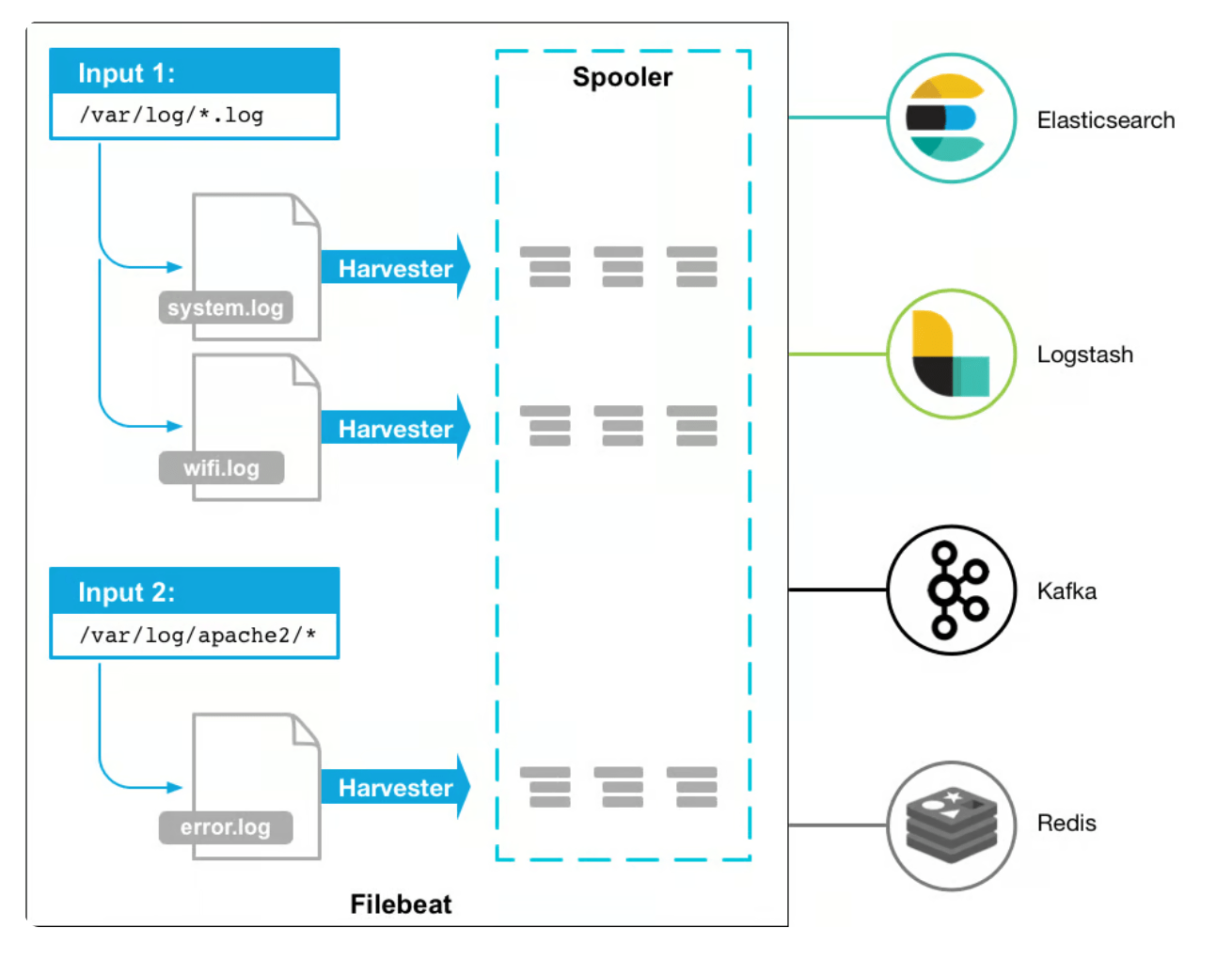
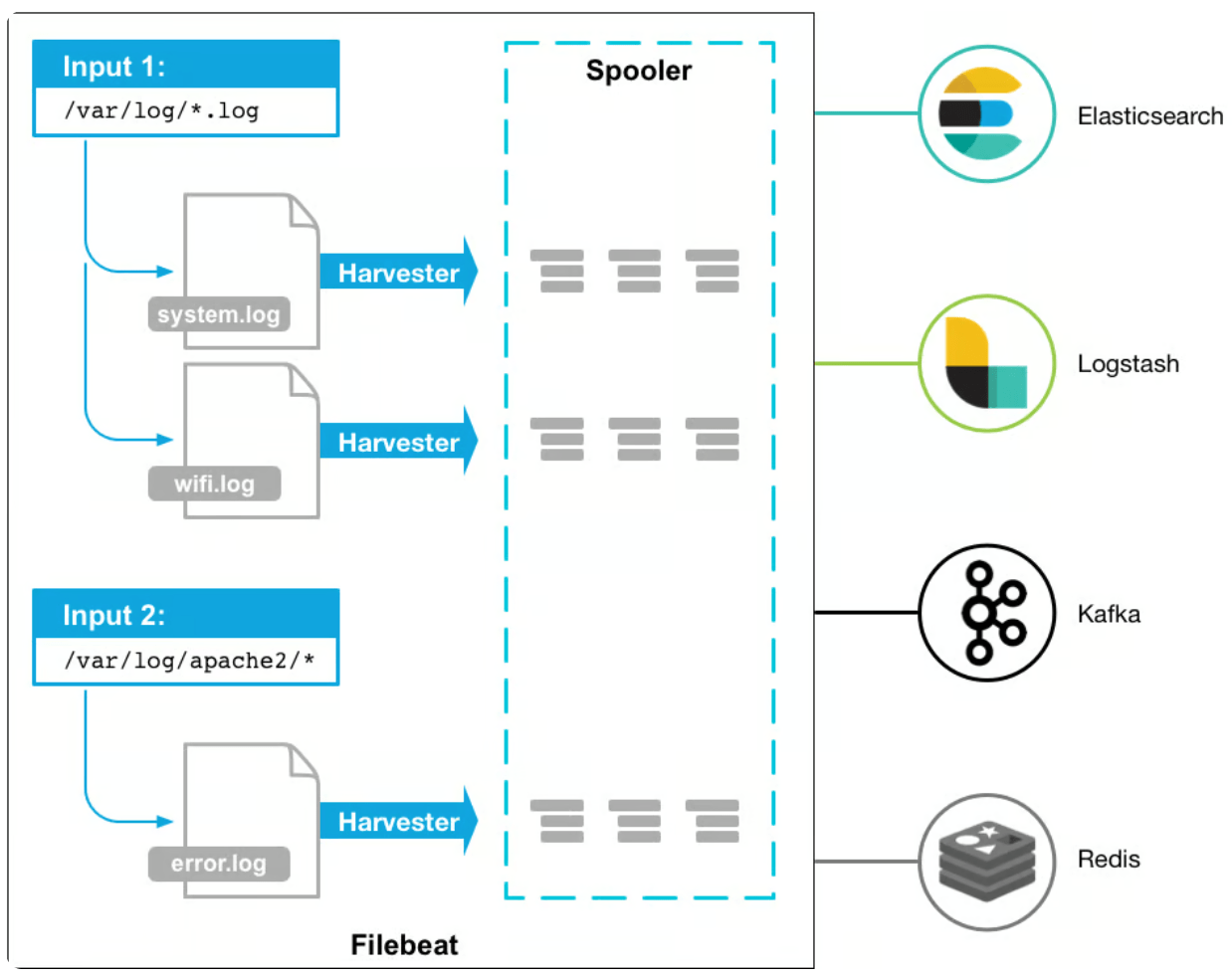
要了解 Filebeat 的工作原理,主要需要熟悉以下组件:
收割机(Harvesters) ,收割机负责逐行读取文件的内容。当
Filebeat
配置为监控特定日志文件时,会为每个文件启动一个收集器。这些收割机不仅可以读取日志数据,还可以管理打开和关闭文件。通过逐行增量读取文件,收集器可确保有效地收集新附加的日志数据并转发以进行处理。输入(Inputs) :输入充当收割机和数据源之间的桥梁。他们负责管理收割机并找到
Filebeat
需要从中读取日志数据的所有来源。可以为各种源(例如日志文件、容器或系统日志)配置输入。用户可以通过定义输入来指定
Filebeat 应监控的文件或位置。
Filebeat
读取日志数据后,日志事件将进行转换或使用数据进行扩充。最后发送到指定的目的地。
可以在 filebeat.yml 配置文件中指定以下行为:
我们可以在下载的目录中看到有一个 filebeat.yml
的配置文件。
1 2 3 4 5 6 filebeat.inputs: . . . processors: . . . output.plugin_name: . . .
现在让我们详细研究每个部分:
filebeat.inputs:Filebeat 实例应监控的输入源。processors:在将数据发送到输出之前对其进行扩充、修改或筛选。output.plugin_name:Filebeat
应转发日志数据的输出目标。
这些指令中的每一个都要求您指定一个执行其相应任务的插件。
现在,让我们来探讨一些可以与 Filebeat
一起使用的输入、处理器和输出。
Filebeat 输入插件
Filebeat
提供了一系列输入插件,每个插件都经过定制,用于从特定来源收集日志数据:
container:收集容器日志。filestream:主动从日志文件中读取行。syslog:从 Syslog 中获取日志条目。httpjson:从 RESTful API 读取日志消息。
Filebeat 输出插件
Filebeat
提供了多种输出插件,使您能够将收集的日志数据发送到不同的目的地:
File:将日志事件写入文件。Elasticsearch:使 Filebeat 能够使用其 HTTP API
将日志转发到 Elasticsearch。Kafka:将日志记录下发给 Apache Kafka。Logstash:直接向 Logstash 发送日志。
Filebeat 模块插件
Filebeat
通过其模块简化日志处理,提供专为特定日志格式设计的预配置设置。这些模块使您能够毫不费力地引入、解析和丰富日志数据,而无需进行大量手动配置。以下是一些可以显著简化日志处理工作流程的可用模块:
Logstash
AWS
PostgreSQL
Nginx
RabbitMQ
HAproxy
Filebeat 入门
现在您已经了解了 Filebeat
的工作原理,让我们将其配置为从文件中读取日志条目并将其显示在控制台上。
首先,打开位于解压目录的 Filebeat 配置文件
filebeat.yml:
接下来,清除文件的现有内容,并将其替换为以下代码:
1 2 3 4 5 6 7 filebeat.inputs: - type: log paths: - /var/log/logify/app.log output.console: pretty: true
在本节 filebeat.inputs 中,您指定 Filebeat 应使用
logs 插件从文件中读取日志。paths 参数指示
Filebeat 将监控的日志文件的路径,此处设置为
/var/log/logify/app.log。
output.console
部分将收集到的日志数据发送到控制台。pretty: true
参数可确保日志条目在控制台上显示时以可读且结构良好的格式显示。
添加这些配置后,保存文件。
在执行 Filebeat 之前,必须验证配置文件语法以识别和纠正任何错误:
1 ./filebeat -c ./filebeat.yml test config
如果配置文件正确,则应看到以下输出:
现在,继续运行 Filebeat:
1 ./filebeat -c ./filebeat.yml
当 Filebeat 开始运行时,它将显示类似于以下内容的日志条目:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 { "@timestamp" : "2024-03-02T01:35:34.696Z" , "@metadata" : { "beat" : "filebeat" , "type" : "_doc" , "version" : "8.12.2" } , "log" : { "offset" : 2875279 , "file" : { "path" : "/var/log/logify/app.log" } } , "message" : "{\"status\": 200, \"ip\": \"127.0.0.1\", \"level\": 30, \"emailAddress\": \"user@mail.com\", \"msg\": \"Task completed successfully\", \"pid\": 6512, \"timestamp\": 1709343333}" , "input" : { "type" : "log" } , "ecs" : { "version" : "8.0.0" } , "host" : { "name" : "rubys-iMac.local" } , "agent" : { "version" : "8.12.2" , "ephemeral_id" : "310a7b92-f2fb-42ca-b3d8-e32e348c7a57" , "id" : "f177dd40-1249-487c-b9da-aaab03cfd05c" , "name" : "rubys-iMac.local" , "type" : "filebeat" } }
Filebeat 现在在控制台中显示日志消息。Bash 脚本中的日志事件位于
message 字段下,Filebeat
添加了其他字段以提供上下文。您现在可以通过按 CTRL + C 停止
Filebeat。
成功配置 Filebeat
以读取日志并将其转发到控制台后,下一节将重点介绍数据转换。
使用 Filebeat 转换日志
当 Filebeat
收集数据时,您可以在将其发送到输出之前对其进行处理。您可以使用新字段来丰富它,解析数据,以及删除或编辑敏感字段以确保数据隐私。
在本部分中,你将通过以下方式转换日志:
解析 JSON 日志。
删除不需要的字段。
添加新字段。
屏蔽敏感数据。
使用 Filebeat 解析 JSON 日志
由于演示日志记录应用程序以 JSON
格式生成日志,因此必须正确解析它们以进行结构化分析。
让我们检查上一节中的示例日志事件:
1 2 3 4 5 6 ... "message": "{\"status\": 200, \"ip\": \"127.0.0.1\", \"level\": 30, \"emailAddress\": \"user@mail.com\", \"msg\": \"Task completed successfully\", \"pid\": 6512, \"timestamp\": 1709343333}", "input": { "type": "log" }, ...
要将日志事件解析为有效的 JSON,请打开 Filebeat 配置文件:
然后,使用以下代码行更新文件:
1 2 3 4 5 6 7 8 9 10 11 12 filebeat.inputs: - type: log paths: - /var/log/logify/app.log processors: - decode_json_fields: fields: ["message" ] target: "" output.console: pretty: true
在上面的代码片段中,您将处理器配置为 decode_json_fields
解码每个日志条目 message 字段中的 JSON
编码数据,并将其附加到日志事件。
保存并退出文件。使用以下命令重新运行 Filebeat:
1 ./filebeat -c ./filebeat.yml
如果配置文件正确,则应看到以下输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 { "@timestamp" : "2024-03-02T01:43:07.367Z" , "@metadata" : { "beat" : "filebeat" , "type" : "_doc" , "version" : "8.12.2" } , "status" : 200 , "ip" : "127.0.0.1" , "level" : 30 , "message" : "{\"status\": 200, \"ip\": \"127.0.0.1\", \"level\": 30, \"emailAddress\": \"user@mail.com\", \"msg\": \"Initialized application\", \"pid\": 6512, \"timestamp\": 1709343785}" , "ecs" : { "version" : "8.0.0" } , "host" : { "name" : "rubys-iMac.local" } , "agent" : { "type" : "filebeat" , "version" : "8.12.2" , "ephemeral_id" : "f33a1fc6-e8f1-4dde-8740-5f85a1e8bcfd" , "id" : "f177dd40-1249-487c-b9da-aaab03cfd05c" , "name" : "rubys-iMac.local" } , "pid" : 6512 , "timestamp" : 1709343785 , "log" : { "offset" : 2898143 , "file" : { "path" : "/var/log/logify/app.log" } } , "input" : { "type" : "log" } , "emailAddress" : "user@mail.com" , "msg" : "Initialized application" }
在输出中,您将看到 message 字段中的所有属性(如
msg、 ip 等)都已添加到日志事件中。
现在,您可以解析 JSON 日志,您将修改日志事件的属性。
使用 Filebeat 添加和删除字段
日志事件包含需要保护的敏感 emailAddress
字段。在本部分中,你将删除该 emailAddress
字段,并向日志事件添加一个新字段,以提供更多上下文。
打开 Filebeat 配置文件:
添加以下行以修改日志事件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 filebeat.inputs: - type: log paths: - /var/log/logify/app.log processors: - decode_json_fields: fields: ["message" ] target: "" - drop_fields: fields: ["emailAddress" , "message" ] - add_fields: fields: env: "environment" output.console: pretty: true
若要修改日志事件,请添加 drop_fields
处理器,该处理器具有一个 field
选项,用于获取要删除的字段列表,包括敏感 EmailAddress
字段和 message 字段。删除 message
字段是因为在分析数据后,message
字段的属性已合并到日志事件中,从而使原始 message
字段过时。
编写代码后,保存并退出文件。然后,重新启动 Filebeat:
1 ./filebeat -c ./filebeat.yml
运行 Filebeat 时,您会注意到该 emailAddress
字段已被成功删除,并且已将一个新 env
字段添加到日志事件中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 { "@timestamp" : "2024-03-02T01:47:33.907Z" , "@metadata" : { "beat" : "filebeat" , "type" : "_doc" , "version" : "8.12.2" } , "ip" : "127.0.0.1" , "level" : 30 , "log" : { "offset" : 2911714 , "file" : { "path" : "/var/log/logify/app.log" } } , "ecs" : { "version" : "8.0.0" } , "msg" : "Operation finished" , "pid" : 6512 , "timestamp" : 1709344053 , "status" : 200 , "fields" : { "env" : "environment" } , "input" : { "type" : "log" } , "host" : { "name" : "rubys-iMac.local" } , "agent" : { "version" : "8.12.2" , "ephemeral_id" : "607c49c8-9339-4851-b8e6-caab3bf6138b" , "id" : "f177dd40-1249-487c-b9da-aaab03cfd05c" , "name" : "rubys-iMac.local" , "type" : "filebeat" } }
现在,您可以扩充和删除不需要的字段,接下来将编写条件语句。
在 Filebeat 中使用条件语句
Filebeat 允许您检查条件,并在条件计算结果为 true
时添加字段。在本节中,您将检查该 status 值是否等于
true ,如果满足条件,您将向日志事件添加一个
is_successful 字段。
为此,请打开配置文件:
之后,添加突出显示的行以根据指定条件添加 is_successful
字段:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 ... processors: - decode_json_fields: fields: ["message" ] target: "" - drop_fields: fields: ["emailAddress" ] - add_fields: fields: env: "environment" - add_fields: when: equals: status: 200 target: "" fields: is_successful: true ...
该 when 选项检查 status 字段值是否等于
200。如果为 true,则将该
is_successful 字段添加到日志事件中。
保存新更改后,启动 Filebeat:
1 ./filebeat -c ./filebeat.yml
Filebeat 将生成与此内容密切相关的输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 { "@timestamp" : "2024-03-02T01:50:31.697Z" , "@metadata" : { "beat" : "filebeat" , "type" : "_doc" , "version" : "8.12.2" } , "status" : 200 , "ip" : "127.0.0.1" , "level" : 30 , "ecs" : { "version" : "8.0.0" } , "fields" : { "env" : "environment" } , "input" : { "type" : "log" } , "host" : { "name" : "rubys-iMac.local" } , "agent" : { "version" : "8.12.2" , "ephemeral_id" : "20cca3c1-6ba3-4a78-8e0e-cb07bdb885f1" , "id" : "f177dd40-1249-487c-b9da-aaab03cfd05c" , "name" : "rubys-iMac.local" , "type" : "filebeat" } , "is_successful" : true , "msg" : "Task completed successfully" , "pid" : 6512 , "log" : { "file" : { "path" : "/var/log/logify/app.log" } , "offset" : 2920724 } , "timestamp" : 1709344231 }
在输出中,该 is_successful 字段已添加到日志条目中,HTTP
状态代码为 200。
这负责根据条件添加新字段。
使用 Filebeat 编辑敏感数据
在本文前面,您删除了 emailAddress
字段以确保数据隐私。但是,IP
地址敏感字段仍保留在日志事件中。此外,组织内的其他开发人员可能会无意中将敏感数据添加到日志事件中。通过编辑与特定模式匹配的数据,您可以屏蔽任何敏感信息,而无需删除整个字段,从而确保保留消息的重要性。
在文本编辑器中,打开 Filebeat 配置文件:
添加以下代码以编辑 IP 地址:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 ... processors: - script: lang: javascript id: redact-sensitive-info source: | function process(event) { // Redact IP addresses (e.g., 192.168.1.1) from the "message" field event.Put("message", event.Get("message").replace(/\b\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\b/g, "[REDACTED-IP]")); } - decode_json_fields: fields: ["message" ] target: "" - drop_fields: fields: ["emailAddress" ] - add_fields: fields: env: "environment" - add_fields: when: equals: status: 200 target: "" fields: is_successful ...
在添加的代码中,您将定义一个用 JavaScript
编写的脚本,用于编辑日志事件中的敏感信息。该脚本使用正则表达式来标识 IP
地址,并分别将它替换为 [REDACTED-IP]。
添加代码后,运行 Filebeat:
1 ./filebeat -c ./filebeat.yml
输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 { "@timestamp" : "2024-03-02T01:53:50.792Z" , "@metadata" : { "beat" : "filebeat" , "type" : "_doc" , "version" : "8.12.2" } , "log" : { "offset" : 2930777 , "file" : { "path" : "/var/log/logify/app.log" } } , "pid" : 6512 , "status" : 200 , "fields" : { "env" : "environment" } , "msg" : "Initialized application" , "is_successful" : true , "level" : 30 , "input" : { "type" : "log" } , "ecs" : { "version" : "8.0.0" } , "host" : { "name" : "rubys-iMac.local" } , "agent" : { "id" : "f177dd40-1249-487c-b9da-aaab03cfd05c" , "name" : "rubys-iMac.local" , "type" : "filebeat" , "version" : "8.12.2" , "ephemeral_id" : "8bf595e9-0376-42ec-be51-42a104527449" } , "timestamp" : 1709344429 , "ip" : "[REDACTED-IP]" }
输出中的日志事件现在将 IP 地址替换为 [REDACTED-IP]。
注意:上面的脚本会将 message 中的所有 IP
地址都替换。
您现在可以停止 Filebeat 和 logify.sh 程序。
若要停止 bash 脚本,请获取进程 ID:
输出:
1 [1] + 6512 running ./logify.sh
替换 kill 命令中的进程 ID:
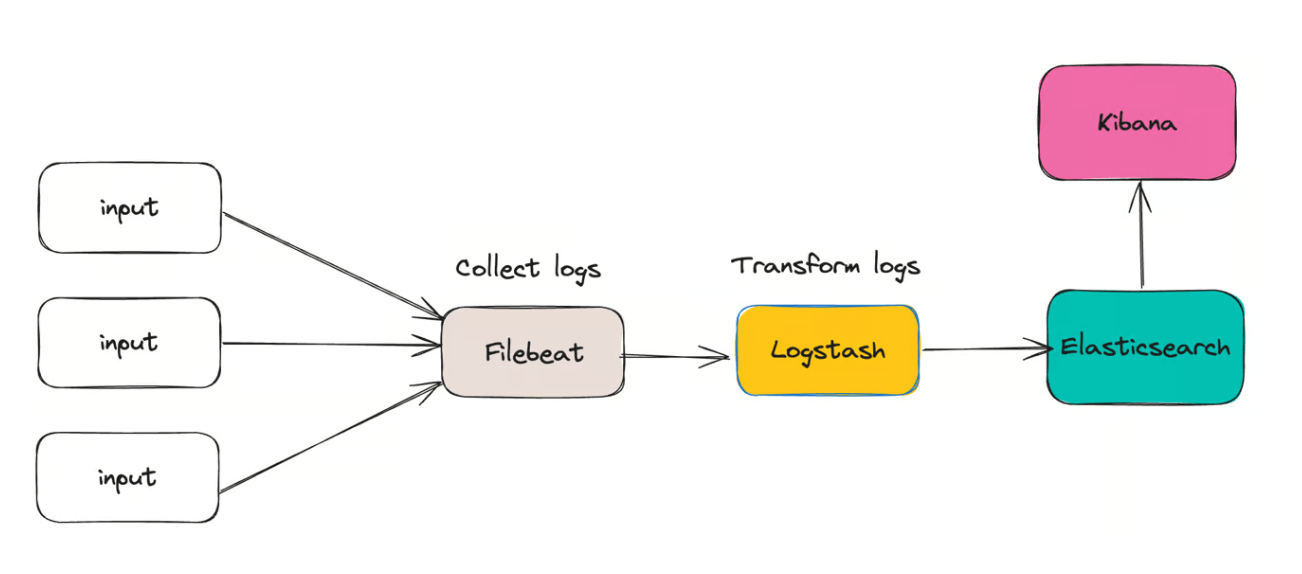
成功编辑敏感字段后,您现在可以使用 Filebeat 从 Docker
容器收集日志,并将它们集中起来以进行进一步的分析和监控。
总结
在本文中,我们介绍了 Filebeat
的基本概念和工作原理。我们还演示了如何配置 Filebeat
以收集日志,并使用处理器对日志事件进行转换。我们还讨论了 Filebeat
的输入、输出和模块插件,以及如何使用条件语句和脚本处理器来编辑日志事件。