使用阿里云 DTS 同步 RDS 数据到 ClickHouse
在工作中,往往有一些需要对大批量数据进行分析的场景,依赖于传统关系型数据库(如 MySQL)的话,效率往往及其低下。 相比之下,一些 OLAP 数据库在统计分析等场景下表现优异,比如 ClickHouse。
比如:
- 扫描数据量:ClickHouse 采用列式存储,同一列的数据物理上连续存储,查询时只需读取目标列,而 MySQL 查询一列需要扫描 20 列数据(假设表有 20 列)
- 数据压缩:ClickHouse 存储的数据是经过压缩的,读取的时候可以减少 IO 的开销。
- 多核计算:ClickHouse 的查询任务可以自动拆分到多个 CPU 核心执行,充分利用现代硬件并行能力。
也就是说,不管是存储、读取还是计算,专门的 OLAP 数据库都比 OLTP 关系型数据库要高效。 正因如此,我们会选择使用一些 OLAP 数据库来处理一些数据分析的业务,比如 ClickHouse,这个时候如何将数据从 MySQL 同步到 ClickHouse 就成了一个亟需解决的问题。
如何将数据从 MySQL 同步到 ClickHouse
目前比较有效的在 MySQL 和 ClickHouse 之间同步数据的方式都是通过 binlog 捕获数据库变更,然后写入到 ClickHouse。比如有如下的一些方案:
- Debezium + Kafka:通过 Debezium 捕获 MySQL 的 Binlog 变更事件,经 Kafka 中转后写入 ClickHouse。
- Canal + Kafka:通过 Canal 捕获 MySQL 的 Binlog 变更事件,经 Kafka 中转后写入 ClickHouse。
- 使用阿里云 DTS(数据传输服务):DTS 支持 MySQL 到 ClickHouse 的实时同步。
但是直接通过捕获 MySQL 的 binlog 写入 ClickHouse,在运维层面复杂度还是偏高,如果使用的是阿里云的 RDS, 可以直接使用阿里云的 DTS 来进行 MySQL 到 ClickHouse 的同步,好处是我们不需要处理底层同步的一些细节问题。
DTS 里面包含了几种服务,本文只是使用它提供的数据订阅服务。
阿里云 DTS 数据订阅的工作原理
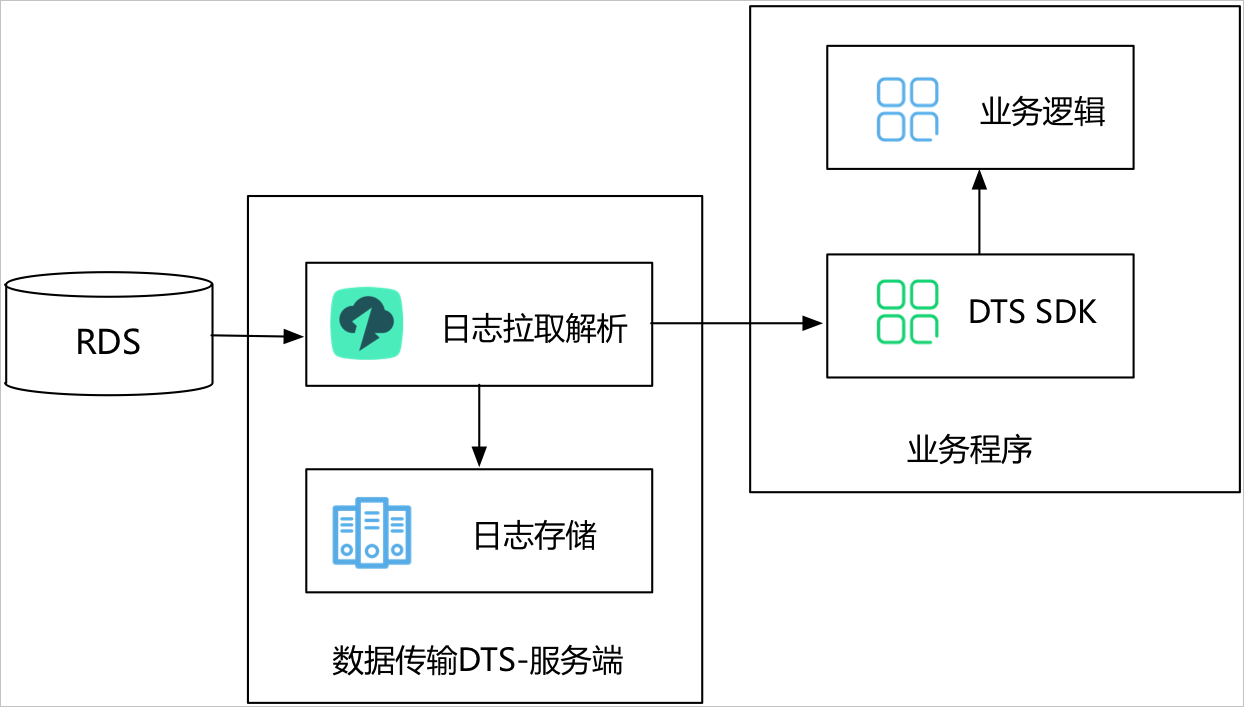
数据订阅支持实时拉取 RDS 实例的增量日志,用户可以通过 DTS 提供的 SDK 数据订阅服务端来订阅增量日志,同时可以根据业务需求,实现数据定制化消费。
在这个过程中,我们需要处理的就是 业务逻辑 部分,也就是获取到 RDS 的数据库变更之后,如何将这些变更写入到 ClickHouse。我们可以选择处理全部字段,或者只处理自己需要的某些字段。
如何使用阿里云 DTS 同步 MySQL 到 ClickHouse
具体文档可在阿里云文档查看:数据传输服务 - 快速入门 - 数据订阅操作指导。
ClickHouse 安装配置(CentOS)
我们可以通过如下命令来安装 ClickHouse:
1 | sudo yum install -y yum-utils |
安装完毕后,通过下面的命令来启动 ClickHouse 服务:
1 | sudo systemctl enable clickhouse-server |
如果一切顺利,我们会看到如下输出:
1 | ● clickhouse-server.service - ClickHouse Server (analytic DBMS for big data) |
如果不是绿色的
active,则可以通过journalctl -xe -u clickhouse-server查看一下具体错误。
下面是通过 yum install 安装的 ClickHouse
的一些目录:
/var/log/clickhouse-server日志/var/run/clickhouse-server运行时的一些文件/etc/clickhouse-server配置目录/var/lib/clickhouse
配置文件位置:/etc/clickhouse-server/config.xml,我们可以通过修改这个配置文件来调整
ClickHouse 服务的相关参数。如:
listen_host修改绑定的 ip 地址,如果需要给本机以外的人访问,可以修改为0.0.0.0
连接到 ClickHouse
我们可以通过下面的命令来连接到 ClickHouse:
1 | clickhouse-client --host 127.0.0.1 --port 9011 |
这跟 MySQL 的命令行类似,除了样子长得像以外,很多的 SQL 语句都是跟
MySQL 一样的。比如,进入交互式的命令行之后,我们可以通过
show databases; 来查看有哪些数据库:
1 | ➜ ~ clickhouse-client --host 127.0.0.1 --port 9011 |
注意:这里的 9011 端口是我本地的端口,不是默认的端口。
创建对应的 ClickHouse 数据库和表
现在,假设我们的 MySQL 中有一个名字为 order
的数据库,里面有一个 orders
的表。然后我们需要将其中的一些字段同步到 ClickHouse
中,首先我们需要创建对应的数据库和表。
- 创建数据库
1 | create database order; |
- 创建表
1 | create table `orders`( |
初次同步数据到 ClickHouse
因为 DTS 只能捕获增量数据,初次同步的时候我们需要手动将 MySQL 中的全量数据导入到 ClickHouse。如果表的数据写入频繁的话,可能需要停服之后再进行此操作。
我们可以通过下面的命令来从 MySQL 直接导数据到 ClickHouse:
1 | INSERT INTO orders SELECT |
在实际执行中,将 MySQL 里面的信息替换为你自己的 MySQL 配置即可。在导入数据完成后,可以通过下面的命令来查看导入是否成功:
1 | example.com :) select count(*) from orders; |
如果 count 的值跟 MySQL
中的数据一致,则说明导入成功。
在这一步执行完成之后,就可以启动 DTS 的数据订阅服务了。后续的数据库变动会被捕获到,直到我们 ack 为止。
MySQL 跟 ClickHouse 的字段对应关系
太长了,自己复制到浏览器打开:
https://help.aliyun.com/zh/dts/user-guide/use-a-kafka-client-to-consume-tracked-data-2#section-woc-4pq-mes
编写数据订阅的代码(Python)
官方 demo 在:https://github.com/aliyun/aliyun-dts-subscribe-demo/tree/master/python
核心代码如下(比较标准的 Kafka 消费者代码):
1 | dts_record_schema = schema.load_schema( |
但是官方的 demo 实在是过于简陋,所以这里会针对里面一些比较关键的地方说明一下:
schema.load_schema和schemaless_reader,python版本的 SDK 使用了fastavro来解析 Avro 格式的数据,所以需要用到fastavro.schemaless_reader来读取数据。- Kafka Consumer 配置参数在 DTS 订阅任务那里都可以看到,其中 username 和 password 是新建订阅任务的时候自己填写的。
record = decode(msg.value)这一行会将 Kafka 中的数据解码成字典格式,这样就可以直接使用了。record里面包含的字段可以看dts_record_avsc/com.alibaba.dts.formats.avro.Record.avsc这里面的定义。operation字段表示的是操作类型,比如INSERT,UPDATE,DELETE等。我们可以根据这个字段来决定在 ClickHouse 中执行什么样的操作。record的beforeImages是数据变更前的字段值,afterImages是数据变更后的字段值。在执行insert操作的时候beforeImages是空的,在执行delete操作的时候afterImages是空的。update的时候,两个都有值,分别是变动前后的字段变动。
官方 demo
的代码只是给出了基本的消费的代码,在实际开发中,我们还需要根据
operation 字段来决定在 ClickHouse
中执行什么样的操作。如,我们可以像下面这样做一些插入、删除的操作:
1 | if op == 'INSERT': |
更具体代码自行实现了。需要注意的是,在插入之前,可能需要做一些数据类型转换的操作,否则可能在插入到 ClickHouse 的时候出现类型不匹配的问题。
部署(CentOS)
本文以 conda 和 supervisor
来作为示例部署。
Python 环境(conda)
由于 Python 各版本的差异,所以更推荐使用 conda 来管理
Python 环境,我们可以通过以下命令来安装一下 miniconda:
1 | wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh |
安装到默认的 ~/miniconda3 目录即可。
conda 的常用命令:
1 | /root/miniconda3/bin/conda env list # 列出所有环境 |
更详细的内容可参考官方文档:https://www.anaconda.com/docs/getting-started/miniconda/install#macos-linux-installation
supervisor
1 | [program:dts_consumer] |
保存到服务器的 /etc/supervisord.d 目录,然后执行:
1 | supervisorctl update |
即可启动。
参考文档
- DTS 常见问题 https://help.aliyun.com/zh/dts/support/faq#section-fle-1lu-lla
- Kafka https://kafka.apache.org/intro
- fastavro https://fastavro.readthedocs.io/en/latest/
- 排查订阅任务问题 https://help.aliyun.com/zh/dts/user-guide/troubleshoot-issues-in-change-tracking-tasks
- MySQL 字段类型与 dataTypeNumber 数值的对应关系 https://help.aliyun.com/zh/dts/user-guide/use-a-kafka-client-to-consume-tracked-data-2#section-woc-4pq-mes