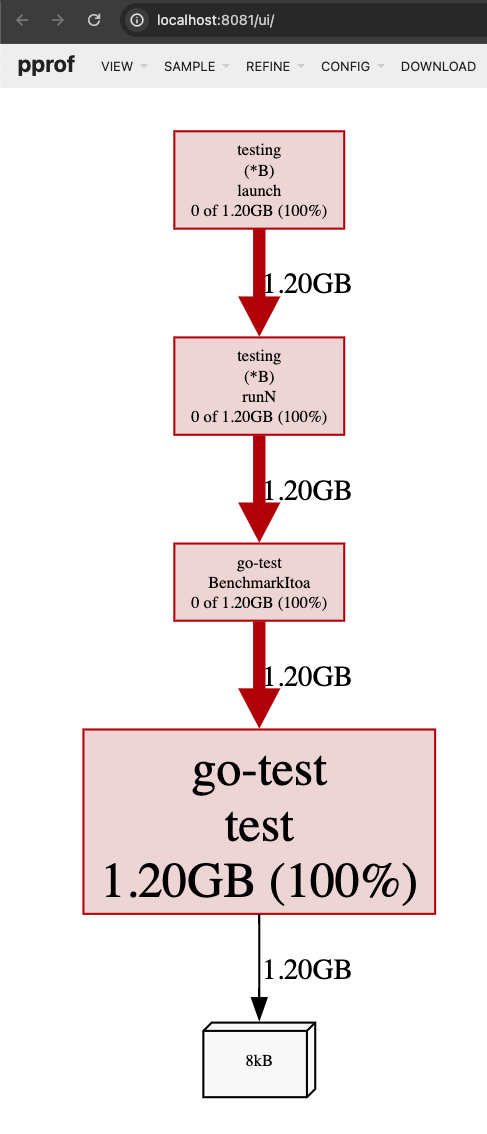
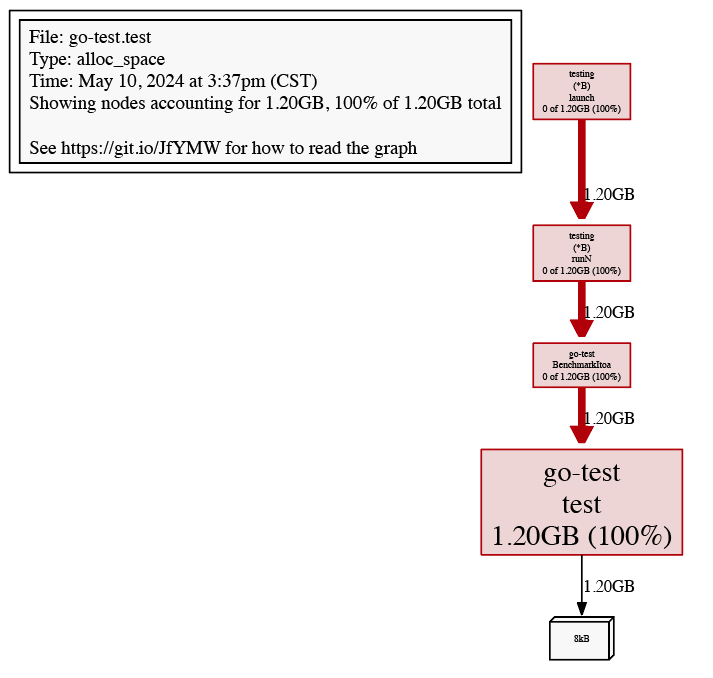
File: go-test.test Type: cpu Time: May 10, 2024 at 3:21pm (CST) Duration: 1.61s, Total samples = 1.24s (76.86%) Entering interactive mode (type "help" for commands, "o" for options) (pprof)
我们可以使用 top 命令来查看 CPU 占用最高的函数:
1 2 3 4 5 6 7 8
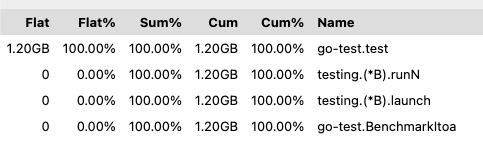
(pprof) top Showing nodes accounting for 1.24s, 100% of 1.24s total flat flat% sum% cum cum% 1.24s 100% 100% 1.24s 100% go-test.fib 0 0% 100% 1.24s 100% go-test.BenchmarkFib 0 0% 100% 1.24s 100% testing.(*B).launch 0 0% 100% 1.24s 100% testing.(*B).runN (pprof)
我们也可以在 top
命令后面加上一个数字,表示显示前几个占用 CPU 时间最多的函数。比如
top3 表示显示前 3 个。
也就是说,我们可以通过 pprof
工具来查看哪些地方占用了比较多的 CPU
时间,从而进行性能优化。
funcTestAdd2(t *testing.T) { cases := []struct { name string a, b, sum int }{ {"case1", 1, 2, 3}, {"case2", 2, 3, 5}, {"case3", 3, 4, 7}, }
for _, c := range cases { t.Run(c.name, func(t *testing.T) { sum := Add(c.a, c.b) if sum != c.sum { t.Errorf("Sum was incorrect, got: %d, want: %d.", sum, c.sum) } }) } }
输出:
1 2 3 4 5 6 7 8 9 10 11
➜ go-test go test --- FAIL: TestAdd2 (0.00s) --- FAIL: TestAdd2/case1 (0.00s) add_test.go:21: Sum was incorrect, got: 4, want: 3. --- FAIL: TestAdd2/case2 (0.00s) add_test.go:21: Sum was incorrect, got: 6, want: 5. --- FAIL: TestAdd2/case3 (0.00s) add_test.go:21: Sum was incorrect, got: 8, want: 7. FAIL exit status 1 FAIL go-test 0.004s
➜ go-test go test Before test After test --- FAIL: TestAddSuite (0.00s) --- FAIL: TestAddSuite/TestAdd (0.00s) add_test.go:22: Error Trace: /Users/ruby/GolandProjects/go-test/add_test.go:22 Error: Not equal: expected: 4 actual : 3 Test: TestAddSuite/TestAdd FAIL exit status 1 FAIL go-test 0.006s
➜ go-test go test /var/folders/dm/r_hly4w5557b000jh31_43gh0000gp/T/TestAdd4259799402/001 /var/folders/dm/r_hly4w5557b000jh31_43gh0000gp/T/TestAdd4259799402/002 PASS ok go-test 0.004s
临时的环境变量
t.Setenv(key, value string):设置一个临时的环境变量,这个环境变量会在测试函数结束后被还原。
➜ go-test go test -v === RUN TestAdd add_test.go:10: Add(1, 2) = 4; want 3 add_test.go:10: Add(2, 3) = 6; want 5 --- FAIL: TestAdd (0.00s) FAIL exit status 1 FAIL go-test 0.004s
我们可以看到,两个测试失败输出的报错行都是 test
函数里面的 t.Errorf,而不是 test 函数的调用者
TestAdd,也就是说,在这种情况下我们不好知道是
test(1, 2, 3, t) 还是 test(2, 3, 5, t)
失败了(当然我们这里还是挺明显的,只是举个例子),这时我们可以使用
t.Helper():
1 2 3 4 5 6 7
functest(a, b, sum int, t *testing.T) { t.Helper() // 在助手函数中加上这一行 result := Add(a, b) if result != sum { t.Errorf("Add(%d, %d) = %d; want %d", a, b, result, sum) } }
输出如下:
1 2 3 4 5 6 7 8
➜ go-test go test -v === RUN TestAdd add_test.go:16: Add(1, 2) = 4; want 3 add_test.go:17: Add(2, 3) = 6; want 5 --- FAIL: TestAdd (0.00s) FAIL exit status 1 FAIL go-test 0.004s