Docker 不完全指南
在上周一次跟同事聊天的时候,他提到自己最近在尝试搭建一个
gerrit
服务器(一个代码审查平台),但是尝试多次未果,而且还将 ubuntu
虚拟机多次搞崩重装。
(这让我想起了自己大学时候折腾 ubuntu 时也是搞崩了无数次,而且不是虚拟机,有一段时间里,每天就重复着安装、崩溃、重装的过程,说实话有点枯燥无味,不过这个过程中熟悉了不少 linux 常用命令的使用。下图是以前折腾出来的一个 ubuntu 的 3D 效果,em... 当初搞这个纯粹是觉得酷炫,实际上没什么用。)
然后我表示为什么不用 Docker,比虚拟机方便多了,然后才得知,原来他觉得虚拟机也很方便,但实际上很多场景下跑个 Docker 容器比启动一个虚拟机方便多了。最后应对方要求,写一篇关于 Docker 入门的指南,也就有了本文。
本文旨在帮助大家建立起对 Docker 的一个整体印象,至于具体如何使用更多是需要自己去实践。毕竟 Docker 的内容太多了,但我们实际用到的内容其实只是它最核心的一部分。
先通过这个实际的例子来比较一下传统虚拟机跟 Docker 之间在使用上存在的时间差别吧。
Docker 启动一个 gerrit 有多简单
对于大部分开发者来说,可能需要做的只是使用,比如,gerrit,为了达到快速体验一项技术的目的,我们可以直接忽略掉运行环境的复杂性(当然,想卷起来也可以去自己搞懂整个部署流程,甚至去看看源代码什么的)。
而 Docker 就为我们提供了这一种便利,通过 Docker,我们通过一两个命令就能启动一些我们想要的软件,比如下面两个命令就可以直接启动一个 gerrit 服务器:
1 | docker pull gerritcodereview/gerrit |
虚拟机的方式有多麻烦
至此,我们两条命令就可以把一个 gerrit 服务器运行起来了,不需要先安装一个虚拟机软件,再在虚拟机里面装一个系统,然后再安装 gerrit 需要的依赖,然后再部署 gerrit。
我们可以通过下图对比一下:
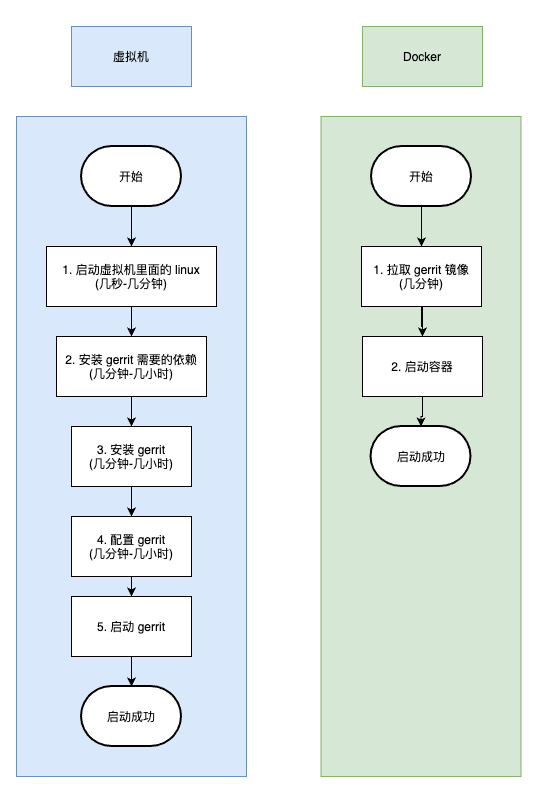
左边的第 5 步和右边的第 2 步是一样的。具体启动时间取决于应用本身。
我们可以明显看到通过虚拟机的方式我们需要做的步骤明显多了,而且其中每一步需要的时间都是一个未知数,如果对 linux 本身也不太熟悉,那这个过程可能就更长了。
相比之下,使用 Docker 的方式,我们只需要简单的两步就可以达到同样的目的。如果本身就不熟悉 linux,然后又要在真实的 linux 环境下部署一个,花的这些部署时间可能足够熟悉 gerrit 本身了。
Docker 是什么
我们可以从两个角度简单理解:
- 我们尽可以简单地把 Docker 看作是类似传统虚拟机一样地东西,本质上也是一种虚拟化的技术。但相比传统虚拟机,它更加轻量、使用更加便捷。
最直观的,我们可以直接从现有的镜像开始,构建我们的应用程序。而不用像传统虚拟机那样,自己先在虚拟机上安装一个操作系统,再去安装依赖,再安装我们真正需要的软件。
开始下文之前,让我们再来重新审视一下 Docker 的 logo 本身:
这个 logo 看上去像是一艘载着货物的船,Docker 本身就是这么运作的,通过启动一个 Docker 引擎,然后不同的容器可以运行在 Docker 引擎之上。
另外,我们开发的时候可以基于 Docker 容器提供的环境开发,我们开发完的应用可以打包成 Docker 镜像,然后传输到不同服务器上,而往往我们的应用是由多个依赖组成的(这些依赖也可以构建出一个个的镜像),然后再在服务器上通过我们传输的这一系列镜像启动不同的容器。
同时,Docker 引擎本身是不同平台都可用的,所以我们的应用并不依赖于实际的平台,只依赖于 Docker 引擎本身(实际上我们所需要的依赖都在不同的镜像里面包含了,并不是只有 Docker 引擎就够了)。
所以,我们可以有另外一个关于 Docker 是什么的描述:
- Docker 是一个用于开发、传送和运行应用程序的开放平台。Docker 使您能够将应用程序与基础设施分开,以便您可以快速交付软件。使用 Docker,您可以像管理应用程序一样管理基础设施。
Docker 跟虚拟机对比
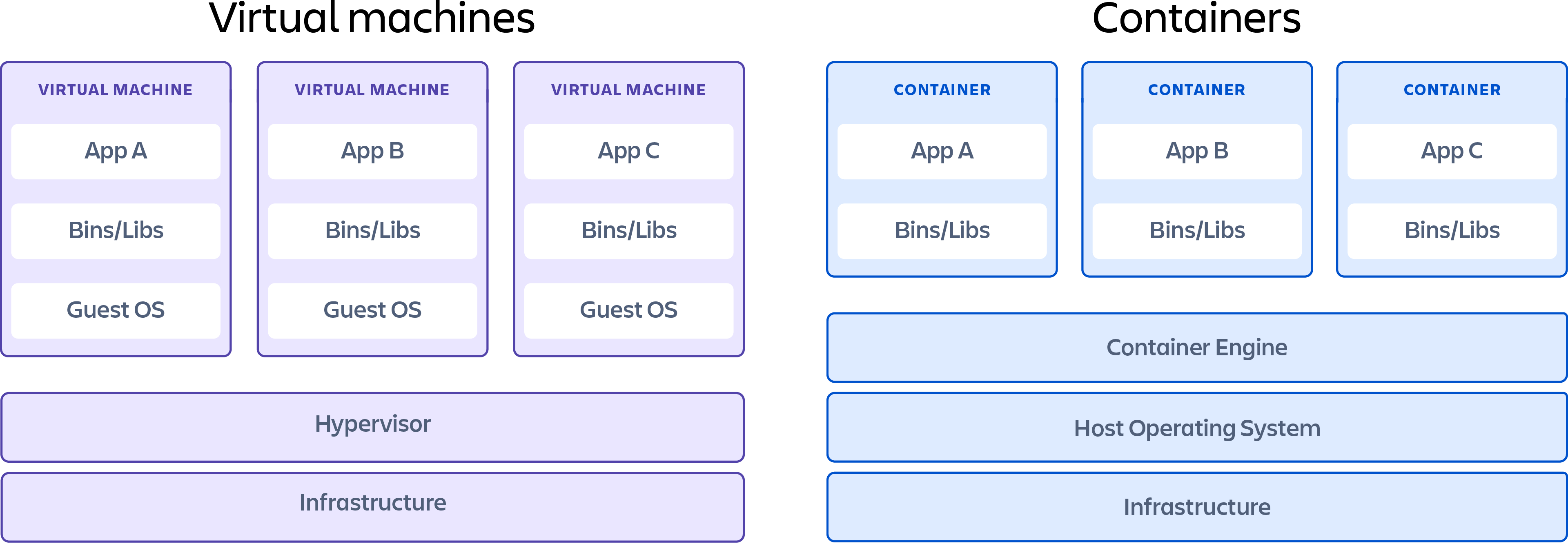
我们可以看到,传统虚拟机中,可能需要虚拟出多个不同的操作系统环境,才能实现在不同操作系统环境运行我们需要的软件。比如,我们一个应用依赖于 CentOS 环境,另外一个应用依赖于 Ubuntu 环境,我们就需要安装两个操作系统对应的虚拟机,这一步是非常耗时而麻烦的,而且,这个虚拟出来的操作系统环境也是很占资源的。
而在 Docker 里面,Docker 的容器引擎提供了我们容器所需的环境,而且所有的容器都是使用唯一一个容器引擎,相比较之下,传统虚拟机的方式显得有点笨重。
总的来说,Docker 相比传统虚拟机有以下优势:
- 使用 Docker 的情况下不需要为每一个容器虚拟出一个操作系统环境,而传统虚拟机的方式如果需要不同的操作系统环境支持,则必须要构建出不同的操作系统环境(就算我们这个虚拟机不运行其他任何东西,这个虚拟出来的操作系统就已经占用很多资源了)。
- Docker 启动一个容器所需要的资源非常小,比如一个 nginx 启动起来的容器可能就需要占用几 M 的内存。
- Docker 启动一个容器所需要的时间非常短,启动容器的过程可能只需要一瞬间,相比传统虚拟机启动一个虚拟操作系统快很多倍。
Docker 里面镜像跟容器是什么?
上面有两个反复提到的词,"镜像"、"容器",这两个是 Docker 里面核心的几个概念之一了,所以很有必要先解释一下。
我们理解镜像跟容器,可以对比一下程序和进程:
- 什么是程序,一个可以直接运行的二进制文件我们称它为程序,它本质上是一个文件。比如,redis 二进制文件(redis 安装目录里面 bin/redis 这个文件),这个就是一个程序。
- 什么是进程,我们运行程序的时候,操作系统会创建一个进程,这个进程里面做的事情就是我们预先在程序里面定义好的。比如,运行
bin/redis的时候,我们的计算机上就多了一个 redis 的进程。
有了程序跟进程的大概印象,再来理解一下镜像跟容器:
- 什么是镜像,镜像实际上也是一个静态的概念,实现上可能表现为磁盘上的一个文件或者多个文件的集合。
- 什么是容器,容器就是我们通过 Docker 引擎运行的一个镜像的实例。
我们可以从一个程序启动多个进程,同样的,我们也可以从一个镜像启动多个容器。所以,我们可以将镜像视作 Docker 里面的程序,将容器视作 Docker 里面的进程。
实际上,Docker 容器本质上就是一个进程,这个进程跟传统进程不一样的是,它依赖的东西由镜像提供,而不是操作系统提供(比如动态链接库这些)。所以 Docker 镜像的作用是为我们程序运行提供所需要的依赖。
Docker 架构
这里引用一下官网文档里面的架构图:
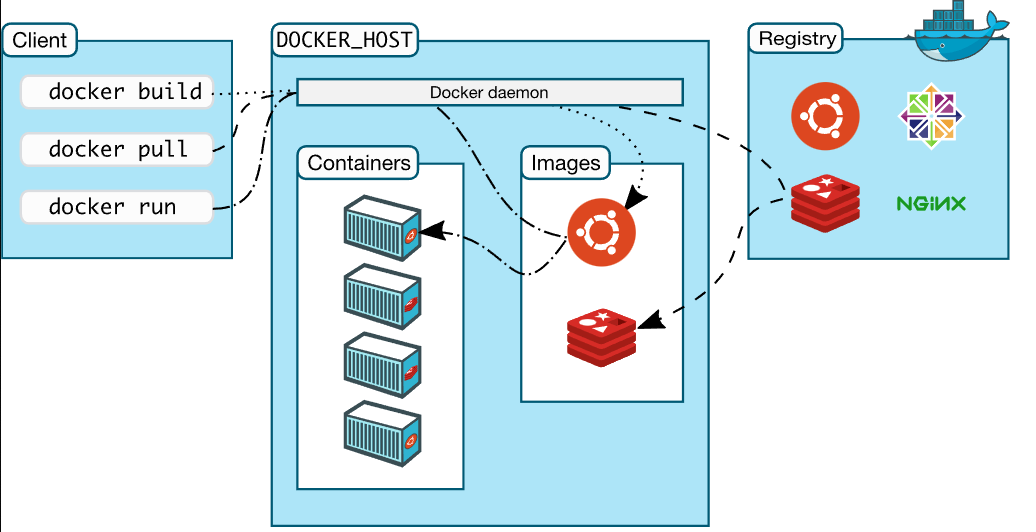
理解了这个图,我们实际上就已经掌握了 Docker 的核心。
我们可以通过上面的例子来讲述使用 Docker 的实际步骤:
安装配置 Docker,启动 Docker。这一步没啥好说的
拉取 gerrit 镜像。
这一步我们会从 register 获取 gerrit
镜像文件,拉取的过程就是,我们在命令行上运行
docker pull gerritcodereview/gerrit
的过程,这个过程会做以下事情:我们的命令会发送给 Docker
引擎(也就是图上中间的 Docker daemon),Docker 引擎会从 register 下载
gerritcodereview/gerrit 这个镜像文件到本地,最后退出
- 启动 gerrit 容器。(这一步我们会从 Docker 的 gerrit 镜像启动一个 gerrit 容器)
这一步我们通过运行
docker run -ti -p 8080:8080 -p 29418:29418 gerritcodereview/gerrit
实现,这个过程,Docker
引擎会启动一个新的进程,这个进程里面运行的就是我们镜像指定的程序(这个下面细说,现在需要记住,一个容器本质上就是一个进程)。
好了,现在我们对于 Docker 的运行机制有了一个大概的印象了,接下来可以详细说说这个图:
Client
- 这个是指我们运行命令的工具,最常见的就是 shell,比如:
1 | docker pull redis |
这里,我们的终端(windows 下是 cmd 窗口,macos 是 terminal 窗口)就是一个 client。
- 当然也可以是其他自己实现或者第三方实现的,因为 Docker 还可以通过 rest api 的方式来操作。所以只要可以向 Docker 引擎发起 HTTP 请求,都可以视作是一个 Client。
DOCKER_HOST
这是 Docker 的核心部分,我们的 Docker 引擎位于这一部分,这里面也细分为三个主要部分:Docker daemon、Containers、Images。
Docker daemon
这个在实际使用中就是一个 dockerd 进程,就是一个 Docker
的守护进程。它的作用是,监听客户端的请求(比如我们运行
docker run 的时候就是向 Docker daemon
发起了一个请求),同时管理 Docker
里面的所有其他东西,比如容器、镜像、网络、卷等。
Containers
这一块就是一堆的容器,每一个容器本质上就是一个进程。(当然实际使用中,一个容器可能是有多个关联的进程的,比如它的子进程)
Images
这一块就是一堆的镜像,本质上是一堆的静态文件的集合。
Registry
Registry 就是存储 Docker 镜像的地方。类似 github,只不过上面保存的是 Docker 镜像,同样我们也可以上传自己的镜像上去。
一般来说我们都是使用 Docker 官方的 Registry,我们也可以搭建自己私有的 registry,用来存储一些不想对外公开的 Docker 镜像。
Docker 工作流程
我们来看看一个带了序号标记的 Docker 架构图:
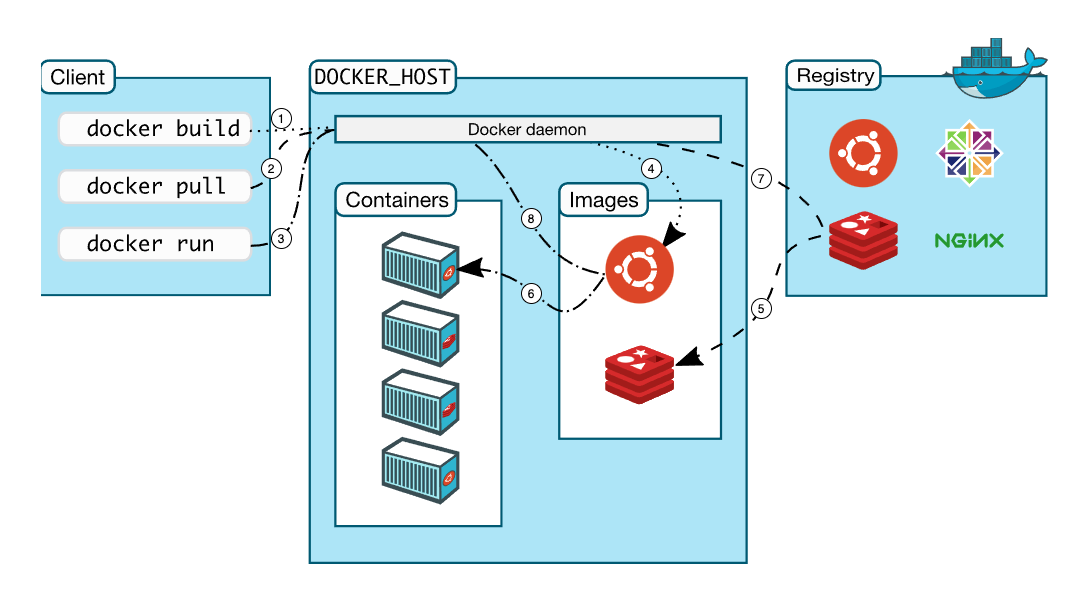
上面也说了,理解了 Docker 的架构图,也就掌握了 Docker 的核心。所以这里详细说一下它的核心工作流程:
- 1+4:运行
docker build的时候,Docker daemon 会根据我们定义的 Dockerfile 文件来生成一个镜像文件,这个镜像文件保存到本机(4)。
这一步的作用是构建我们自己的镜像,最常见的应用场景是,软件官方提供的镜像不能够满足我们的需要,我们需要在官方提供的镜像的基础上,做一些自己的改动,比如添加一些我们所需要的依赖(比如,往 php 镜像里面加几个扩展)。
- 2+7+5:运行
docker pull的时候,Docker daemon 会根据我们在后面传递的参数,从 Registry 上面下载对应的镜像文件,7 是向 Registry 服务器发起请求,5 是 Registry 服务器响应请求,最终的结果就是,我们本地的镜像里面多了一个镜像。
这一步的作用是拉取我们所需要的镜像,不管是不是我们自己构建的镜像,都会发生这一步。如果我们是从别人提供的镜像上构建一个新的镜像,我们运行
docker build 构建属于我们自己的镜像的时候,就会从 Registry
拉取基础镜像。
如,docker pull redis,这个命令会从 Registry 下载 redis
最新的镜像文件,然后保存到本地。这个命令也可以指定版本,如
docker pull redis:5 这个命令下载 tag 为 5 的 redis
镜像。至于有哪些 tag 可以用,我们可以在官网的 Registry
上面搜索一下。
- 3+8+6(可能会发生 7+5 这两步操作):运行
docker run的时候,Docker daemon 会根据参数从本地的镜像列表获取对应的镜像(7),然后从这个镜像启动一个容器(6)。如果本地没有这个镜像,会从 Docker Registry 先拉取这个镜像(跟上一点说到的流程一致)。
这一步的作用就是我们实际所需要的,它会从镜像启动一个新的容器。
如,docker run redis,这个命令会看本地有没有
redis:latest 这个镜像(tag 省略的话,默认是
latest),有的话,直接从这个镜像启动一个容器,如果本地没有这个镜像,则会先从
Registry 上下载这个镜像,然后再启动容器。
再捋一捋 Docker 里面的几个核心概念
- Docker daemon
这个是 Docker 的守护进程,如果我们想使用 Docker 的话,首先得把 Docker 启动起来是吧,我们启动起来的那个进程就是 Docker daemon。
- 镜像(Image)
官方描述:一个 Docker 镜像就是创建 Docker 容器的只读模板。通俗地说,镜像就是一个我们程序的运行环境,当然你也可以将自己的程序也放进镜像里面。
- 容器(Container)
官方描述:一个 Docker 容器就是一个 Docker 镜像的实例。本质上就是,一个进程,而这个进程所需要的依赖由镜像提供。
- Registry
保存镜像的地方。我们一般是使用官方提供的,也可以搭建自己的 Registry 用来保存一些私有镜像,或者为了达到加速拉取镜像的目的。
容器本质上是一个进程
上一小节说了,镜像就一个我们程序的运行环境。虽然我们用了程序跟进程的概念来做比较,但本质上,一个 Docker 镜像只是为我们程序运行提供环境。而我们的容器,实际上是我们在这个容器里面执行某个程序产生的进程。
比如,我现在有一段 nodejs 文件:
test.js,位于目录 /Users/ruby 下
1 | const fs = require('fs') |
但是我本机没有安装 nodejs,现在想通过 Docker 来执行我们这段代码,具体需要怎么做呢?
- 拉取 node 镜像
1 | docker pull node |
- 从 node 镜像创建一个容器来运行我们这个文件
1 | docker run -v /Users/ruby/test.js:/test.js node node /test.js |
这个命令怎么理解
这个命令很长,所以画了个图来更直观地阐释一下:
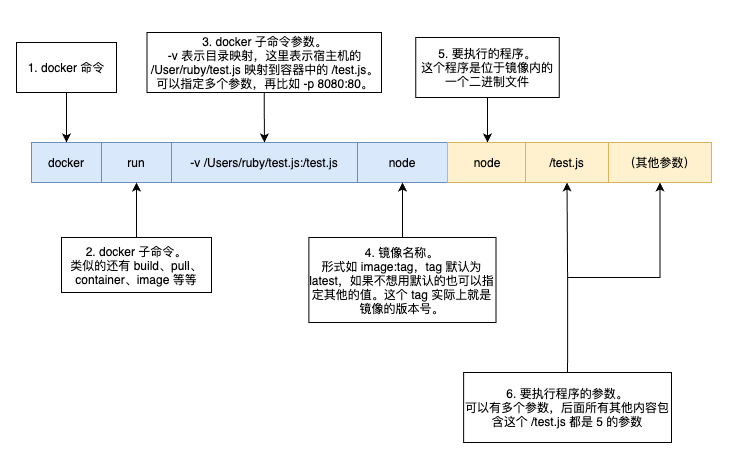
这个图里面的命令有两种颜色区分开两种不同含义的内容:
第一部分表示是 Docker 相关的命令以及参数,而第二部分就是我们的程序名称以及传递给我们程序的参数。
需要注意的地方是:
- Docker 里面针对不同的内容有不同的二级命令,比如管理镜像是
docker image,管理 Docker 网络是docker network。 - 图中的 3 是一系列的选项以及参数,当然这部分是可以省略的,如果我们的确不需要什么参数。
- 图中的 4 是镜像的名称,表示我们基于哪个镜像提供的运行环境来运行 5
那个程序。比如,我们想用一个 12.0.0 的版本来运行我们的程序,我们就可以
docker run -v /Users/ruby/test.js:/test.js node:12.0.0 node /test.js。(需要特别注意的是,这里的 4 跟 5 看起来一样,但本质上是完全不同的) - 5 以及后面那部分,也是一个命令以及参数,只不过这个命令是运行在 4
这个镜像提供的运行环境上的,而不是在我们的宿主机上运行的。另外,第 6
那个
/test.js以及后面接的所有其他内容,都是传递给容器里面的 node 程序的参数。
为什么说容器是一个进程
经过上面对于命令图解,我们也看到了,实际上到最后,我们运行的命令是
node /test.js,而我所说的 "容器是一个进程"
说的就是这个,我们启动容器最后的步骤其实就是运行我们指定的程序。
只不过相比较于我们直接在宿主机上运行
node /test.js,通过容器的方式我们使用的是 Docker
镜像提供的运行环境。如果我们想在宿主机上运行,我们就需要在宿主机上安装
node 的运行环境。
为什么执行命令之后就容器就退出了
我们执行了上面那个 docker run
命令之后,输出了一些东西然后就退出了,可能有很多初学者会觉得很奇怪,为什么退容器也出了。这也跟上面说的容器是一个进程本质上是同一个问题,进程都是做完它应该做的事情就退出了的,把容器看作进程就很容易理解了。
上面这个也一样,在容器里面执行完 node /test.js
的时候,node
的工作就已经完成了,所以进程就退出了。具体表现就是,我们的容器也停止了。
如何指定容器要执行的程序
- 如果是通过 Dockerfile 来构建的镜像,可以在 Dockerfile
里面最后一行通过
RUN指令来指定。 - 如果使用 docker-compose,则可以在 docker-compose 里面通过 command 或者 entrypoint 来指定。
- 可以在
docker run命令的镜像名称参数后面指定(上图的 5)。
启发
我们在使用 Docker
的过程中,尽管可以把容器理解为一个进程,我们需要什么样的依赖,就通过
Docker 来启动一个容器(进程)。比如,我们想使用 redis,就可以通过
docker run 来启动一个 redis 进程(redis 容器)。
这样看来,其实 Docker 也没有什么神秘的地方了,我们使用起来也不会有太多的心智负担。
如何开始使用 Docker
花了很大的篇幅来讲 Docker 的架构,现在基于它的架构回到最初的例子来解释一下如何开始使用 Docker。
目标:启动一个 gerrit 服务器。
详细步骤:
- 上面说了,镜像提供了我们所需运行的进程的环境。所以这一步我们需要先拉取 gerrit 对应的镜像。
所有我们能想到的常用的软件基本上都有现成的镜像,具体可以在 hub.docker.com 上面搜索一下,我们在上面搜索一下 "gerrit":
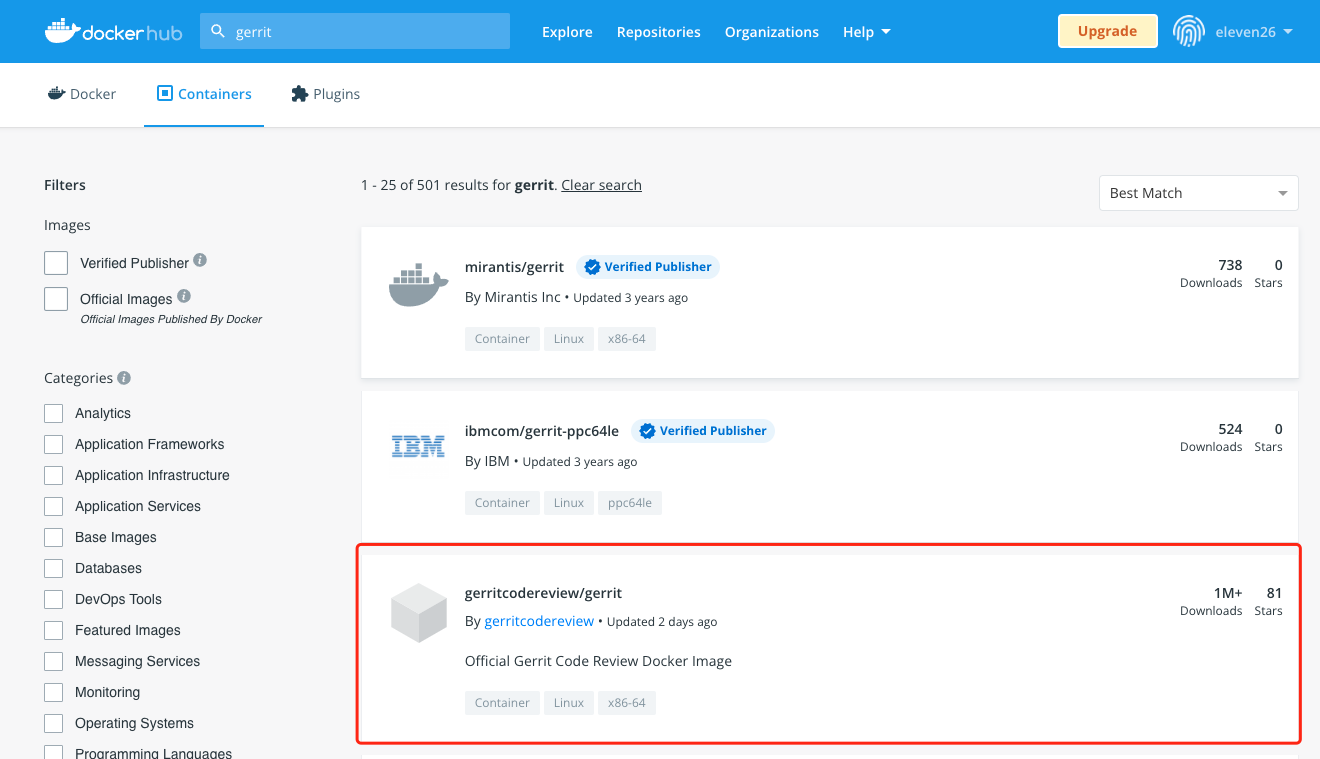
我们这里需要注意一下,有一些名字一样的,但不是官方提供的,我们可以看一下右上角有多少下载就可以知道哪些是官方提供的了。当然这个图上面官方镜像说明那里也明说了,"Official Gerrit Code Review Docker image"。
我们点击进去看看,右边的 "Docker Pull Command" 就我们拉取这个镜像的命令,点击一下红框部分就可以复制这个命令了:
复制之后,在命令行运行这个命令:
1 | docker pull gerritcodereview/gerrit |
成功运行这个命令之后,我们本地就有了
gerritcodereview/gerrit 这个镜像了。我们可以通过
docker images 列出我们目前的镜像列表:
1 | docker images |
输出:
1 | REPOSITORY TAG IMAGE ID CREATED SIZE |
- 上面也说了,容器就是基于镜像启动的一个进程。所以这一步我们需要做的是,通过我们下载的
gerritcodereview/gerrit镜像来启动一个容器。
这一步也很简单,docker run
然后再指定一个镜像名称就行了:
1 | docker run -ti -p 8080:8080 -p 29418:29418 gerritcodereview/gerrit |
不出以外的话,过一会应该可以看到如下输出:
1 | [2021-10-25T07:21:58.234Z] [main] INFO org.eclipse.jetty.server.handler.ContextHandler : Started o.e.j.s.ServletContextHandler@174e79f9{/,null,AVAILABLE} |
这里的日志可以看出我们的服务器正常启动了,再通过浏览器访问
http://localhost:8080 就可以访问 gerrit 了。
这里的
-it可以在启动之后直接在前台运行,-p指定端口映射,可以指定多个。
到此为止,我们的目的就已经达到了。重要的步骤就这两步了。
什么时候使用 Docker
- 想使用某个软件,但是又不想在自己的电脑上安装太多东西。(这也是很多人使用 Docker 的原因)
- 只是想体验一下某项技术(比如,PHP8 出来了,想体验一下语言的新特性),这种情况下,我们的目的很单纯,就是想用一用这项技术(如果只是为了验证一行代码而花了大量时间在环境搭建上就本末倒置了)。我们都知道在宿主机上安装一个 PHP 并且跑起来是一件非常费劲的事,有那个时间都够在容器里面把新特性跑个遍了。
- 团队统一环境。在以前,很多人会采用虚拟机的方式,但是 Docker 比传统虚拟机的方式不止方便一点点。
- 生产环境部署使用,Docker 相比以往的部署方式,直接屏蔽了不同平台的差异,只要 Docker 能安装,容器一般也就能跑,所以部署成本低了很多。同时也可以限制每个容器所能使用的资源,防止某个进程占用资源过多对整个服务器造成影响。另外,配合 k8s 也可以很方便对这些 Docker 容器进行管理。
总结
- Docker 本质上也是一种虚拟化技术,但是相比传统虚拟机,不需要每一个容器都创建一个操作系统环境,所有的容器都依赖于 Docker 引擎。
- Docker 镜像是我们程序的运行环境。
- Docker 容器本质上是在镜像提供的环境上运行的一个进程。
- Docker daemon 是 Docker 用以管理镜像、容器等东西的一个守护进程。
- Docker Registry 是我们拉取镜像的地方,当然我们也可以将我们自己构建的镜像上传到 Registry。(可以理解为镜像的托管平台,类似于 github 跟开源项目的关系。)
- Docker 容器执行的程序,在进程终止的时候,容器也会停止运行。
后记
很遗憾,本文不是一个速成的指南,也没有说到什么 Docker 命令的实际使用,也没有介绍什么 Docker 相关工具的使用(比如 docker-compose),毕竟说了也没什么用,大家也记不住,最终使用的时候还是会去搜索对应的命令是什么。不过相对完整地向读者展现了 Docker 的架构以及一个整体的运作流程,足以帮助读者建立起对 Docker 的基本印象了。
至于其他的东西,比如 docker run
后面有哪些选项、又或者怎么构建自己的镜像、怎么使用 docker-compose
等等这些其实开始使用的时候不需要了解太多,在真正需要用到的时候搜索一下就行了,我们的记忆力毕竟是有限的,而且记住太多东西也不一定会帮助我们去更好地使用。
反而,虽然我们只是花了少量时间去建立起了对 Docker 的一个整体印象,但是对于实际使用中遇到的百分之八九十的问题,我们都可以回到这个整体印象中来,去思考是哪个环节出的问题。也就是说,我们的思考有了一个抓手,就算问题出现了,我们也可以根据现象跟这个整体印象建立联系,从而找到解决问题的方向,而不是迷失在纷繁芜杂的细节中。