一个简单的协程实现
接上一篇,又经历了几天的探索,在昨天解决了一个关键的问题之后(引用了一个被销毁的栈变量导致 SIGSEGV),也没有太多很困难的地方了。然后就先完成了一个 C 版本的协程,再根据 C 的版本完成了 C++ 版本的开发。
从一个月前到现在,在象牙塔里面待久了,是时候回归一下现实了。目前的实现只是实现了简单的协程调度,不过总的来说,最初的目的已经达到了(了解协程实现的原理),所以这个课题到此先告一段落了,该忙一忙别的事情去了。
本文会先从协程的概念说起,然后聊聊其优势,然后再谈具体实现。
协程是什么
我们可以通过跟进程进行一个简单的比较来理解协程是什么。
- 基本概念
如果说进程是一个运行中的程序,那么协程就可以看作是进程内一个运行中的子程序(em...你可以简单理解为函数)。计算机可以同时运行多个进程,而在一个进程内,同样可以运行多个协程。
- 运行状态
我们的进程会有几种状态:运行、阻塞等,当进程阻塞的时候,操作系统会切换另外一个不阻塞的进程来运行。同样协程也可以有不同的状态,当我们在一个协程内因为某些原因不能继续执行下去的时候,可以将当前运行的协程标记为类似 “阻塞” 的状态,然后通过自己实现的一个调度器来切换到另外一个协程来执行。
- 终止
进程的终止会导致进程退出,而协程退出的时候,我们可以自行决定接下来是执行另外一个协程还是直接退出进程(也就是说,是由我们自己决定的)。
通过这简单的几点比较,我们可以得出关于协程的几个关键点: 1. 我们可以在进程内并发运行多个协程。 2. 协程的调度是我们自己实现的(相对进程的调度由操作系统实现,实际使用中都是封装好的,并不需要开发者自行实现)。 3. 一个进程的生命周期里面,可能可能会经历多个协程的生命周期。
协程的优势
正如上面说的,进程有阻塞的状态,进程阻塞的时候,操作系统会调度另外一个就绪的进程来运行。那如果我们的进程内需要进行多个阻塞的操作,那我们这个进程的很多时间就浪费在等待阻塞操作返回上了。为了应对这种情况,unix 下有一套非阻塞的 io 操作,我们可以使用 select、poll、epoll 等来同时监听多个文件句柄的状态,当某一个文件句柄可读或者可写的时候,我们就处理跟这个文件句柄相关的操作。而当当前正在处理的文件句柄因为某些条件而不能继续进行下去的时候,就继续看有没有其他就绪的文件句柄,有则拿出来处理。
而协程可以将这个过程封装一下,每个协程用来关联一个或者文件句柄,当对应的文件句柄就绪的时候,就将进程的上下文切换为对应协程的上下文,这样一来,我们就不需要等待一个阻塞操作执行完之后再去执行下一个阻塞操作,现在这些阻塞操作是并发发生的了。
讲个简单的例子,比如,我们的进程里面需要发送两个消息给服务器 server 并且等待 server 返回(假设一个来回要 1s),而这两个消息 A 和 B 是没有顺序要求的,按以往阻塞的做法,我们需要先将 A 发出去,等待返回,这个过程耗时 1s,然后再将 B 发出去,等待返回,又耗时 1s,整个过程我们就需要花费 2s。
而如果我们在将 A 发出去之后,将进程上下文切换到 B,将 B 也发出去,然后同时等待 A 跟 B 结果的返回,最终返回的时候,我们实际上只需要等待大约 1s,这样我们就节省了 50% 的时间。
这也是协程的一个典型用途,io 阻塞的时候切换到另一个协程,从而节省整个进程在 io 上的等待时间。
协程实现的核心
如前面所说,我们的协程是一个进程内可以有多个协程,而且可以在不同的协程之间进行切换。进程的切换的时候,本质上是不同进程上下文换入换出 CPU 的过程,同样的,协程的切换也是不同的上下文换入换出 CPU 的过程。
但与进程不一样的时候,协程相关的上下文是用户态的上下文,而不是内核态的上下文。
协程调度的核心,或者说本质就是,在进程中实现不同用户态上下文的切换。
底层核心实现都是汇编实现的(因为只有汇编可以直接操作寄存器和堆栈),切换的时候,会将当前寄存器以及堆栈指针等记录下来,将另外一个上下文相关的寄存器以及堆栈指针等还原。
具体实现
总的来说,实现一个协程需要解决以下一些问题: 1. 如何区分协程环境跟非协程环境?因为协程环境下可以使用 yield 来主动让出 CPU 使用权 2. 一个协程需要包含什么信息? 3. 如何创建一个协程? 4. 如何实现协程的切换? 5. 协程退出的话,怎么在下一次调度的时候不再调度这一个已经结束的协程?
问题1,无需进行协程切换的时候,我们的代码依然是以往的执行流程,该阻塞的时候,整个进程阻塞。所以为了区分开这两种情况,我们在执行协程之前,先构建一个协程的上下文,在这个上下文里面来执行我们的协程,然后当有协程产生阻塞操作的时候,在这个上下文里面切换到另一个就绪的协程来执行。
下面的代码创建了一个调度器,然后往里面加入不同的协程,最后,协程调度器开始执行,这个时候就切换到了协程环境的上下文了。
1 | // 创建调度器 |
问题2,我们在看操作系统相关的书籍或者教材啥的可能会了解到,操作系统在进行进程切换的时候,实际上这种操作准确地说是上下文切换,从一个进程的上下文切换到另外一个进程的上下文(上下文包含了当前的寄存器信息,堆栈信息等)。
对于协程来说,如果我们想实现协程切换,我们同样需要在切换的时候保留当前协程的上下文,以便在后续可以恢复到当前这个上下文。保存完当前上下文之后,将上下文切换为另外一个就绪的协程的上下文即可运行另外一个协程了。
而协程上下文,我们可以使用 ucontext_t
来保存,这是一个用户态的上下文结构体。同时为了标识不同的协程,我们可以给每一个协程一个自增
id,所以协程的数据结构定义如下:
1 | class coroutine { |
问题3,从上一个问题我们知道了我们需要一个 ucontext_t
类型的变量来存储上下文相关的信息,而这个变量的初始化我们可以使用 linux
下提供的 getcontext 和 makecontext
来实现。
1 | auto *c = new coroutine; |
问题4,在协程 yield
的时候,我们做了一个操作,实现从协程上下文切换到调度器的上下文,使用
swapcontext 函数实现:
1 | swapcontext(s->current.ctx, &s->ctx); |
但是我们要的效果是,从一个阻塞的协程切换到另外一个就绪的协程,我们只是切换回调度器的上下文是还不够的,但是我们的调度器是可以知道哪些协程是就绪的,所以真正切换到另外一个协程的操作我们是在调度器里面实现的:
下面这个函数只是做了一个简单的遍历,但实际使用中的协程应该还有一个状态来标识是否就绪,协程就绪的时候才切换到对应的上下文,否则我们切换过去什么也做不了。
1 | void scheduler::run() { |
问题5,在我们创建上下文的时候,是可以指定一个协程退出后要使用的上下文的,在我目前的实现里,指向了另外一个上下文,在那个上下文里面执行了下面这个函数:
1 | void done() |
这里主要做了两个操作,一个是从调度器移除这个协程,这样在下次调度的时候就不会再调度到这个已经结束的协程了,另外一个操作是切换回到调度器的上下文,这样调度器可以继续调度那些未完成的协程。
简单使用及调度流程
main.cpp
1 |
|
输出
1 | routine2 running, co: 1 |
下面是整个程序的执行流程,里面使用了不同颜色标注了不同的上下文:
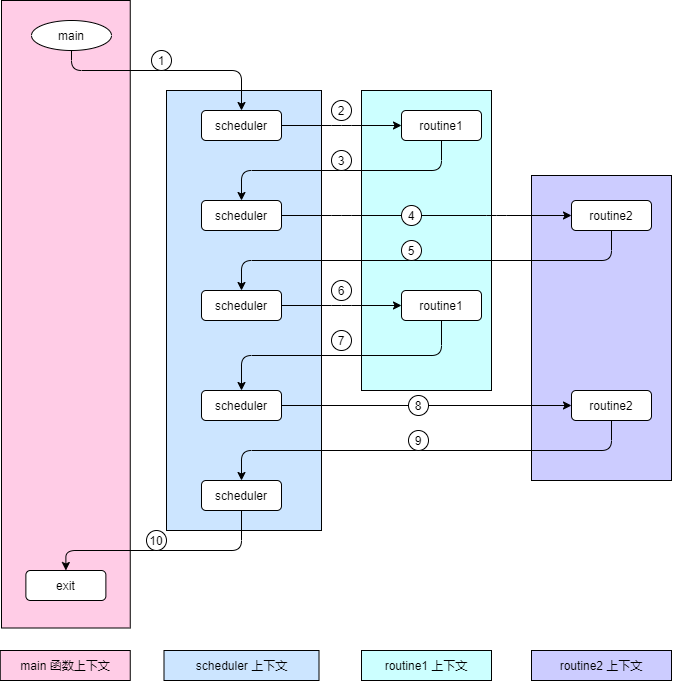
这里可能会比较有序,因为我们的协程没有任何状态标识,所以只是按顺序调度了一遍。
调度器相关完整代码
下面的实现存在的问题: 1. scheduler 是一个全局变量,在使用上存在较大问题 2. 每一个协程都关联了一个退出协程的上下文,这种开销似乎有点不必要 3. 协程里面缺少状态,而这个状态跟实际使用场景相关,应该是在实际使用中必要的
1 |
|
全部代码见:https://github.com/eleven26/cpp-coroutine
刚刚看了一下 swoole 的协程实现,使用的是 C++ boost
库里面的 jump_fcontext,而这个 jump_fcontext
是汇编实现。也有使用到了
swapcontext相关的几个函数,具体使用哪个是根据不同编译环境决定的。
但核心要解决的问题都是:如何在不同的用户态上下文之间切换。
后记
这个实现算是一个比较粗糙的实现,不过也实现了一个简单的封装,但距离生产可用的协程实现还差亿点点。从上面也可以看出,其中需要考量的问题其实并不少,但是对于协程的探索到此先告一段落吧。