if ($this->connection->logging()) { // Once we have run the query we will calculate the time that it took to run and // then log the query, bindings, and execution time so we will report them on // the event that the developer needs them. We'll log time in milliseconds. $time = $this->connection->getElapsedTime($start);
$query = [];
// Convert the query parameters to a json string. array_walk_recursive($parameters, function (&$item, $key) { if ($item instanceof ObjectID) { $item = (string) $item; } });
// Convert the query parameters to a json string. foreach ($parameters as $parameter) { try { $query[] = json_encode($parameter); } catch (Exception $e) { $query[] = '{...}'; } }
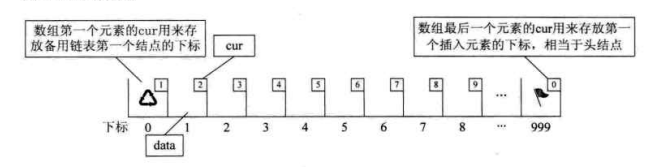
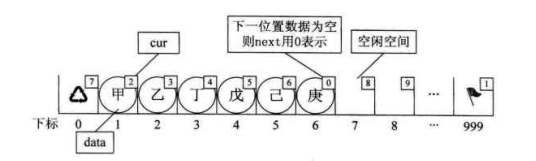
另外我们对数组第一个和最后一个元素作为特殊元素处理,不存数据。我们通常把未被使用的数组元素称为备用链表。而数组第一个元素,即下标为
0 的元素的 cur 就存放备用链表的第一个节点的下标;而数组的最后一个元素的
cur 则存放第一个有数值的元素的下标,
相当于单链表中的头节点作用,当整个链表为空时,则为 0。
// 若备用空间链表非空,则返回分配的节点下标,否则返回 0 int Malloc_SLL(StaticLinkList space) { int i = space[0].cur; // 当前数组第一个元素的 cur 存的值,就是要返回的第一个备用空闲的下标 if (space[0].cur) space[0].cur = space[i].cur; // 由于要拿出一个分量来使用了,所以我们就得把它的下一个分量用来做备用 return i; }
这段代码有意思,一方面它的作用就是返回一个下标值,这个值就是数组头元素的
cur 存的第一个空闲的下标。从上面的图来看,其实就是 7。
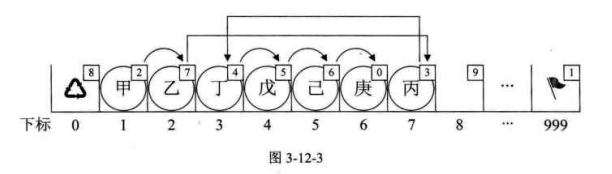
新元素 "丙",想插队是吧?可以,你先悄悄地在队伍最后一排第 7
个游标位置待着,我一会就能帮你搞定。我接着找到了 "乙",告诉它,你的 cur
不是游标 为 3 的 "丁" 了,你把你的下一位的游标改为 7
就可以了。此时再回到 "丙" 那里,说你把你的 cur 改为 3。
就这样,在绝大多数人都不知道的情况下,整个排队的次序发生了改变。
步骤: * 判断下标合法性 * 获取空闲节点的下标 * 写入数据到空闲节点 *
将上面空闲节点的 cur 修改为原 i 位置的 cur * 将写入位置前一个节点的 cur
修改为新节点所在位置
实现代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
// 在 L 中第 i 个元素之前插入新的数据元素 e Status ListInsert(StaticLinkList L, int i, ElemType e) { int j, k, l; k = MAX_SIZE - 1; // 注意 k 首先是最后一个元素的下标 if (i < 1 || i > ListLength(L) + 1) return ERROR; j = Malloc_SLL(L); // 获得空闲分量的下标 if (j) { L[j].data = e; // 将数据赋值给此分量的 data for (l = 1; l < i - 1; l++) // 找到第 i 个元素之前的位置 k = L[k].cur; L[j].cur = L[k].cur; // 把第 i 个元素之前的 cur 赋值给新元素的 cur L[k].cur = j; // 把新元素的下标赋值给第 i 个元素之前元素的 cur return OK; } return ERROR; }
当我们执行插入语句时,我们的目的是要在 "乙" 和 "丁" 之间插入
"丙"。调用代码时,输入 i 值为 3。
// 删除在 L 中第 i 个数据元素 e Status ListDelete(StaticLinkList L, int i) { int j, k; if (i < 1 || i > ListLength(L)) return ERROR; k = MAX_SIZE - 1; for (j = 0; j <= i - 1; j++) { // 找到第 i 个元素之前的位置 k = L[k].cur; } j = L[k].cur; L[k].cur = L[j].cur; Free_SLL(L, j); return OK; }
// 初始条件:静态链表 L 已存在。操作结果是:返回 L 中数据元素个数 int ListLength(StaticLinkList L) { int j = 0; int i = L[MAXSIZE - 1].cur; while(i) { i = L[i].cur; j++; } return j; }