最近在项目中发现有个接口需要耗时几分钟才能完成,排查发现跟以往的慢请求不大一样,这次的慢请求中,并没有慢查询(不管是
MySQL、MongoDB 还是
Redis、HTTP),经过排查发现其中有一个函数处理时间非常长,整个请求的 99%
的时间都花在了这个函数上:
1 2 3 4 5 6 foreach ($rules as $rule ) { if (empty ($this ->hasAllCustomerUserIds[$rule ->user_id])) { $this ->matchRule ($rule , $results ); } }
上面这个循环有 600+ 次,但是循环内的
matchRule 有 11w+
个循环,也就是说,总循环次数达到了 6000w+ 次。
这样一来,就算我们没有慢查询,某些性能不高的点累积起来也会导致整个请求耗时非常漫长,以至最终耗时达到了
7 分钟。
根本原因
在这 6000w+
的循环里面,完全没有太复杂的操作,更没有什么查询之类的操作,但是由于内层循环都是操作了
ORM 模型,有比较多的获取 ORM 模型属性的操作。
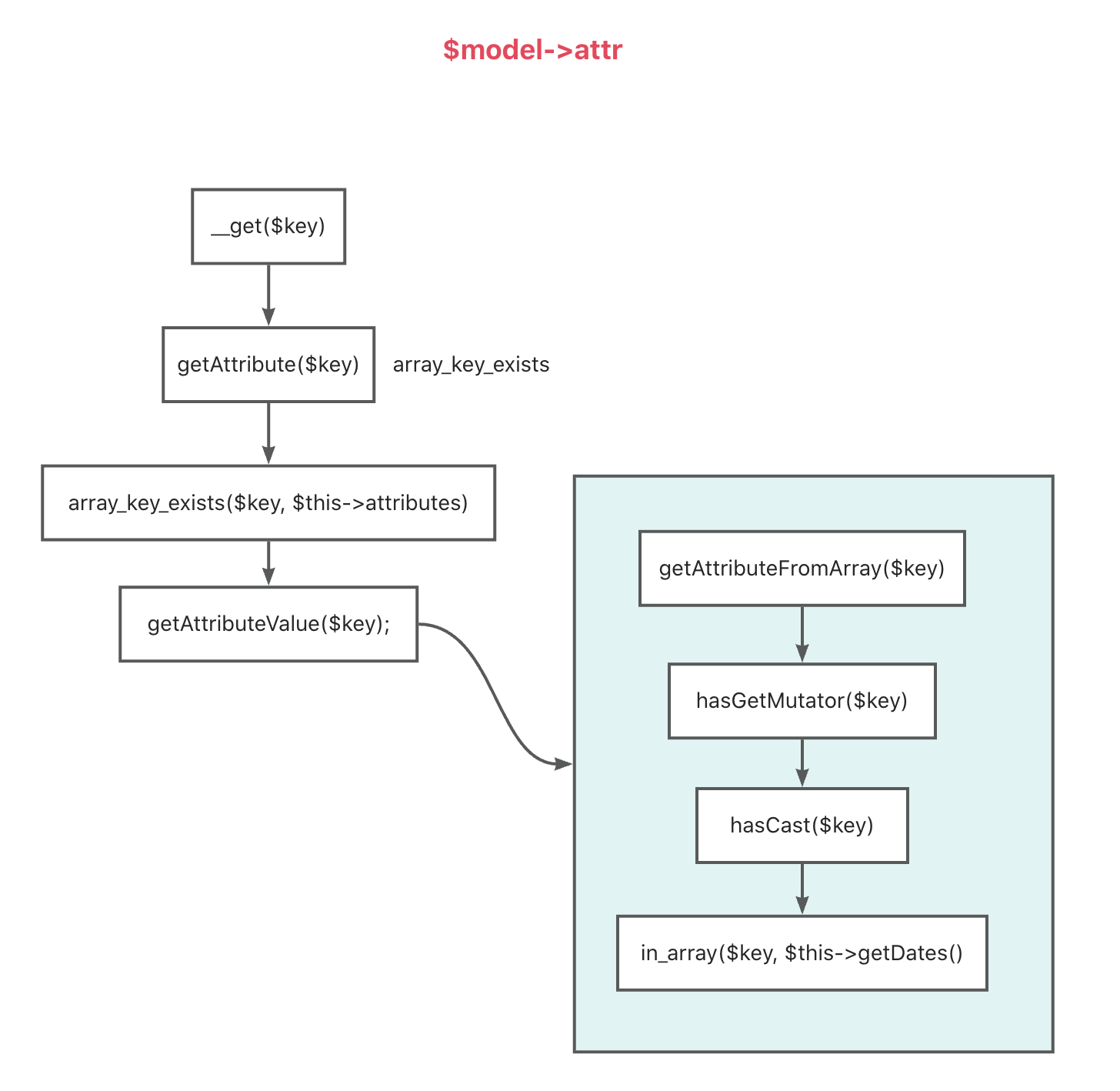
而 Laravel 的 ORM 模型中获取属性是通过魔术方法
__get() 实现的,而这个 __get()
中有一个时间复杂度比较高的操作
getAttribute(),所以这里会有一定的性能问题:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 public function __get ($key return $this ->getAttribute ($key ); } public function getAttribute ($key if (! $key ) { return ; } if (array_key_exists ($key , $this ->attributes) || $this ->hasGetMutator ($key )) { return $this ->getAttributeValue ($key ); } if (method_exists (self ::class , $key )) { return ; } return $this ->getRelationValue ($key ); }
这里只贴 __get() 和 getAttribute()
方法,但是我们也能看到了,虽然我们只是做了一个简单的获取模型属性的操作,但底层涉及了很多的方法调用。
在这种情况下,虽然在代码中已经做了一些查询上的优化,但是这个计算规模下,对
Laravel ORM 模型的操作带来的性能问题会非常显著。
因为模型中使用 $model->attribute
这种方式来获取它的属性的时候,时间复杂度会很高(相比于普通的对象属性),下面是一个性能测试:
100w 次模型访问属性操作
1 2 3 4 5 6 7 8 9 10 11 12 13 class Foo extends \Illuminate \Database \Eloquent \Model } $start = microtime (true );$model = new Foo ;$model ->a = 1 ;for ($i = 0 ; $i < 1000000 ; $i ++) { $model ->a; } dump (bcsub (microtime (true ), $start , 4 ));
最终耗时 789.6ms
100w 次普通对象获取属性操作
1 2 3 4 5 6 7 8 9 10 11 12 13 class Bar } $bar = new Bar ;$bar ->a = 1 ;$start = microtime (true );for ($i = 0 ; $i < 1000000 ; $i ++) { $bar ->a; } dump (bcsub (microtime (true ), $start , 4 ));
最终耗时 14ms
也就是说,两者在 100w 的计算规模下,性能差距相差了
56.4 倍。
56.4 倍在数据规模小的时候,我们通常无法感知,比如
10ms,再乘以 56.4 也就是
564,这也还是一个可以接受的时间。
但是在数据规模较大的时候,原本只需要 1s
的操作,可能就得需要 56s 了,这就是非常明显的。
ORM 模型的属性访问做了什么?
首选我们需要知道的是,我们定义的模型中,并没有定义显式地定义任何
public 属性,对于这种情况,我们访问它的属性的时候,php
会去调用对象的 __get 方法。那就顺着模型的
__get 方法看看它做了什么:
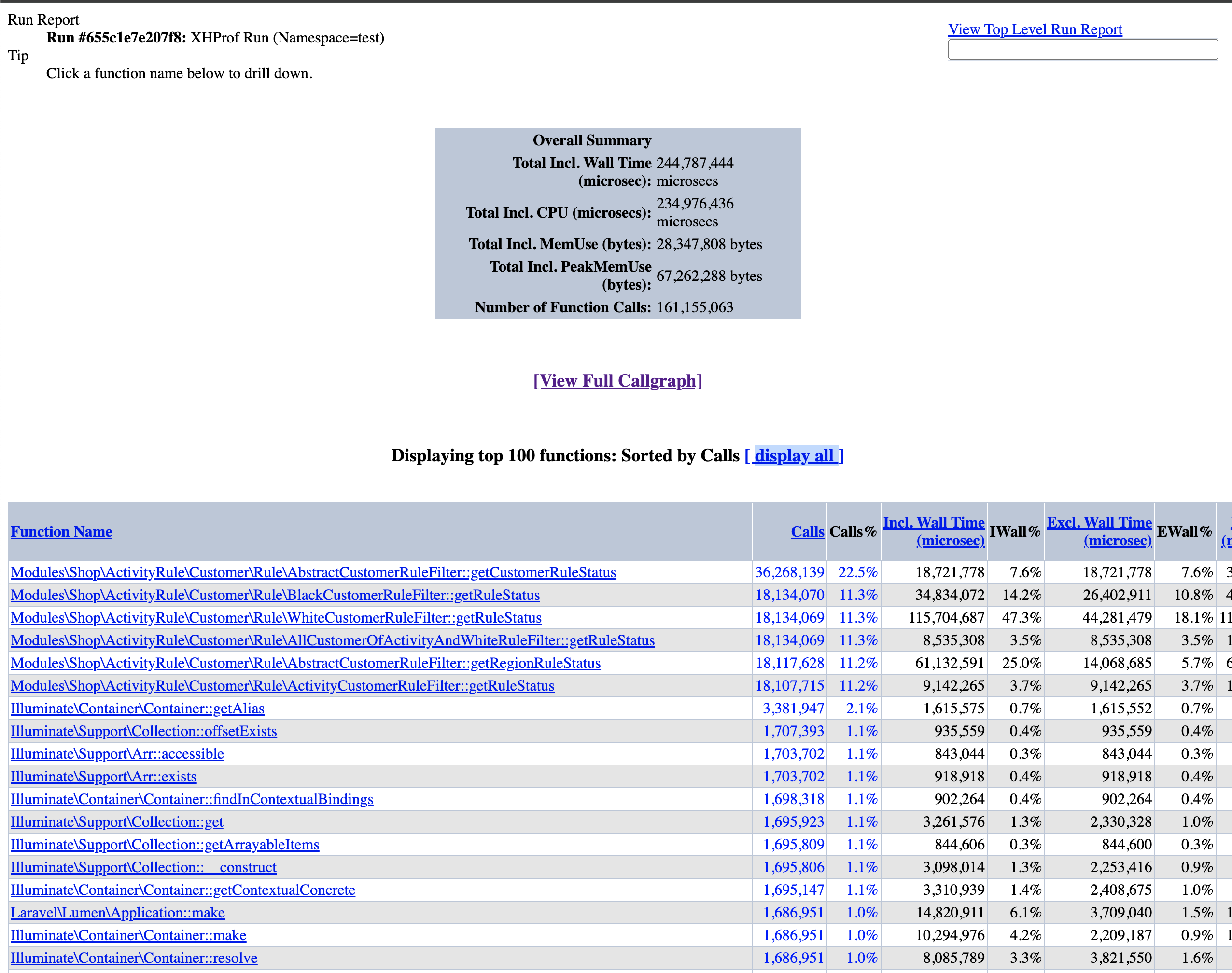
orm_optimize
我们可以看到,我们只是做了一个简单的属性访问,但是底层却调用了
8+ 方法。
方法调用在次数少的时候我们无法感知,但是我们可以看看
100w 次方法调用需要多久:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Test public function t ( {}} $start = microtime (true );$test = new Test ();for ($i = 0 ; $i < 1000000 ; $i ++) { $test ->t (); } dump (bcsub (microtime (true ), $start , 4 ));
上面的代码中,我们的 t 方法里面什么都没有做,但是调用了
100w 次之依然需要 21ms。
也就是说,在模型访问属性所产生的 8+
方法调用中,至少需要花费
160ms,这还是一个保守的数字,因为上面产生的方法调用里面还有一些方法调用没有画出来。
如何优化?
知道了原因之后,我们优化起来就简单了,那就是尽量把 ORM
模型访问属性所产生的额外开销去掉,因为在这里讨论的问题中,并不需要模型帮我们做额外的处理(比如
cast、日期转换)。
因此,最简单的实现方法就是将 ORM
模型转换为普通的实体类型。
这一种优化方法下,也还有两种实现方式,先说第一种,直接创建一个
stdClass 对象,然后将 ORM
模型的属性依次赋值到这个 stdClass 对象中,如下:
在我们定义的模型中添加一个方法 toStdClass:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Foo extends \Illuminate \Database \Eloquent \Model public function toStdClass (stdClass { $result = new stdClass (); foreach ($this ->attributes as $key => $attribute ) { $result ->{$key } = $attribute ; } return $result ; } } $start = microtime (true );$model = new Foo ;$model ->a = 2 ;$stdClass = $model ->toStdClass ();for ($i = 0 ; $i < 1000000 ; $i ++) { $stdClass ->a; } dump (bcsub (microtime (true ), $start , 4 ));
在这种实现方式中,由于我们在循环里面操作的是一个
stdClass,所以也就没有了 ORM
模型访问属性时候的方法调用开销,最终时间是
14ms,也就是跟我们访问普通对象属性的开销一样了,比原来快了
56 倍。
但是,需要注意的是,在这种实现中,由于我们拿到的是一个
stdClass,也就丧失了 ORM
模型本身带来的一些便利。不过好在这种便利在我们只是做简单的属性访问的时候是不需要的,除非我们需要在拿到模型之后还需要做
CRUD
操作。就算如此,我们也依然可以再改造一下我们的实现方式,另外定义一个实体类,使用这个实体类来代替上面的
stdClass,然后再在这个实体类中添加一个方法,让其拥有转换回
ORM 模型的能力(第 2 种实现方式):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 class Foo extends \Illuminate \Database \Eloquent \Model public function toStdClass (stdClass { $result = new stdClass (); foreach ($this ->attributes as $key => $attribute ) { $result ->{$key } = $attribute ; } return $result ; } } class FooEntity public static function make (\Illuminate\Database\Eloquent\Model $model ): self { $result = new self (); foreach ($model ->getAttributes () as $key => $attribute ) { $result ->{$key } = $attribute ; } return $result ; } public function toModel (Foo { $result = new Foo (); foreach (get_object_vars ($this ) as $key => $attribute ) { $result ->setAttribute ($key , $attribute ); } return $result ; } } $model = new Foo ;$model ->a = 2 ;$entity = FooEntity ::make ($model );$model = $entity ->toModel ();
优化效果
这里不贴具体代码了。
在不做其他优化的情况下,只是将循环中的 ORM
模型修改为实体之后,原本 7 分钟的函数,最终只需要
44s 了。
当然,代码还有不少其他可以优化的地方,只是那些是比较常规的可以优化的,这里不再赘述。截止发文这天,这个优化已经上线了,将其他的可以优化的地方优化之后,原本
7 分钟的请求,最终耗时 20s 左右。
存在问题
上面的两种实现方式都没有显式指定类的属性,不好维护。(可以显式定义实体类,并显式定义
ORM 中存在的属性)
转换为 entity 之后无法拥有 ORM
模型的能力,需要注意。
由于第 2
点,所以这种优化不适用于那些需要更新的场景,当然我们也可以将实体转换回
ORM 模型,然后再做 CURD 操作。
总结
Laravel 的 ORM
模型给我们带来了非常大的便利,但是它通过魔术方法 __get()
来获取模型属性的方式在大数据量操作下会有一些性能问题,
如果我们不需要在这过程做 CURD 操作,我们可以将
ORM 转换为简单的实体对象。
这样就可以大大减少在 ORM 模型中访问属性的开销。