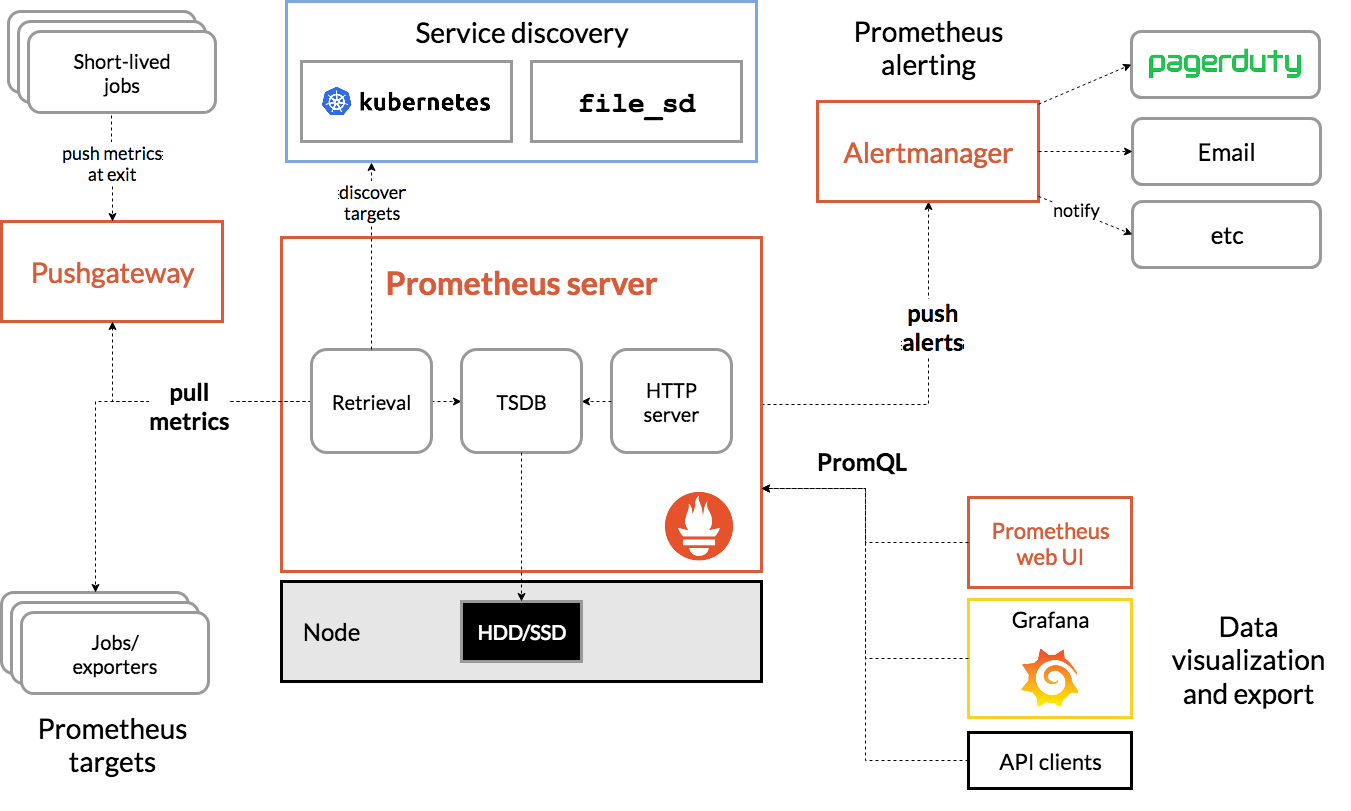
从上一篇开始,好像我们已经脱离了 WebSocket
的技术范畴了,但是我们可能也意识到了,WebSocket
技术本身并不复杂,
我们也很容易地使用它实现了一个消息推送的雏形。复杂的是,早我们使用它来实现一些功能的时候,需要考虑的非技术性的问题,
或者说非功能性的需求。
蔡超的《十年架构感悟》 里面提到过一点:非功能性需求决定架构 (在极客时间上可以搜索到)。
非功能性需求包括性能、伸缩性、可扩展性、可维护性等。功能性需求就是我们实际要实现的功能。
大概意思是:一个好的架构其实是由非功能性需求决定的,而不是由功能性需求决定的。
架构设计完之后,少一个功能性需求,我们很容易就能看出来,未来也可以加上去,它对你的架构不会有本质上的影响。
但如果我们忽略的是某一种非功能性需求,那么未来这可以说是一种灾难性的麻烦,很有可能你就需要重写了。
比如你架构中的数据一致性问题无法解决,或者在设计的时候没有充分考虑性能问题,这样,所有的功能性的实现其实都没有意义。
接下来做什么
其实我们在上一篇就可以结束本系列文章了,因为从某种程度上,我们已经实现了一个消息推送中心了。
但是,这种粗制滥造的方式,在真正投入使用的时候会存在很多问题的,比如:
对于消息投递,我们没有任何的记录:无法知道消息是否投递成功,也不知道消息投递失败的原因
接入麻烦:上一节我们通过 jwt 来实现认证,但是这个
jwt token
的生成和验证都是在消息推送系统中实现的;经验告诉我们,但凡你的东西复杂一点,用户都没有使用的欲望了,人性毕竟都是懒惰的
并未考虑到用户 token
失效的问题:比如用户登出系统之后,我们的消息推送系统也得断开是吧,要不然我都登出了你还给我推送消息
系统内部指标数据完全没有:比如连接数、等待连接数、等待推送的消息数等,这样如果有性能问题就不好排查了
其他:性能、伸缩性、可扩展性都存在问题
本系列文章的最终目的是要实现一个生产可用的消息推送中心,因此会继续实现这些非功能性需求。
添加消息推送日志
需求
我们的消息推送系统,需要记录每一条消息的投递情况,包括投递成功、投递失败的原因等。
一方面是为了方便排查问题,另一方面也是为了了解系统是否正常运作。
当然这些日志不会长时间保留,具体保留多长时间,我们可以加个配置留给用户决定即可。
依赖倒置原则
虽然暂时还没有实现让整个系统具有较高的扩展性,但是我们可以在代码上先让代码具有扩展性,
这样在未来我们要扩展的时候,就不需要改动太多的代码了。
我们可以先思考一下,我们下面的推送消息代码,应该如何修改来实现上述需求(假设我们的消息要存入数据库):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 func send (hub *Hub, w http.ResponseWriter, r *http.Request) uid := r.FormValue("uid" ) if uid == "" { w.WriteHeader(http.StatusBadRequest) return } hub.Lock() client, ok := hub.userClients[uid] hub.Unlock() if !ok { w.WriteHeader(http.StatusBadRequest) return } message := r.FormValue("message" ) client.send <- []byte (message) } func (c *Client) defer func () _ = c.conn.Close() }() for { select { case message, ok := <-c.send: c.conn.SetWriteDeadline(time.Now().Add(writeWait)) if !ok { c.conn.WriteMessage(websocket.CloseMessage, []byte {}) return } if err := c.conn.WriteMessage(websocket.TextMessage, message); err != nil { return } } } }
我们可以暂时不考虑上面代码的实现,只是思考一下,如果我们要实现上述需求,应该如何修改代码呢?
非常容易想到的一种方法就是,在 init
函数中初始化一个全局的数据库连接, 然后在 send
方法中使用这个连接将消息存入数据库(假设我们使用的是
gorm):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 var db *gorm.DBtype Log struct { gorm.Model Uid string Message string Status int CreatedAt time.Time } func init () var err error db, err = gorm.Open(sqlite.Open("log.db" ), &gorm.Config{}) if err != nil { panic (err) } }
然后发送消息前写入数据库:
1 2 3 4 5 6 7 8 9 10 11 12 13 db.AutoMigrate(&Log{}) db.Create(&Log{ Uid: uid, Message: r.FormValue("message" ), Status: 0 , CreatedAt: time.Now(), }) message := r.FormValue("message" ) client.send <- []byte (message)
这样实现起来确实简单,但是这样的代码耦合度太高了,
高层模块依赖了底层模块,依赖于具体的实现,这样的代码是不具有扩展性的 。
一种更好的方式是:针对写日志这个功能,我们先建立起一个抽象模型,然后高层代码只使用这个模型,不用去考虑底层的实现。
这一点就是 SOLID 里面的
D,依赖倒置原则(Dependency Inversion Principle)。
依赖倒置原则是这样陈述的:高层模块不应依赖于低层模块,二者应依赖于抽象。抽象不应依赖于细节,细节依赖于抽象。
基于依赖倒置原则的具体实现
先建立起一个抽象模型
首先我们得有一个实体来表示消息本身(MessageLog),然后就是记录消息的抽象模型(MessageLogger):
1 2 3 4 5 6 7 8 type MessageLog struct { Uid string Message string } type MessageLogger interface { Log(log MessageLog) error }
实现这个抽象模型
我们依然是使用 gorm 来实现这个抽象模型:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 package mainimport ( "gorm.io/driver/sqlite" "gorm.io/gorm" "time" ) var db *gorm.DBtype Log struct { gorm.Model Uid string Message string Status int CreatedAt time.Time } func init () var err error db, err = gorm.Open(sqlite.Open("log.db" ), &gorm.Config{}) if err != nil { panic (err) } } var _ MessageLogger = &MySQLMessageLogger{}type MySQLMessageLogger struct {} func (m *MySQLMessageLogger) error { db.AutoMigrate(&Log{}) db.Create(&Log{ Uid: log.Uid, Message: log.Message, Status: 0 , CreatedAt: time.Now(), }) return nil }
虽然我们代码跟之前依然是一样,但是我们的代码已经具有了扩展性。
高层代码使用这个抽象模型
依赖倒置原则中说了,高层模块不应该依赖于低层模块。因此我们在
send 方法中记录消息的时候, 不应该直接使用
gorm 来写入数据库,而是使用 MessageLogger
这个抽象模型:
在 hub 中添加 MessageLogger 字段:
1 2 3 4 type Hub struct { messageLogger MessageLogger }
在 newHub 函数中初始化
MessageLogger:
1 2 3 4 5 6 func newHub () return &Hub{ messageLogger: &MySQLMessageLogger{}, } }
虽然高层模块不能直接依赖底层实现,但是总会有一个地方是将高层和底层连接起来的,这个地方一般就是创建对象的地方,
在很多现代的框架中,它有另外一个名字:依赖注入容器。
而在本系列文章中,并没有用到什么框架、依赖注入容器,但是我们还是有一个专门的创建对象的地方,那就是
newHub 函数。 因此我们在这里将 MessageLogger
依赖注入到 Hub 中。
在 send 方法中使用 MessageLogger:
最后将原本 send
方法中的数据库操作代码替换为对抽象模型的调用即可:
1 2 messageLog := MessageLog{Uid: uid, Message: r.FormValue("message" )} _ = hub.messageLogger.Log(messageLog)
这样,我们就完成了对消息推送日志的记录。
那如何替换为另一种日志记录方式
我们现在知道了,依赖倒置原则可以指导我们设计出具有扩展性的代码,那在我们这个实例中,如何替换为另一种日志记录方式呢?
其实非常简单,比如我们现在要直接输出到控制台中,那么我们只需要实现一个
StdoutMessageLogger 即可:
1 2 3 4 5 6 7 8 9 10 var _ MessageLogger = &StdoutMessageLogger{}type StdoutMessageLogger struct {} func (s *StdoutMessageLogger) error { res, _ := json.Marshal(log) fmt.Println("send message: " + string (res)) return nil }
然后在 newHub 中将 messageLogger 替换为
&StdoutMessageLogger{} 即可:
1 2 3 4 5 6 func newHub () return &Hub{ messageLogger: &StdoutMessageLogger{}, } }
这样,我们在发送消息的时候就可以直接在控制台中看到消息了。
在实际开发中,使用 StdoutMessageLogger
更加方便我们调试代码。
我们可以发现,我们这种设计方式完美地实现了开闭原则,我们添加新的日志记录方式的时候,
不需要修改太多代码,只需要添加新的实现,然后修改 newHub
方法中的一行代码即可, 这样的代码显然更具扩展性,也更好维护。
错误处理
对于消息推送,如果推送失败,我们一般也需要知道推送失败的原因。
同样的,我们的框架本身也不应该依赖于具体的错误处理程序,而是应该使用抽象模型来实现。
从这个原则出发,我们就可以先建立一个抽象模型,然后再实现这个抽象模型:
先建立起一个抽象模型
1 2 3 4 5 6 7 type Handler func (log message.Log, err error ) type Hub struct { errorHandler Handler }
因为错误处理本身没有太复杂的功能,因此我们直接使用 type
关键字将其定义为一个函数类型即可。 然后在 Hub
中加上错误处理器的字段 errorHandler。
实现这个抽象模型
其实也谈不上实现,因为没有定义什么
interface,我们只需要定义一个函数即可:
1 2 3 4 func defaultErrorHandler (log message.Log, err error ) res, _ := json.Marshal(log) fmt.Printf("send message: %s, error: %s\n" , string (res), err.Error()) }
在本文的例子中,我们先定义一个输出错误信息到控制台的错误处理器。
然后,我们需要在 newHub 中初始化这个错误处理器:
1 2 3 4 5 6 func newHub () return &Hub{ errorHandler: defaultErrorHandler, } }
高层代码使用这个抽象模型
为了方便后续处理,我们将 send
方法中的代码稍微修改了一下,将 messageLog 作为参数传入到
send 通道中了,同时将 client 的
send 通道改为 chan message.Log:
1 2 3 4 type Client struct { send chan message2.Log }
发送消息修改:
1 2 3 4 5 messageLog := message.Log{Uid: uid, Message: r.FormValue("message" )} _ = hub.messageLogger.Log(messageLog) client.send <- messageLog
writePump 修改:
1 2 3 if err := c.conn.WriteMessage(websocket.TextMessage, []byte (messageLog.Message)); err != nil { return }
最终 writePump 会演化为下面这样,错误处理:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 for { select { case messageLog, ok := <-c.send: c.conn.SetWriteDeadline(time.Now().Add(writeWait)) if !ok { c.conn.WriteMessage(websocket.CloseMessage, []byte {}) c.hub.errorHandler(messageLog, fmt.Errorf("send channel closed" )) return } if err := c.conn.WriteMessage(websocket.TextMessage, []byte (messageLog.Message)); err != nil { c.hub.errorHandler(messageLog, err) return } } }
跟之前不一样的地方是,这里会使用 c.hub.errorHandler
进行错误处理。
最终的效果是,对于后续维护而言,核心的处理流程基本上不会变动,而可能需要我们修改的地方都已经被抽象出来了:
错误处理我们可以通过修改 errorHandler
来实现,日志记录我们可以通过修改 messageLogger 来实现。
当然在实际场景中,我们可能还会有类似
onOpen、onClose
之类的需求,但本文就先到此为止了,这些都是可以通过类似的方式来实现的。
总结
本人文章可能文字会比较多,但是其中都是个人在此过程中的一些思考,相比直接告诉大家怎么做,有可能知道为什么这么做更重要。
最后,简单回顾一下本文的内容:
消息推送这个功能,技术上其实我们已经实现了,但是我们还得考虑很多非功能性的需求,这些非功能性的需求决定了我们的架构。
依赖倒置原则可以指导我们设计出具有扩展性的代码:本文中的日志记录抽象出了一个
MessageLogger,需要的时候我们可以自行实现然后替换掉框架提供的实现。
错误处理:为了方便后续维护,处理处理我们也是抽象出了一个
func
类型,实现了关注点的分离,也在一定程度上给后续的扩展提供了可能。