深入理解 go RWMutex
在上一篇文章《深入理解
go Mutex》中, 我们已经对 go Mutex
的实现原理有了一个大致的了解,也知道了 Mutex
可以实现并发读写的安全。
今天,我们再来看看另外一种锁,RWMutex,有时候,其实我们读数据的频率要远远高于写数据的频率,
而且不同协程应该可以同时读取的,这个时候,RWMutex
就派上用场了。
RWMutex 的实现原理和 Mutex 类似,只是在
Mutex 的基础上,区分了读锁和写锁:
- 读锁:只要没有写锁,就可以获取读锁,多个协程可以同时获取读锁(可以并行读)。
- 写锁:只能有一个协程获取写锁,其他协程想获取读锁或写锁都只能等待。
下面就让我们来深入了解一下 RWMutex
的基本使用和实现原理等内容。
RWMutex 的整体模型
正如 RWMutex
的命名那样,它是区分了读锁和写锁的锁,所以我们可以从读和写两个方面来看
RWMutex 的模型。
下文中的
reader指的是进行读操作的 goroutine,writer指的是进行写操作的 goroutine。
读操作模型
我们可以用下图来表示 RWMutex 的读操作模型:
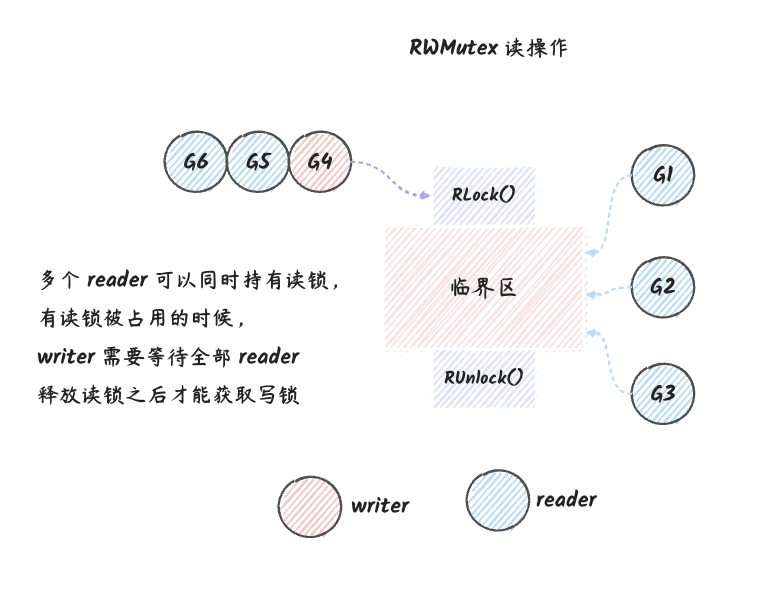
上图使用了
w.Lock,是因为RWMutex的实现中,写锁是使用Mutex来实现的。
说明:
- 读操作的时候可以同时有多个 goroutine 持有
RLock,然后进入临界区。(也就是可以并行读),上图的G1、G2和G3就是同时持有RLock的几个 goroutine。 - 在读操作的时候,如果有 goroutine 持有
RLock,那么其他 goroutine (不管是读还是写)就只能等待,直到所有持有RLock的 goroutine 释放锁。 - 也就是上图的
G4需要等待G1、G2和G3释放锁之后才能进入临界区。 - 最后,因为
G5和G6这两个协程获取锁的时机比G4晚,所以它们会在G4释放锁之后才能进入临界区。
写操作模型
我们可以用下图来表示 RWMutex 的写操作模型:
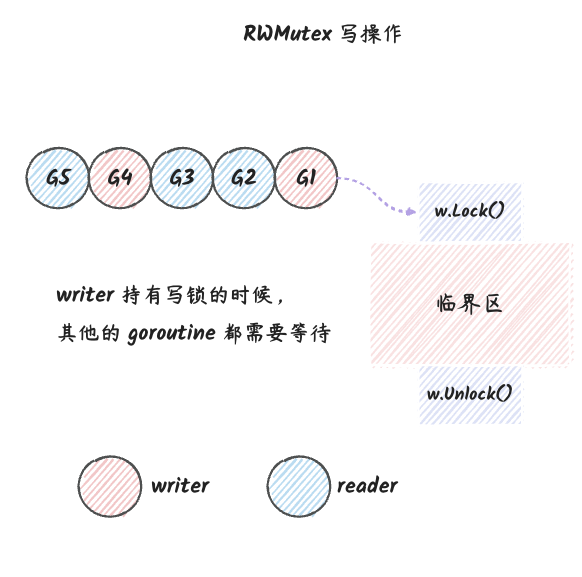
说明:
- 写操作的时候只能有一个 goroutine 持有
Lock,然后进入临界区,释放写锁之前,所有其他的 goroutine 都只能等待。 - 上图的
G1~G5表示的是按时间顺序先后获取锁的几个 goroutine。 - 上面几个 goroutine 获取锁的过程是:
G1获取写锁,进入临界区。然后G2、G3、G4和G5都在等待。G1释放写锁之后,G2和G3可以同时获取读锁,进入临界区。然后G3、G4和G5都在等待。G2和G3可以同时获取读锁,进入临界区。然后G4和G5都在等待。G2和G3释放读锁之后,G4获取写锁,进入临界区。然后G5在等待。- 最后,
G4释放写锁,G5获取读锁,进入临界区。
基本用法
RWMutex 中包含了以下的方法:
Lock:获取写锁,如果有其他 goroutine 持有读锁或写锁,那么就会阻塞等待。Unlock:释放写锁。RLock:获取读锁,如果有其他 goroutine 持有写锁,那么就会阻塞等待。RUnlock:释放读锁。
其他不常用的方法:
RLocker:返回一个读锁,该锁包含了RLock和RUnlock方法,可以用来获取读锁和释放读锁。TryLock: 尝试获取写锁,如果获取成功,返回true,否则返回false。不会阻塞等待。TryRLock: 尝试获取读锁,如果获取成功,返回true,否则返回false。不会阻塞等待。
一个简单的例子
我们可以通过下面的例子来看一下 RWMutex 的基本用法:
1 | package mutex |
上面的例子中,我们启动了 10 个 goroutine 来写配置,启动了 100 个 goroutine 来读配置。 这跟我们现实开发中的场景是一样的,很多时候其实是读多写少的。 如果我们在读的时候也使用互斥锁,那么就会导致读的性能非常差,因为读操作一般都不会有副作用的,但是如果使用互斥锁,那么就只能一个一个的读了。
而如果我们使用 RWMutex,那么就可以同时有多个 goroutine
来读取配置,这样就可以大大提高读的性能。
因为我们进行读操作的时候,可以多个 goroutine
并发读取,这样就可以大大提高读的性能。
RWMutex 使用的注意事项
在《深入理解
go Mutex》中,我们已经讲过了 Mutex 的使用注意事项,
其实 RWMutex 的使用注意事项也是差不多的:
- 不要忘记释放锁,不管是读锁还是写锁。
Lock之后,没有释放锁之前,不能再次使用Lock。- 在
Unlock之前,必须已经调用了Lock,否则会panic - 在第一次使用
RWMutex之后,不能复制,因为这样一来RWMutex的状态也会被复制。这个可以使用go vet来检查。
源码剖析
RWMutex 的一些实现原理跟 Mutex
是一样的,比如阻塞的时候使用信号量等,在 Mutex
那一篇中已经有讲解了,这里不再赘述。 这里就 RWMutex
的实现原理进行一些简单的剖析。
RWMutex 结构体
RWMutex 的结构体定义如下:
1 | type RWMutex struct { |
各字段含义:
w:互斥锁,用于保护读写锁的状态。RWMutex的写锁是互斥锁,所以直接使用Mutex就可以了。writerSem:writer 信号量,用于实现写锁的阻塞等待。readerSem:reader 信号量,用于实现读锁的阻塞等待。readerCount:所有 reader 数量(包括已经获取读锁的和正在等待获取读锁的 reader)。readerWait:writer 等待完成的 reader 数量(也就是获取写锁的时刻,已经获取到读锁的 reader 数量)。
因为要区分读锁和写锁,所以在 RWMutex
中,我们需要两个信号量,一个用于实现写锁的阻塞等待,一个用于实现读锁的阻塞等待。
我们需要特别注意的是 readerCount 和 readerWait
这两个字段,我们可能会比较好奇,为什么有了 readerCount
这个字段, 还需要 readerWait 这个字段呢?
这是因为,我们在尝试获取写锁的时候,可能会有多个 reader
正在使用读锁,这时候我们需要知道有多少个 reader 正在使用读锁, 等待这些
reader 释放读锁之后,就获取写锁了,而 readerWait
这个字段就是用来记录这个数量的。 在 Lock
中获取写锁的时候,如果观测到 readerWait 不为 0
则会阻塞等待,直到 readerWait 为 0
之后才会真正获取写锁,然后才可以进行写操作。
读锁源码剖析
获取读锁的方法如下:
1 | // 获取读锁 |
读锁的实现很简单,先将 readerCount 加 1,如果加 1
之后的值小于 0,说明有 writer 正在使用锁,那么就需要阻塞等待 writer
完成。
释放读锁的方法如下:
1 | // 释放读锁 |
读锁的实现总结:
- 获取读锁的时候,会将
readerCount加 1 - 如果正在获取读锁的时候,发现
readerCount小于 0,说明有 writer 正在使用锁,那么就需要阻塞等待 writer 完成。 - 释放读锁的时候,会将
readerCount减 1 - 如果
readerCount减 1 之后小于 0,说明有 writer 正在等待,那么就需要唤醒 writer。 - 唤醒 writer 的时候,会将
readerWait减 1,如果readerWait减 1 之后为 0,说明 writer 获取锁的时候存在的 reader 都已经释放了读锁,可以获取写锁了。
·rwmutexMaxReaders
算是一个特殊的标识,在获取写锁的时候会将readerCount的值减去rwmutexMaxReaders, 所以在其他地方可以根据readerCount` 是否小于 0 来判断是否有 writer 正在使用锁。
写锁源码剖析
获取写锁的方法如下:
1 | // 获取写锁 |
释放写锁的方法如下:
1 | // 释放写锁 |
写锁的实现总结:
- 获取写锁的时候,会将
readerCount减去rwmutexMaxReaders,这样就可以区分读锁和写锁了。 - 如果
readerCount减去rwmutexMaxReaders之后不为 0,说明有 reader 正在使用读锁,那么就需要阻塞等待这些 reader 释放读锁。 - 释放写锁的时候,会将
readerCount加上rwmutexMaxReaders。 - 如果
readerCount加上rwmutexMaxReaders之后大于 0,说明有 reader 正在等待写锁释放,那么就需要唤醒这些 reader。
TryRLock 和 TryLock
TryRLock 和 TryLock
的实现都很简单,都是尝试获取读锁或者写锁,如果获取不到就返回
false,获取到了就返回
true,这两个方法不会阻塞等待。
1 | // TryRLock 尝试锁定 rw 以进行读取,并报告是否成功。 |
总结
RWMutex 使用起来比较简单,相比 Mutex
而言,它区分了读锁和写锁,可以提高并发性能。最后,总结一下本文内容:
RWMutex有两种锁:读锁和写锁。- 读锁可以被多个 goroutine 同时持有,写锁只能被一个 goroutine 持有。也就是可以并发读,但只能互斥写。
- 写锁被占用的时候,其他的读和写操作都会被阻塞。读锁被占用的时候,其他的写操作会被阻塞,但是读操作不会被阻塞。除非读操作发生在一个新的写操作之后。
RWMutex包含以下几个方法:Lock:获取写锁,如果有其他的写锁或者读锁被占用,那么就会阻塞等待。Unlock:释放写锁。RLock:获取读锁,如果写锁被占用,那么就会阻塞等待。RUnlock:释放读锁。
- 也包含了两个非阻塞的方法:
TryLock:尝试获取写锁,如果获取不到就返回false,获取到了就返回true。TryRLock:尝试获取读锁,如果获取不到就返回false,获取到了就返回true。
RWMutex使用的注意事项跟Mutex差不多:- 使用之后不能复制
Unlock之前需要有Lock调用,否则panic,RUnlock之前需要有RLock调用,否则panic。- 不要忘记使用
Unlock和RUnlock释放锁。
RWMutex的实现:- 写锁还是使用
Mutex来实现。 - 获取读锁和写锁的时候,如果获取不到都会阻塞等待,直到被唤醒。
- 获取写锁的时候,会将
readerCount减去rwmutexMaxReaders,这样就可以直到有写锁被占用。释放写锁的时候,会将readerCount加上rwmutexMaxReaders。 - 获取写锁的时候,如果还有读操作未完成,那么这一次获取写锁只会等待这部分未完成的读操作完成。所有后续的操作只能等待这一次写锁释放。
- 写锁还是使用