更高效率地查询:使用批量查询代替
foreach 查询(多次 io 操作转换为一次
io 操作)
如果想要查看更详尽的介绍,可以看看这篇文章 什么是
N+1 问题,以及如何解决 Laravel 的 N+1 问题?
在维护的项目中,
我发现了有不少需要查询关联数据的时候是这样做的:先查询出列表,然后
foreach
列表去查询列表每一条记录的关联数据,好比如这样:
1 2 3 4 5 6 7 8 $products = \DB::table ('product' )->where ('category_id' , 1 )->paginate ();foreach ($products as $key => $product ) { $product ['some_other_info' ] = \DB::table ('some_other_info' ) ->where ('product_id' , $product ['id' ]) ->get (); $products [$key ] = $product ; }
解决方法:使用一次查询代替多次查询
定义模型关联,使用 Model 的 with
进行查询。如:
1 AdminUser ::with ('admin_user_info' )->where ('id' , '>' , 1 )->get ();
获取查询结果集的 id 列(根据实际情况而定),使用
whereIn
一次查询关联数据。对于那些不能定义关联的才用这种方法,因为这种写法有点啰嗦
1 2 3 4 5 6 7 8 9 10 $products = \DB::table ('product' )->where ('category_id' , 1 )->paginate ();$product_ids = $products ->pluck ('id' )->toArray (); $some_other_infos = \DB::table ('some_other_info' ) ->whereIn ('product_id' , $product_ids ) ->get ();<br> $some_other_infos = array_column ($some_other_infos , null , 'product_id' ); foreach ($products as $key => $product ) { $product ['some_other_info' ] = array_get ($some_other_infos , $product ['id' ]); $products [$key ] = $product ; }
先说说 关联查询:我们在 Model
类里定义的关联,我们不一定在第一次查询就全部查出来,我们可以在需要的时候再去查询
, 使用 load 方法,可以实现这个目标,但是这个
load 只是针对单个 model 对象的,如果我们
Model::xxx()->xx() 链式操作最后是 get(),
我们得到的结果将会是一个 Collection 实例,最后调用的方法是
first() 或其他类似的 firstOrFail()
的时候,返回的才是一个 Model 实例。也就是说
load 方法只针对 Model 实例。如下:
我们假设有如下模型定义:
AdminUser
1 2 3 4 5 6 7 8 9 10 11 12 <?php namespace App \Model ; class AdminUser extends BaseModel public function admin_user_info ( { return $this ->hasOne (AdminUserInfo ::class ); } }
AdminUserInfo
1 2 3 4 5 6 7 <?php namespace App \Model ; class AdminUserInfo }
使用 load 方法加载关联
1 2 $adminUsers = AdminUser ::limit (10 )->get ();$adminUsers ->load ('admin_user_info' );
更优雅地处理你的
paginate() 结果(利用 Collection
里的方法)
这里应该有一小点,我们想要实现某些功能的时候可以先看看框架有没有提供相关的支持,如命名在驼峰式、下划线式转换;
字符串是否以某些子串开始、结束;数组排序、过滤等等,其实很多常用的功能
Laravel 都有现成的轮子, 最常用的一些功能可以查看
Arr、Str、Collection
的源码,利用好的话可以把代码写得简洁一些。
这个其实最近才发现的,最近脑洞开了一下,因为想从
paginate() 返回的对象中获取结果集的 id
列,所以就想能不能 $paginator->pluck('id')->toArray()
这样操作,最后发现真的可以,然后去看了源码发现
AbstractPaginator 这个抽象类里有一个 __call
的方法,如下:
1 2 3 4 5 6 7 8 9 10 11 public function __call ($method , $parameters return $this ->getCollection ()->$method (...$parameters ); }
我们会发现,这个魔术方法调用的是 Collection
里面的方法,也就是说,我们可以把 paginate()
返回的结果当作一个 Collection 实例来操作。 所有的
Collection 方法我们都可以使用,什么
filter、map、sort 等等等等。
而我之前获取 id 列都是使用
array_column($paginator->items(), 'id'),两种写法差不多,
但是对于另外一些如根据某个字段排序等操作,利用 Collection
的 sort 方法明显就简洁多了。
利用
Macroable Trait 更优雅地对框架某些功能进行扩展
我们想想,如果有一天,我们需要自定义一些 Query Builder
的方法的时候,我们会怎么做? 当然我们可以利用 Global Scopes
这个特性来实现某些类似的功能,但是如果我们想要 DB
类也用上这个扩展的方法的话,这样就行不通了。
也不是完全没有办法,Laravel
的开发者很早开始就考虑到了扩展性的问题,我们去查看
Query Builder 的源码就会发现,里面有以下的
trait 调用:
1 2 3 use BuildsQueries , Macroable { __call as macroCall ; }
而这个 Macroable 是
Illuminate\Support\Traits\Macroable,我们可以从这个
trait 中发现, 其实这个 trait
提供了一个很强大的扩展功能,对于所有 use Macroable 的类,
我们都可以通过 XXX::macro('xx', function (){})
的方式来对这个类进行扩展。
我们全局搜索这个
Macroable,会发现框架不少地方都有使用:如
Cache、Console、Eloquent、Schema
等等,如果我们想要对框架中某些类进行扩展的时候,不妨先看看这个类有没有
use Macroable, 如果有,我们就可以省去一大部分功夫。
x
当然,我们利用 macro 方法来扩展的功能,IDE
不会有任何提示,除非,我们像 ide-helper
那样处理。具体可参照另外一篇文章:Laravel query builder/ Eloquent builder
添加自定义方法
利用
array_get、data_get 方法代替多个
isset 判断
最常用到的地方是,我们利用 with
关联查询出多层关联,但是我们不确定所有层级关联是否存在,所以我们可能就要一层层地
isset 来判断。
假设有一个这样的关联 User -> HasOne -> Article -> HasOne
-> Comment,这个假设不太妥当,但可以说明问题
我们查询的时候按如下方式查询:
1 2 3 4 $user = User ::with (['article.comment' ])->first ();$content = isset ($user ->article) ? (isset ($user ->article->comment) ? $user ->article->comment : '' ) : '' ; $content = data_get ($user , 'article.comment.content' );
上面的例子中,我们可以发现 data_get
写出的代码更简洁、可读性也更强,array_get 功能类似,但是
array_get 不能针对对象操作。 利用 array_get
可以更方便完成地进行对多维数组的操作,因为 Laravel
把多维数组抽象成了点号分隔的一维数组,不得不说,说 Laravel
优雅不是没有道理的。
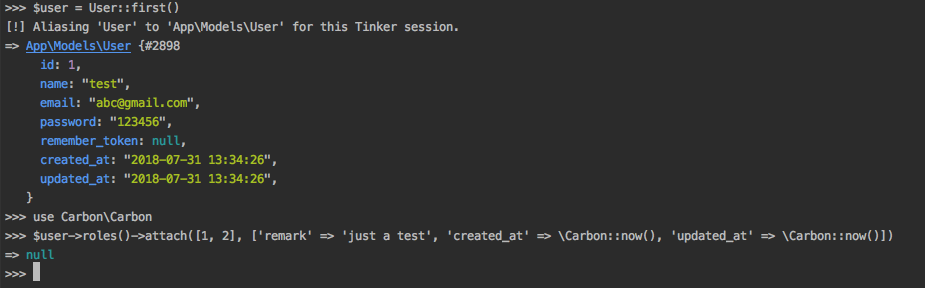
多对多关联更方便的操作方法
attach、detach、sync
1 2 3 4 5 6 7 8 9 10 11 12 13 14 $user ->roles ()->attach ($roleId );$user ->roles ()->attach ($roleId , ['expires' => $expires ]);$user ->roles ()->detach ($roleId );$user ->roles ()->detach ();$user ->roles ()->detach ([1 , 2 , 3 ]);$user ->roles ()->attach ([1 => ['expires' => $expires ], 2 , 3 ]); $user ->roles ()->sync ([1 , 2 , 3 ]);$user ->roles ()->sync ([1 => ['expires' => true ], 2 , 3 ]);
使用 sync 方法的时候需要注意,如果第二个参数不设置
false,会把不在给定数组中的 ID
的关联数据全部删除。
上面的关联是 User -> belongsToMany ->
Role,通过多对多表的关联,具体可查看另一篇文章:Laravel5.1
使用中间表的多对多关联,我们通过下面的例子来说明一下 attach
的用法,其他几个方法也是类似的功能,
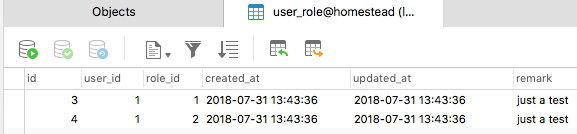
我们查看以下数据库中间表记录:
x
我们可以发现,user 关联了 id 为 1 和 2
的两个 role,同时 attach
第二个参数可以让我们传递一些额外数据保存到中间表。
sync 的功能和 attach 类似,但是
sync
还有个功能是,可以把不在指定数组的关联数据删除(如果我们不需要删除可以传递第二个参数
false,或者直接使用 attach)。
使用 debugbar
尽早发现性能问题
这个其实使用 Laravel
的人基本上都知道,但是可能我们没有用到其中一些功能, 其实
Laravel-debugbar 可以通过配置获取更加详情的信息(如
sql 的堆栈信息、是否 explain
等等非常多实用的功能),
具体功能还是得查看其官方文档,有很多实用的功能,可以让我们对我们的代码了解更多。
使用 chunk
处理表全部数据
有时候,我们给表新增了一个字段,这个字段是由其他字段算出来的,这时候我们就需要跑一遍该表,进行该字段的更新。
一种做法是一次性全表查询出来,foreach
循环处理,这种做法在数据量小的时候问题不大,
但是数据量达到一定程度的时候会产生比较严重的问题:内存耗尽,更严重的是把服务器也弄挂。
另外一种方法是使用 Builder 的 chunk
方法进行批量处理,可以解决内存占用过大的问题。如下:
1 2 3 4 5 6 7 DB::table ('users' )->chunk (100 , function($users ) { foreach ($users as $user ) { } });
关联数据分页、统计或者其他类似操作
我们先来看看 Relation 的定义(5.6),我们可以发现里面有个
__call 方法,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public function __call ($method , $parameters if (static ::hasMacro ($method )) { return $this ->macroCall ($method , $parameters ); } $result = $this ->query->{$method }(...$parameters ); if ($result === $this ->query) { return $this ; } return $result ; }
我们可以发现它会先看 有没有定义相关的
macro,如果没有则去调用
\Illuminate\Database\Eloquent\Builder 里面的方法,
而我们继续看 \Illuminate\Database\Eloquent\Builder
里面的源码(5.6)发现,里面也有一个 __call 方法,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 public function __call ($method , $parameters if ($method === 'macro' ) { $this ->localMacros[$parameters [0 ]] = $parameters [1 ]; return ; } if (isset ($this ->localMacros[$method ])) { array_unshift ($parameters , $this ); return $this ->localMacros[$method ](...$parameters ); } if (isset (static ::$macros [$method ])) { if (static ::$macros [$method ] instanceof Closure ) { return call_user_func_array (static ::$macros [$method ]->bindTo ($this , static ::class ), $parameters ); } return call_user_func_array (static ::$macros [$method ], $parameters ); } if (method_exists ($this ->model, $scope = 'scope' .ucfirst ($method ))) { return $this ->callScope ([$this ->model, $scope ], $parameters ); } if (in_array ($method , $this ->passthru)) { return $this ->toBase ()->{$method }(...$parameters ); } $this ->query->{$method }(...$parameters ); return $this ; }
上面是 5.6 版本的 __call,5.1 版本的 __call
相对来说,功能少一些,但是都有的功能就是,先去看 macro
有没有定义, 如果前面条件都不满足就去调用 Query Builder
中对应的方法,当然,如果 Query Builder
里面也没有这个方法就会抛出异常。而实现这些功能都得益于 php 的
__call 魔术方法。
关于
Eloquent Builder 和 Query Builder
的区别:
我们使用 Eloquent Model 类或
Eloquent Model 子类进行操作的时候,如果使用的都是
Eloquent Builder 里面的方法, 那么返回的也是一个
Eloquent Builder 或者是最终结果(视操作而定,有可能是
Collection 实例、null、某个 Model
子类的实例等)。 虽然 __call 中可能会调用到
Query Builder 的方法,而 Query Builder
的方法里面可能会返回 $this,这时候我们可能会有一种错觉,
我们通过 __call 间接调用了 Query Builder
里面方法的时候,返回的是不是一个 Query Builder 的实例。
看起来好像的确是这样,但我们实际操作一下就发现,返回的还是
Eloquent Builder 实例。这是因为上面 __call
最后两行,如果写成
1 return $this ->query->{$method }(...$parameters );
那么返回的就是 Query Builder 了,但实际上,调用
Query Builder 里面的方法和 return
语句是分开的,当然,这里的 $this 肯定是
Eloquent Builder 的实例了。
Eloquent Builder可以使用 Query Builder
的方法,但是 Query Builder 不能使用
Eloquent Builder 的方法。 所以开发中使用 Model
进行 curd
操作的话,相对来说操控性更强,再加上有模型关联这些强大的功能,可以使用
Model 就没必要用 DB 类了。
好像又说得有点远了,这一点应该说的是,Relation
的相关操作,因为 Relation 的 __call
里面也用到了 Query Builder,所以我们可以直接在关联上调用
Query Builder
里面的方法。但是这个时候关联使用需要加上括号。如:
1 2 3 $user ->roles; $user ->roles ()->count ();
分页也类似 $user->roles()->paginate();
这在我们需要查看某条记录的关联数据时候非常有用。
表名使用单数命名时候
Model 类不用定义 protected $table
Laravel
中表名默认是复数形式的,不知道大家有没有用复数做表名,我是没有这种习惯。如果我们想用单数命名,又不想每个
Model 类里面写一个 protected $table;可以重写
Model 类的 getTable 方法
1 2 3 4 5 6 7 8 9 10 11 12 13 public function getTable ( if (isset ($this ->table)) { return $this ->table; } return str_replace ('\\' , '' , Str ::snake (class_basename ($this ))); }
把转复数的调用去掉就好了。
为复杂表单创建一个
validator
这个其实也不算是什么技巧,可能一开始写得舒服就一个个 if
判断,但是这样子到最后会发现我们的代码越来越长,然后可读性也会越来越差。我们可以尝试使用一下
validator:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 $validator = \Validator ::make (request ()->all (), [ 'buyer_id' => 'required' , 'amount' => 'required|numeric|gt:0' ], [ 'buyer_id.required' => ':attribute不能为空' , 'amount.required' => '请填写:attribute' , 'amount.numeric' => ':attribute必须为数字' , 'amount.gt' => ':attribute必须大于0' ], [ 'buyer_id' => '客户id' , 'amount' => '金额' ]); if ($validator ->fails ()) { return $this ->ajaxFail ($validator ->messages ()->first ()); }
有些看起来是没什么用的,如
buyer_id,一般情况下,我们会用一个隐藏域保存这个
id,但是我们还是得防止一些非法的请求,
同时也是为了保持数据的完整性,因为这的确是必须的数据,如果有一天某个错误导致这个关联的
id 没有保存到,可能会导致一些神奇的 bug 出现。
返回页面的同时返回一些额外的信息(如警告、错误)
1 return redirect ()->back ()->withErrors ('some error' );
前端获取:
1 2 3 @if (Session ::has ('error' )) toastr.warning ('{{Session::get(' error')}}' , '' , options); @endif
其实 Laravel 在处理表单的时候也有一些类似的处理, 如
redirect('form')->withInput();
在控制器以外的地方返回响应
这种做法可能会导致难以调试的
bug(因为维护的人可能不知道在哪里返回了),不过实在需要的时候,可以用一用。
1 response ()->json (['message' => 'test send response directly' ])->send ();exit ;
使用
EloquentCollection 加载关联
我们在使用 User::get() 的时候获取到的是一个
Illuminate\Database\Eloquent\Collection
实例,这个实例继承了 Illuminate\Support\Collection,
可以直接使用 Illuminate\Support\Collection
的方法。除此之外,还有一些自身特有的方法,比如
load,我们可以使用 load
方法加载每一项的关联数据, 好比如,如果每一个 User 有一个
info 关联,我们可以使用
$users->load('info') 关联,这种方法的好处是,避免了
n+1 的问题
函数、
类方法的依赖注入正确使用姿势
1 2 3 4 5 6 7 8 9 10 11 12 13 class TestService public $name = 'testService' ; } function test (TestService $testService ) var_dump ($testService ->name); } app ()->call ('test' );
1 2 3 4 5 6 7 8 9 10 class TestService public function test (stdClass $stdClass { var_dump ($stdClass ); } } app ()->call ('TestService@test' );
最后推荐一个好东西:Laravel
5.1 LTS 速查表