Golang 里的 context
context 的作用
go 的编程中,常常会在一个 goroutine 中启动多个 goroutine,然后有可能在这些 goroutine 中又启动多个 goroutine。
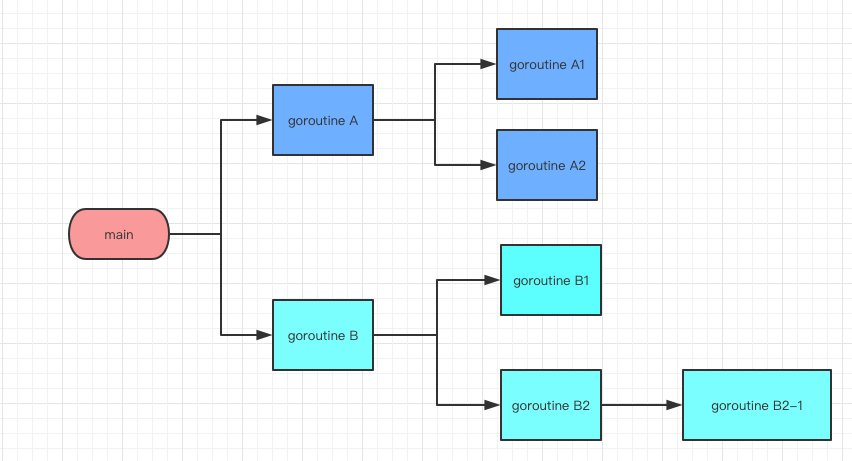
如上图,在 main 函数中,启动了一个 goroutine A 和 goroutine B,然后 goroutine A 中又启动了 goroutine A1 和 goroutine A2,goroutine B 中也是。
有时候,我们可能想要取消当前的处理,这个时候自然而然的也要取消子协程的执行进程。这个时候就需要一种机制来做这件事。context 就是设计来做这件事的。
比如在 web 应用中,当子协程的某些处理时间过长的时候,我们可能想要终止下游的处理,防止协程长期占用资源。保证其他客户端的请求正常处理。
context 的不同类型
context.Background
往往用做父 context,比如在 main 中定义的 context,然后在 main 中将这个 context 传递给子协程。
context.TODO
不需要使用什么类型的 context 的时候,使用这个 context.TODO
context.WithTimeout
我们需要对子 goroutine 做一些超时控制的时候,使用这个 context,比如超过多少秒就不再做处理。
context.WithDeadline
和 context.WithTimeout 类似,只不过参数是一个 time.Time,而不是 time.Duration
context.WithCancel
如果在父 goroutine 里面需要在某些情况下取消执行的时候,可以使用这种 context。
实例
context.Background
1 | package main |
在 main 入口里顶层的 context 使用 context.Background,子 goroutine
里面可以针对实际情况基于父 context 派生新的
context,比如,加入如果需要对子 goroutine
做一些条件性的取消操作,就可以像上面那样使用
ctx3, cancel := context.WithCancel(ctx2) 来基于父 context
创建一个新的 context,然后我们可以通过 cancel 来给子 goroutine
发送取消信号。
注意这里的用语,这里说发送取消信号,因为事实上是否取消后续操作的控制权还是在子 goroutine 里面。但是子 goroutine 有义务停止当前 goroutine 的操作。
个人觉得一个原因是,可能子 goroutine 里面有一些清理操作需要进行,比如写个 Log 说当前操作被取消了,这种情况下直接强行取消并不是很好的选择,所以把控制权交给子 goroutine。
这一点可能在大多数文章里面可能没有提到,但是笔者觉得如果明白了这一点的话,对于理解 context 的工作机制很有帮助。
这种机制的感觉有点像是,虽然你有权力不停止当前操作,但是你有义务去停止当前的处理,给你这种权力只是为了让你有点反应时间。
context.TODO
这个就跳过吧,好像没什么好说的
context.WithTimeout
1 | func ExampleContextWithTimeout() { |
context.WithDeadline
1 | func ExampleContextWithDeadline() { |
context.WithCancel
1 | func ExampleContextWithCancel() { |
其实我们可以发现,context.WithTimeout 和 context.WithDeadline 也返回了一个 cancelFunc,context.WithCancel 返回的 cancelFunc 和这个的效果一样。
只不过 context.WithTimeout 和 context.WithDeadline 多提供了一个时间上的控制。
总结
golang 中的 context 提供了一种父子 goroutine 之间沟通的机制
context.WithTimeout、context.WithDeadline、context.WithCancel 都返回一个新的 context 和一个 cancelFunc,cancelFunc 可以用来取消子 goroutine
goroutine 最终是否停止取决于子 goroutine 本身,但是我们有必要去监听 ctx.Done() 来根据父 goroutine 传递的信号来决定是否继续执行还是直接返回。