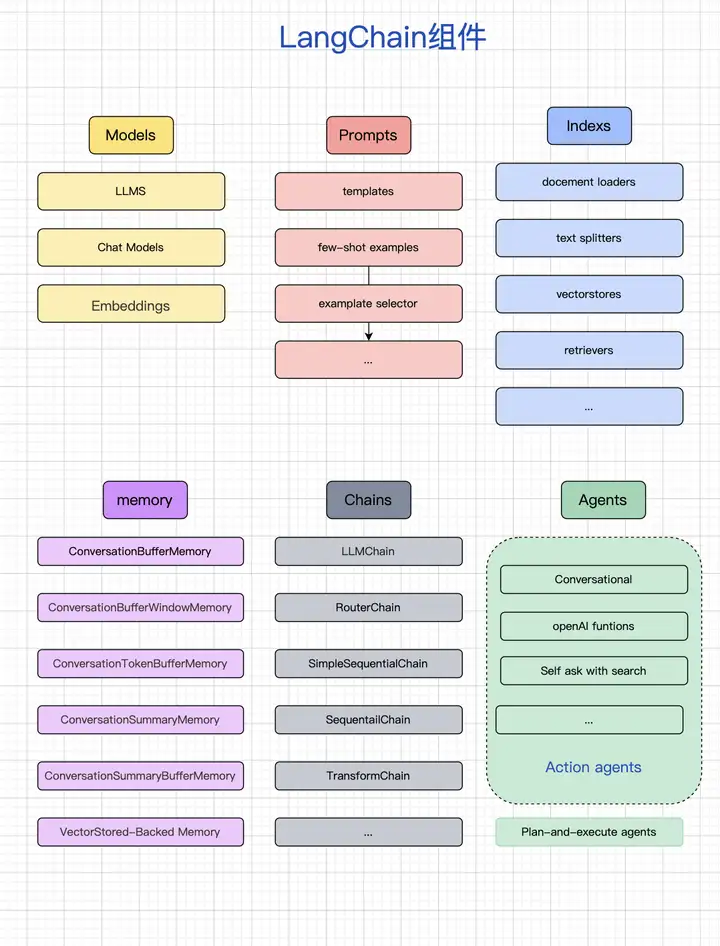
在 langchain
中,我们可以将一个任务拆分为多个更简单的子任务,不同的子任务使用不同的
LLM 来处理。
正如在软件工程中,将复杂系统分解为一组模块化组件是一种良好实践一样,对于提交给
GPT 的任务也是如此。
复杂任务的错误率往往高于简单任务。此外,复杂任务通常可以重新定义为简单任务的工作流程,
其中较早任务的输出用于构建较晚任务的输入。
再有一种场景是,有些简单的任务,我们可以交给一些效率更高、更廉价的
LLM 进行处理。 而对于复杂一点的任务,我们可以交给一些能力更强的 LLM
进行处理(同时可能更加昂贵)。
这就等同于一个团队中,有些任务可以交给实习生,有些任务可以交给初级工程师,有些任务可以交给高级工程师。
如果一些简单的任务交给高级工程师,可能会浪费资源,而一些复杂的任务交给实习生,可能会导致任务无法完成。
又或者,不同的 LLM
的能力是不一样的(比如一些模型能处理图像,一些模型只能处理文本),我们拆分任务,让不同的
LLM 分别处理,最后将结果整合。
实例一
在下面这个例子中,我们使用了两个 LLM:零一万物的
yi-large 和 OpenAI 的 gpt-3.5-turbo。
要处理的任务是,根据用户输入的内容:
总结其内容。
将总结的内容翻译成英文。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 from langchain_core.output_parsers import StrOutputParserfrom langchain_core.prompts import PromptTemplatefrom langchain_openai import ChatOpenAIopenai_llm = ChatOpenAI( model_name="gpt-3.5-turbo" , temperature=0 , max_tokens=200 , api_key="your key" , base_url="https://api.openai-hk.com/v1" , ) summarizing_prompt_template = """ 总结以下文本为一个 20 字以内的句子: --- {content} """ prompt = PromptTemplate.from_template(summarizing_prompt_template) summarizing_chain = prompt | openai_llm | StrOutputParser() yi_llm = ChatOpenAI( model_name="yi-large" , temperature=0 , max_tokens=200 , api_key="your key" , base_url="https://api.lingyiwanwu.com/v1" , ) translating_prompt_template = """将{summary}翻译成英文""" prompt = PromptTemplate.from_template(translating_prompt_template) translating_chain = prompt | yi_llm | StrOutputParser() overall_chain = summarizing_chain | translating_chain response = overall_chain.invoke({"content" : "这是一个测试。" }) print (response)
输出:
在这个例子中,我们依然是使用了管道操作的方式,将两个 LLM
连接在一起,最终得到了我们想要的结果。
实例二
在上面例子的基础上,再调用一个新的模型,并且显示
langchain 的实际处理过程。
下面使用了 LLMChain,因为上面的
prompt | openai_llm 返回的结果并不能作为
SequentialChain 的参数。 同时也加上了
verbose=True 参数,以便查看处理过程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 from langchain.chains.llm import LLMChainfrom langchain.chains.sequential import SequentialChainfrom langchain_core.prompts import PromptTemplatefrom langchain_openai import ChatOpenAIopenai_llm = ChatOpenAI( model_name="gpt-3.5-turbo" , temperature=0 , max_tokens=200 , api_key="your key" , base_url="https://api.openai-hk.com/v1" , ) summarizing_prompt_template = """ 总结以下文本为一个 20 字以内的句子: --- {content} """ prompt = PromptTemplate.from_template(summarizing_prompt_template) summarizing_chain = LLMChain(llm=openai_llm, prompt=prompt, output_key="summary" , verbose=True ) yi_llm = ChatOpenAI( model_name="yi-large" , temperature=0 , max_tokens=200 , api_key="your key" , base_url="https://api.lingyiwanwu.com/v1" , ) translating_prompt_template = """将{summary}翻译成英文""" prompt = PromptTemplate.from_template(translating_prompt_template) translating_chain = LLMChain(llm=yi_llm, prompt=prompt, output_key="translated" , verbose=True ) zhipu_llm = ChatOpenAI( model_name="glm-4" , temperature=0 , max_tokens=200 , api_key="your key" , base_url="https://open.bigmodel.cn/api/paas/v4/" , ) translating_prompt_template = """统计{translated}的长度""" prompt = PromptTemplate.from_template(translating_prompt_template) stat_chain = LLMChain(llm=zhipu_llm, prompt=prompt, output_key="result" , verbose=True ) overall_chain = SequentialChain( chains=[summarizing_chain, translating_chain, stat_chain], input_variables=["content" ], output_variables=["result" ], verbose=True ) response = overall_chain.invoke({"content" : "这是一个测试。" }) print (response)
输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 > Entering new SequentialChain chain... > Entering new LLMChain chain... Prompt after formatting: 总结以下文本为一个 20 字以内的句子: --- 这是一个测试。 > Finished chain. > Entering new LLMChain chain... Prompt after formatting: 将这是一个测试。翻译成英文 > Finished chain. > Entering new LLMChain chain... Prompt after formatting: 统计This is a test.的长度 > Finished chain. > Finished chain. {'content': '这是一个测试。', 'result': '字符串"This is a test."的长度是14个字符。这里包括了空格和句号。'}
输出的模式为:每使用一个 chain,都会输出一行
Entering new LLMChain chain...,在处理完成后,会输出处理结果,接着输出
Finished chain.。
总结
在 langchain 中,我们可以将多个 LLM
连接在一起,形成一个链式请求,以便处理更复杂的任务。
将不同的任务交给不同的 LLM 处理,可以提高效率,降低成本。