from langchain_openai import ChatOpenAI llm = ChatOpenAI( model_name="gpt-4", temperature=0.7, max_tokens=1000, ) from langchain.agents import Tool
tools = [ Tool( name="Get current info", func=query_web, description="""only invoke it when you need to answer question about realtime info. And the input should be a search query.""" ), Tool( name="query spotmax info", func=qa, description="""only invoke it when you need to get the info about spotmax/maxgroup/maxarch/maxchaos. And the input should be the question.""" ), Tool( name="create an image", func=create_image, description="""invoke it when you need to create an image. And the input should be the description of the image.""" ) ] from langchain.memory import ConversationBufferWindowMemory from langchain.agents import ZeroShotAgent, AgentExecutor from langchain.chains.llm import LLMChain
prefix = """Have a conversation with a human, answering the following questions as best you can. You have access to the following tools:""" suffix = """Begin!" {chat_history} Question: {input} {agent_scratchpad}"""
AgentExecutor
的处理过程如下(Thought -> Action -> Observation -> Thought -> Final Answer):
1 2 3 4 5 6 7 8 9 10 11 12 13
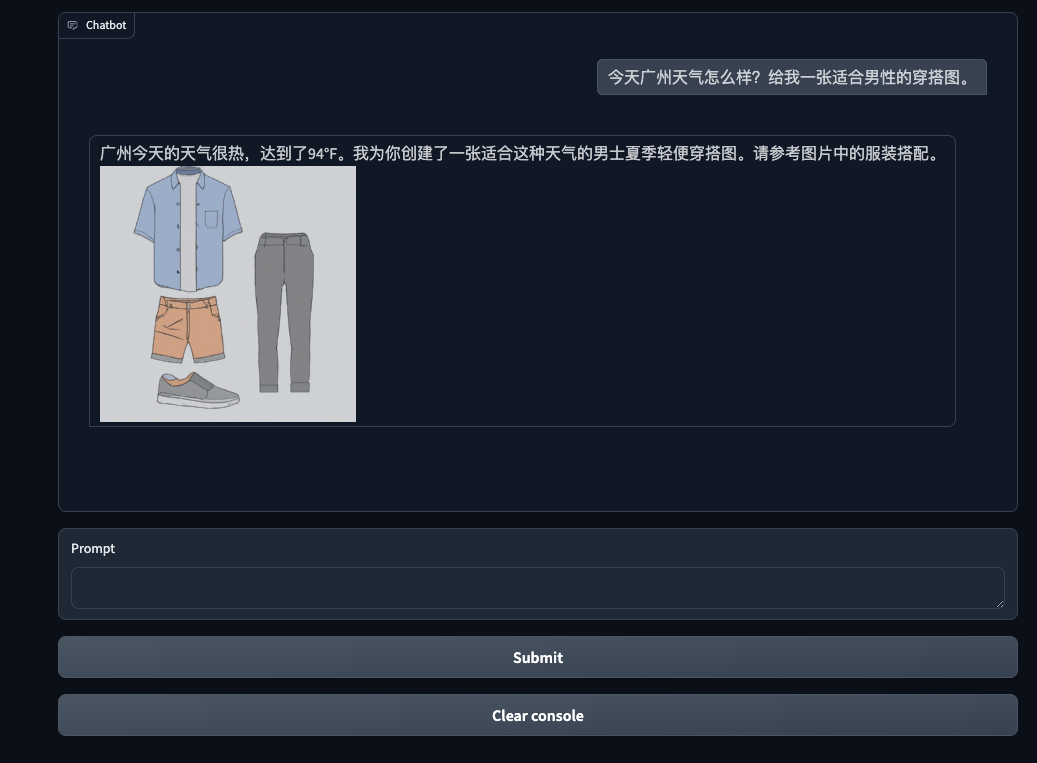
> Entering new AgentExecutor chain... Thought: The question is asking for the current weather in Guangzhou and a male outfit recommendation. I can use the 'Get current info' tool to find the weather, and the 'create an image' tool to generate the outfit image. Action: Get current info Action Input: Guangzhou weather today Observation: 94°F Thought:The weather in Guangzhou is quite hot today. Now I need to think of an outfit that would be suitable for such warm weather. Action: create an image Action Input: A light summer outfit for men suitable for 94°F weather Observation:  Thought:I now have the final answer. Final Answer: 广州今天的天气很热,达到了94°F。我为你创建了一张适合这种天气的男士夏季轻便穿搭图。请参考图片中的服装搭配。
> Finished chain.
我们可以看到在我提这个问题的时候,它做了如下操作:
思考,然后发现需要获取今天广州的天气,这是 LLM 不懂的,所以使用了
Get current info 工具。
获取到了天气信息之后,思考,然后发现需要生成一张图片,而我们有一个
create an image 工具,因此使用了这个工具来生成图片
最终返回了今天广州的天气状况以及一张图片。
当然,我们也可以问它关于本地知识库的问题,比如 “什么是
spotmax?”(根据你自己的 pdf 提问,这里只是一个示例)
from langchain_openai import ChatOpenAI llm = ChatOpenAI( model_name="gpt-4", temperature=0.7, max_tokens=1000, ) from langchain.agents import Tool
tools = [ Tool( name="Get current info", func=query_web, description="""only invoke it when you need to answer question about realtime info. And the input should be a search query.""" ), Tool( name="query spotmax info", func=qa, description="""only invoke it when you need to get the info about spotmax/maxgroup/maxarch/maxchaos. And the input should be the question.""" ), Tool( name="create an image", func=create_image, description="""invoke it when you need to create an image. And the input should be the description of the image.""" ) ] from langchain.memory import ConversationBufferWindowMemory from langchain.agents import ZeroShotAgent, AgentExecutor from langchain.chains.llm import LLMChain
prefix = """Have a conversation with a human, answering the following questions as best you can. You have access to the following tools:""" suffix = """Begin!" {chat_history} Question: {input} {agent_scratchpad}"""
defrecognize_intent(text: str): response = llm.invoke([ SystemMessage("""Recognize the intent from the user's input and format output as JSON string. The output JSON string includes: "intention", "parameters" """), HumanMessage(text) ]) return response.content
from langchain.agents import initialize_agent, AgentType from langchain_community.utilities import GoogleSerperAPIWrapper from langchain_core.tools import Tool from langchain_openai import ChatOpenAI
import os # https://serper.dev os.environ['SERPER_API_KEY'] = 'your serper api key'
> Entering new AgentExecutor chain... Thought: To determine what to wear in Guangzhou today, I need to check the current weather conditions. I'll use the query_web tool to find the latest weather information.
Observation: 83°F Thought:Thought: The temperature in Guangzhou is 83°F, which indicates a warm day. I should recommend light clothing suitable for such weather.
Final Answer: 今天广州的天气适合穿轻薄的衣服,比如短袖衬衫、短裤或者连衣裙。记得涂抹防晒霜,戴上太阳帽和太阳镜来保护自己免受阳光直射。
from langchain.agents import initialize_agent, AgentType from langchain_community.utilities import GoogleSerperAPIWrapper from langchain_core.tools import Tool from langchain_openai import ChatOpenAI
import os # https://serper.dev os.environ['SERPER_API_KEY'] = 'your serper api key'
from langchain_core.chat_history import InMemoryChatMessageHistory from langchain_core.messages import AIMessage from langchain_core.runnables import RunnableWithMessageHistory from langchain_openai import ChatOpenAI from langchain.memory import ConversationBufferWindowMemory
from langchain_core.chat_history import InMemoryChatMessageHistory from langchain_core.messages import AIMessage from langchain_core.runnables import RunnableWithMessageHistory from langchain_openai import ChatOpenAI from langchain.memory import ConversationBufferWindowMemory
from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import PromptTemplate from langchain_openai import ChatOpenAI
prompt_template = "What is a good name for a company that makes {product}?" prompt = PromptTemplate(template=prompt_template, input_variables=["product"])
如果熟悉 linux 命令行的话,我们会知道,其实 linux 中的管道操作符也是
|。与之类似的,langchain 重载 |
操作符也是为了抽象管道这种操作。 在这行代码中,prompt
的输出会作为 llm 的输入,同时,llm
的输出也会作为 StrOutputParser()
的输入。然后最终得到多个管道处理后的结果。
invoke 实现管道操作的源码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
# invoke all steps in sequence try: for i, step inenumerate(self.steps): # mark each step as a child run config = patch_config( config, callbacks=run_manager.get_child(f"seq:step:{i+1}") ) if i == 0: input = step.invoke(input, config, **kwargs) else: input = step.invoke(input, config) # finish the root run except BaseException as e: run_manager.on_chain_error(e) raise