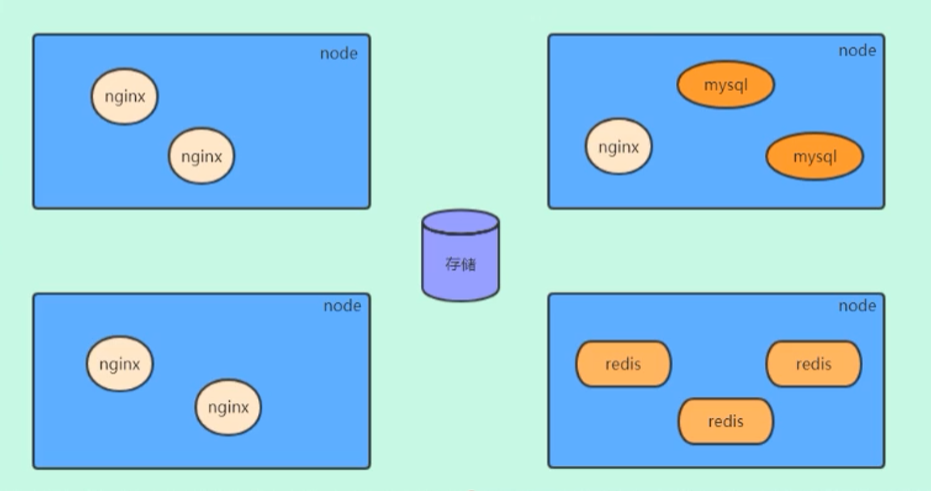
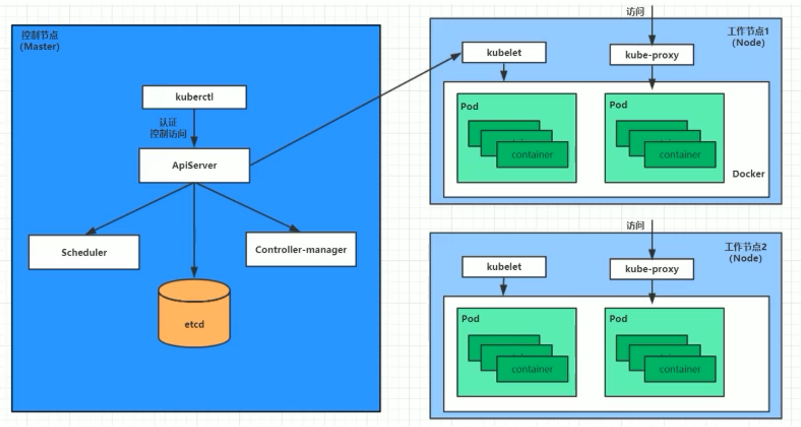
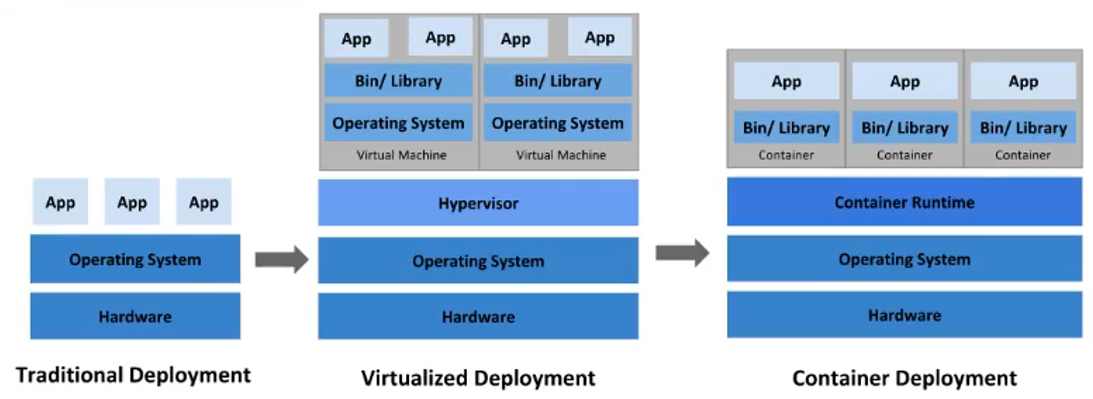
环境规划
集群类型
kubernetes
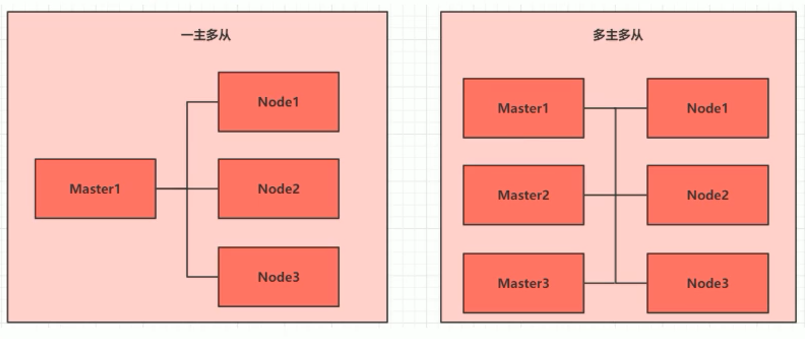
集群大体上分为两类:一主多从 和多主多从 。
一主多从:一台 Master 节点和多台 Node
节点,搭建简单,但是有单机故障风险,适合用于测试环境。
多主多从:多台 Master 节点和多台 Node
节点,搭建麻烦,安全性高,适合用于生产环境。
cluster
说明:为了测试简单,本次搭建的是一主两从类型的集群。
安装方式
kubernetes 有多种部署方式,目前主流的方式有
kubeadm、minikube、二进制包。
minikube:一个用于快速搭建单节点 kubernetes 的工具
kubeadm:一个用于快速搭建 kubernetes 集群的工具
二进制包:从官网下载每个组件的二进制包,依次去安装,此方式对于理解
kubernetes 组件更加有效
说明:现在需要安装 kubernetes
的集群环境,但是又不想过于麻烦,所以使用 kubeadm 方式
主机规划
Master
192.168.235.100
CentOS7.5 基础设施服务器
2颗CPU 2G内存 50G硬盘
Node1
192.168.235.101
CentOS7.5 基础设施服务器
2颗CPU 2G内存 50G硬盘
Node2
192.168.235.102
CentOS7.5 基础设施服务器
2颗CPU 2G内存 50G硬盘
环境搭建
本次环境搭建需要安装三台 linux 系统(一主二从),内置 CentOS7.5
系统,然后在每台 linux 中分别安装 docker,kubeadm,kubelet,kubectl
程序。
主机安装
安装虚拟机过程注意下面选项的设置:
操作系统环境:CPU(2C) 内存(2G)硬盘(50G)
语言选择:中文简体
软件选择:基础设施服务器
分区选择:自动分区
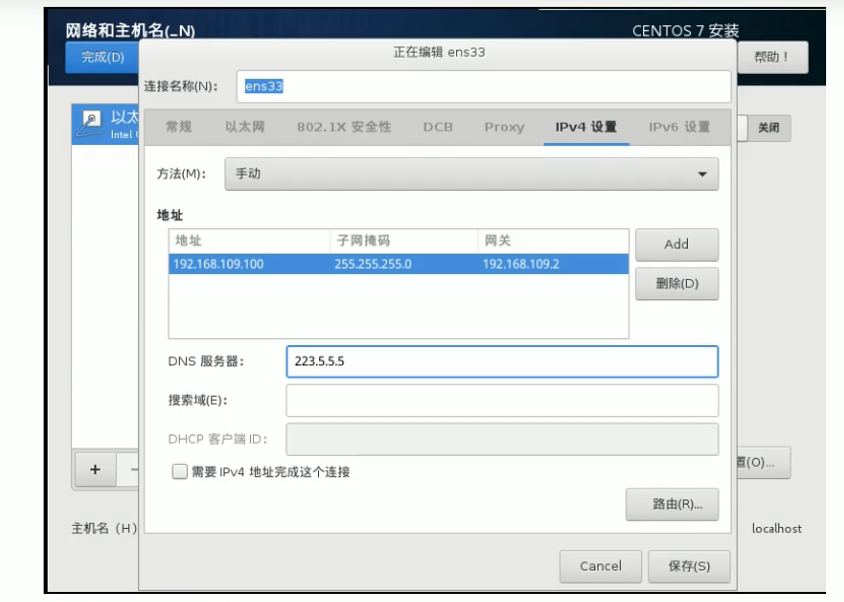
网络配置:按照下面配置网络地址信息(IPv4)
网络地址:192.168.235.100(每台主机都不一样 分别为
100、101、102)(vmware的编辑->虚拟网络编辑器里面第二个网卡可以看到本地的虚拟机网段是什么)
子网掩码:255.255.255.0 默认网关:192.168.235.2 DNS:223.5.5.5
vm-network
常规里面的第一个勾上。
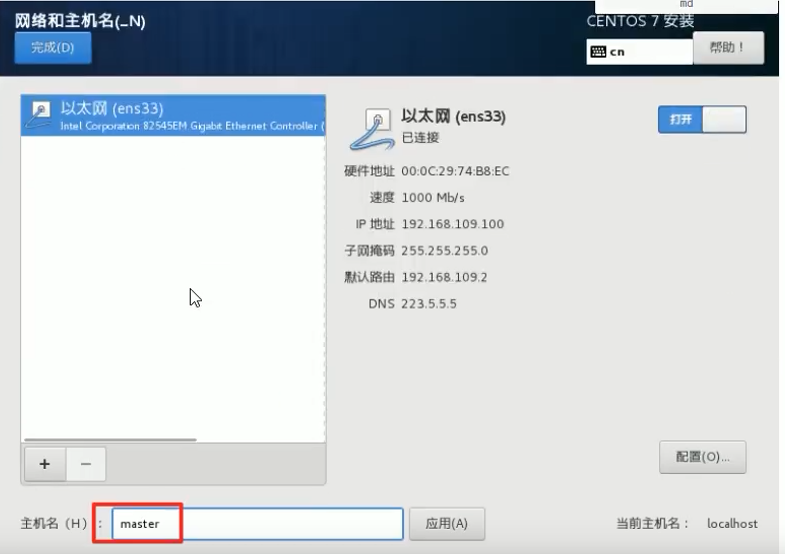
master节点:master node节点:node1 node节点:node2
vm-hostname
环境初始化
检查操作系统的版本
1 2 3 # 此方式安装 kubernetes 集群要求 CentOS 版本在 7.5 或以上 [root@master ~]# cat /etc/redhat-release CentOS Linux release 7.5.1804 (Core)
主机名解析
为了方便后面集群节点间的直接调用,再配置一下主机名解析,企业中推荐使用内部
DNS 服务器
1 2 3 4 # 主机名解析 编辑三台服务器的 /etc/hosts 文件,添加下面内容 192.168.235.100 master 192.168.235.101 node1 192.168.235.102 node2
时间同步
kubernetes 要求集群中的节点时间必须精确一致,这里直接使用
chronyd 服务从网络同步时间。
企业中建议配置内部时间同步服务器。
1 2 3 4 5 6 7 # 启动 chronyd 服务 [root@master ~]# systemctl start chronyd # 设置 chronyd 服务开机启动 [root@master ~]# systemctl enable chronyd # chronyd 服务启动稍等几秒钟,就可以使用 date 命令验证时间了 [root@master ~]# date 2021年 11月 27日 星期六 09:28:07 CST
禁用 iptables 和 firewalld 服务
kubernetes 和 docker 在运行中会产生大量的 iptables
规则,为了不让系统规则跟它们混淆,直接关闭系统的规则
1 2 3 4 5 6 7 8 9 10 11 # 1 关闭 firewalld 服务 [root@master ~]# systemctl stop firewalld [root@master ~]# systemctl disable firewalld Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service. Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service. # 2 关闭 iptables 服务 [root@master ~]# systemctl stop iptables Failed to stop iptables.service: Unit iptables.service not loaded. [root@master ~]# systemctl disable iptables Failed to execute operation: No such file or directory
禁用 selinux
selinux 是 linux
系统下的一个安全服务,如果不关闭它,在安装集群中会产生各种各样的奇葩问题。
1 2 3 # 编辑 /etc/selinux/config 文件,修改 SELINUX 的值为 disabled # 注意修改完毕之后需要重启 linux 服务 SELINUX=disabled
禁用 swap 分区
swap
分区指的是虚拟内存分区,它的作用是在物理内存使用完之后,将磁盘空间虚拟成内存来使用。
启用 swap 设备会对系统的性能产生非常负面的影响,因此
kubernetes 要求每个节点都要禁用 swap 设备。
但是如果因为某些原因确实不能关闭 swap
分区,就需要在集群安装过程中通过明确的参数进行配置说明。
1 2 3 4 # 编辑分区配置文件 /etc/fstab,注释掉 swap 分区一行 # 注意修改完毕之后需要重启 linux 服务 UUID=0a79fea5-0afa-49a7-9c5e-53c37a76980f /boot xfs defaults 0 0 #/dev/mapper/centos-swap swap swap defaults 0 0
修改 linux 的内核参数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 # 修改 linux 的内核参数,添加网桥过滤和地址转发功能 # 编辑 /etc/sysctl.d/kubernetes.conf 文件,添加如下配置: net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_forward = 1 # 重新加载配置 [root@master ~]# sysctl -p # 加载网桥过滤模块 [root@master ~]# modprobe br_netfilter # 查看网桥过滤模块是否加载成功 [root@master ~]# lsmod | grep br_netfilter br_netfilter 22256 0 bridge 146976 1 br_netfilter
配置 ipvs 功能
在 kubernetes 中 service 有两种代理模型,一种是基于
iptables 的,一种是基于 ipvs 的。
两者比较的话,ipvs
的性能明显要高一些,但是如果要使用它,需要手动载入 ipvs
模块。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 # 1 安装 ipset 和 ipvsadm [root@master ~]# yum install ipset ipvsadm -y # 2 添加需要加载的模块写入脚本文件 [root@master ~]# cat <<EOF > /etc/sysconfig/modules/ipvs.modules #!/bin/bash modprobe -- ip_vs modprobe -- ip_vs_rr modprobe -- ip_vs_wrr modprobe -- ip_vs_sh modprobe -- nf_conntrack_ipv4 EOF # 3 为脚本文件添加执行权限 [root@master ~]# chmod +x /etc/sysconfig/modules/ipvs.modules # 4 执行脚本文件 [root@master ~]# /bin/bash /etc/sysconfig/modules/ipvs.modules # 5 查看对应的模块是否加载成功 [root@master ~]# lsmod | grep -e ip_vs -e nf_conntrack_ipv4
重启服务器
上面步骤完成之后,需要重新启动 linux 系统。
安装 docker
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 # 1 切换镜像源 [root@master ~]# wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo # 2 查看当前镜像源中支持的 docker 版本 [root@master ~]# yum list docker-ce --showduplicates # 3 安装指定版本的 docker-ce # 必须指定 --setopt=obsoletes=0,否则 yum 会自动安装更高版本 [root@master ~]# yum install --setopt=obsoletes=0 docker-ce-18.06.3.ce-3.el7 -y # 4 添加一个配置文件 # Docker 在默认情况下使用 Cgroup Driver 为 cgroupfs,而 kubernetes 推荐使用 systemc 来代替 cgroupfs [root@master ~]# mkdir /etc/docker [root@master ~]# cat <<EOF > /etc/docker/daemon.json { "exec-opts": ["native.cgroupdriver=systemd"], "registry-mirrors": ["https://kn0t2bca.mirror.aliyuncs.com"] } EOF # 5 启动 docker [root@master ~]# systemctl restart docker # 6 检查 docker 状态和版本 [root@master ~]# docker version
安装 kubernetes 组件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 # 由于 kubernetes 的镜像源在国外,速度比较慢,这里切换成国内的镜像源 # 编辑 /etc/yum.repos.d/kubernetes.repo,添加下面的配置 [kunernetes] name=Kubernetes baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=0 repo_gpgcheck=0 gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg # 安装 kubeadm、kubelet 和 kubectl [root@master ~]# yum install --setopt=obsoletes=0 kubeadm-1.17.4-0 kubelet-1.17.4-0 kubectl-1.17.4-0 -y # 配置 kubelet 的 cgroup # 编辑 /etc/sysconfig/kubelet,添加下面的配置 KUBELET_CGROUP_ARGS="--cgroup-driver=systemd" KUBE_PROXY_MODE="ipvs" # 设置 kubelet 开机自启 [root@master ~]# systemctl enable kubelet
准备集群镜像
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 # 在安装 kubernetes 集群之前,必须要提前准备好集群需要的镜像,所需镜像可以通过下面命令查看 [root@master ~]# kubeadm config images list # 下载镜像 # 此镜像在 kubernetes 的仓库中,由于网络原因,无法连接,下面提供了一种替代方案 images=( kube-apiserver:v1.17.4 kube-controller-manager:v1.17.4 kube-scheduler:v1.17.4 kube-proxy:v1.17.4 pause:3.1 etcd:3.4.3-0 coredns:1.6.5 ) for imageName in ${images[@]}; do docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/$imageName docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/$imageName k8s.gcr.io/$imageName docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/$imageName done
集群初始化
下面开始对集群进行初始化,并将 node 节点加入到集群中
下面的操作只需要在 master 节点上执行即可
1 2 3 4 5 6 7 8 9 10 11 # 创建集群 [root@master ~]# kubeadm init \ --kubernetes-version=v1.17.4 \ --pod-network-cidr=10.244.0.0/16 \ --service-cidr=10.96.0.0/12 \ --apiserver-advertise-address=192.168.235.100 # 创建必要文件(注意看初始化成功后的输出) [root@master ~]# mkdir -p $HOME/.kube [root@master ~]# cp -i /etc/kubernetes/admin.conf $HOME/.kube/config [root@master ~]# chown $(id -u):$(id -g) $HOME/.kube/config
下面的操作只需要在 node 节点上执行即可
1 2 3 4 5 6 7 8 9 10 11 12 13 # 将 node 节点加入集群 [root@master ~]# kubeadm join 192.168.235.100:6443 \ --token i50jyb.m7n0z8wxwecqvvs1 \ --discovery-token-ca-cert-hash sha256:51c607f11b6f9077e073ccf9111047c7838b1e8f7ef52690d8c9b3fb6d9b67b3 # 这里 token 和 hash 取值看 master 初始化的输出。 # 查看集群状态 此时集群的状态为 NotReady,这是因为还没有配置网络插件 [root@master ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION master NotReady master 5m52s v1.17.4 node1 NotReady <none> 23s v1.17.4 node2 NotReady <none> 2s v1.17.4
安装网络插件
kubernetes 支持多种网络插件,比如 flannel、calico、canal
等等,任选一种使用即可,本次选择 flannel
下面操作依旧只在 master 节点执行即可,插件使用的是 DaemonSet
的控制器,它会在每个节点上都运行
1 2 3 4 5 6 7 8 9 10 11 12 # 获取 flannel 的配置文件 [root@master ~]# wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml # 使用配置文件启动 flannel [root@master ~]# kubectl apply -f kube-flannel.yml # 稍等片刻,再次查看集群节点的状态 [root@master ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION master Ready master 16m v1.17.4 node1 Ready <none> 11m v1.17.4 node2 Ready <none> 10m v1.17.4
至此,kubernetes 的集群环境搭建完成。
服务部署
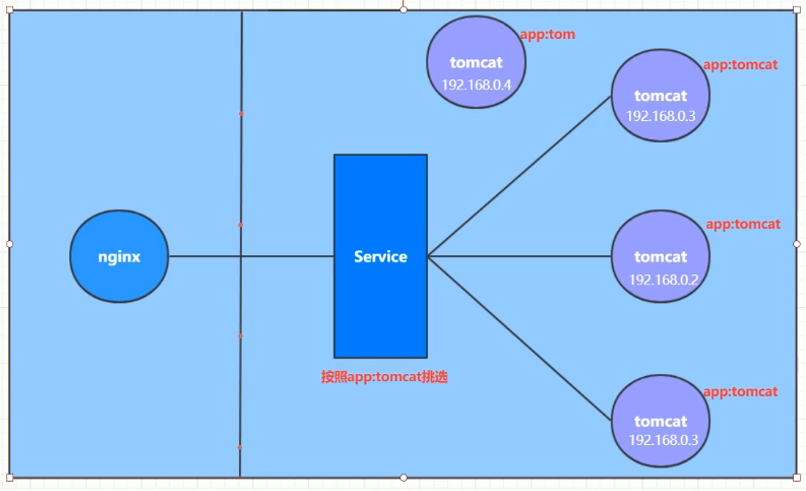
接下来在 kubernetes 集群中部署一个 nginx
程序,测试下集群是否在正常工作。
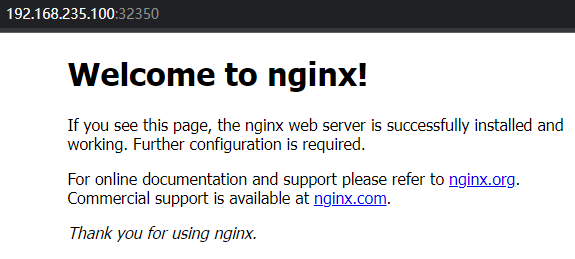
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 # 部署 nginx [root@master ~]# kubectl create deployment nginx --image=nginx:1.14-alpine deployment.apps/nginx created # 暴露端口 [root@master ~]# kubectl expose deployment nginx --port=80 --type=NodePort service/nginx exposed # 查看服务状态 [root@master ~]# kubectl get pods,svc NAME READY STATUS RESTARTS AGE pod/nginx-6867cdf567-z6jzl 1/1 Running 0 17s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 19m service/nginx NodePort 10.105.209.91 <none> 80:32350/TCP 8s # 最后在电脑上访问下部署的 nginx 服务
nginx-svc