go validator 值为 0 required 验证
错误示范
1 | package main |
在这个例子中,虽然我们的 State
字段传入了值,但是验证却不通过。
正确示范
在使用 go-playground/validator/v10
验证一些空值的时候,需要使用指针类型。
1 | package main |
1 | package main |
在这个例子中,虽然我们的 State
字段传入了值,但是验证却不通过。
在使用 go-playground/validator/v10
验证一些空值的时候,需要使用指针类型。
1 | package main |
今天偶然刷到一个漫画家蔡志忠的访谈视频,下面是他的原话:
为什么努力是没有用的?老师或父母老是说努力努力就会走到巅峰——才怪。如果这样,不是所有人都走上巅峰了吗?没有人开始不努力,为什么后来不努力,因为努力没有效果。人生不是走斜坡,你持续走就可以走到巅峰;人生像走阶梯,每一阶有每一阶的难点,学物理有物理的难点,学漫画有漫画的难点,你没有克服难点,再怎么努力都是原地跳。所以当你克服难点,你跳上去就不会下来了。就像你学会语文,即使你十年不讲,碰到状况就会讲;就像学脚踏车,十年没骑,碰到脚踏车一上去就可以上手一样。
当然,虽然蔡老师表面上说努力没有用,但蔡志忠老师的意思应该是「不能盲目的努力」,不能用战术上的勤奋来掩盖战略上的懒惰。
其实这个观点前段时间在池建强老师的直播间也听到,只不过当时好像并没有真的懂了,今天看到蔡志忠老是说的 人生像走阶梯,每一阶有每一阶的难点,学物理有物理的难点,学漫画有漫画的难点,你没有克服难点,再怎么努力都是原地跳 之后,再结合一下自己以往经历,总算是懂了。
下面就结合自己所在领域聊一下自己的理解吧。
过去几年里,自己虽然作为计算机科班出身的人,但是一直都没有认真好好学那些计算机的基础课程,也在找工作时候刻意躲开需要考查算法的岗位,因为自己懂得不多,而且总是觉得太难而没有去学。
不过去年大病一场之后,自己也想明白了,如果自己一直都是这样,永远也突破不了自己,因此开始持续刷了 6 个月的 leetcode,总算把常用的数据结构算法熟悉了一些。
虽然还不到非常熟练的地步,但是也比之前的自己好了好多倍了。
就像蔡志忠老师说的,其实计算机领域中也有其难点,如下就是:
除了这些,软件设计、重构、面向对象设计这些也是其中的难点,不过上面这几个能在我们面临一些具体问题的时候会更有用,而软件设计这些则对我们写好代码、写出可维护、可扩展的代码非常有用。
作为科班出身的我,对上面都不是很熟悉。更不要说,目前中国程序员行业还有很多转行过来的人,这些人有很多可能连cpu、内存、磁盘这些都不太懂。
但正是这些东西,可以让我们更快地去解决技术上碰到的一些难题。比如很简单的一些性能上问题,需要多次搜索的时候,构建出一个 hash 比我们每次去做 O(n) 的循环效率高数百倍甚至更高。
过去几年里,虽然自己一直有在学习,但是正如蔡志忠老师说的,我那些 努力 是没有用的,因为自己学的都是简单的东西, 比如一门新的语言,然后用这门新语言写一些 demo 之类的,虽然挺好玩,但说实话,并没有感觉自己能力上有太大的突破。
然后认真看了自己平时用的框架的源代码,看过了好几遍,里面的设计、实现都有比较深入的了解,但是还是那句话, 看了这些除了能熟练应对工作中技术上的问题之外,自己的能力上好像并没有太大的突破,有种学了很多东西依然原地踏步的感觉。
总之,就是没有突破自己目前所在的层级,虽然有时候自己看起来好像挺牛逼,好多问题都能很快解决,但是平时做的东西,换个人做也是可以的, 只不过给我做的话,我会考虑更多性能、代码整洁之类的问题,然后可以比较快地解决问题。本质上来讲自己跟他们是一样的,只是好了一点而已。
今年年初的时候,看到左晖的一个访谈,其实是一本书,叫《做难而正确的事》。里面有个观点就是,如果让他选择一件容易和一件难的事,他会选择那件难的事,因为可能成功率更高。
那段时间刚好在刷 leetcode,代码随想录那个网站里面那些 leetcode 题目从头到尾刷了一遍,因为自己当初没学好,因此刷起来还是有点困难,但还是坚持下来了。
现在的自己也依然在坚持做那些难而正确的事,老老实实学好这些计算机领域的基础课程。在这个过程,其实也收获了很多,也慢慢走在了上台阶的路上。
好了,该说的说完了,太久没写非技术的文章了,写了一下发现自己的作文水平好像不太好,那就这样吧。
samber/lo 是一个 go 里面类似 js 里的 lodash 的库,可以让我们很方便地对切片做一些诸如 filter、unique 等操作的库。
1 | go get github.com/samber/lo@v1 |
最新版本支持 go1.18+,也就是可以使用泛型,这样就给开发者带来了更大的便利了。
1 | even := lo.Filter[int]([]int{1, 2, 3, 4}, func(x int, _ int) bool { |
1 | lo.Map[int64, string]([]int64{1, 2, 3, 4}, func(x int64, _ int) string { |
1 | uniqValues := lo.Uniq[int]([]int{1, 2, 2, 1}) |
1 | lo.Chunk[int]([]int{0, 1, 2, 3, 4, 5}, 2) |
imdario/mergo 是一个可以让你合并结构体和 map 的库。
1 | go get github.com/imdario/mergo |
1 | package main |
color 是一个可以让你输出带颜色文本的库。
1 | go get github.com/fatih/color |
1 | // 这会直接输出到控制台 |
效果:
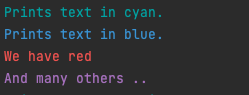
1 | // 创建一个新的 color 对象,然后加上 “下划线” 样式 |
效果:
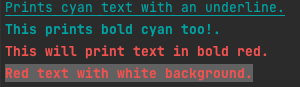
io.Writer
即可):比如文件等1 | // 使用自定义的 `io.Writer` 保存 color 的输出 |
print 函数:PrintFunc1 | // 创建一个新的自定义的 print 函数 |
fprint 函数:FprintFunc1 | // 创建一个自定义的 fprint 函数 |
1 | // SprintFunc 调用的效果是返回一个字符串,而不是直接输出了 |
1 | // 在 `color.Set()` 和 `color.Unset()` 之间的代码会有颜色 |
1 | color.NoColor = true |