gin 核心详解
gin 作为一个非常流行的 go web
框架,以简洁、高效的优势赢得了很多开发者的青睐,今天我们就来看看它的框架核心的一些设计,看看它是如何做到高效的,以及聊聊它的一些设计理念。
当然,如果要从实际开发的角度看,gin 只是能够满足最基本的
web
开发的功能,但是由于其设计简洁,我们可以很方便地在其基础上进行扩展,以实现我们
web 开发中那些很常用的功能, 比如 cache、db
等等。
前言
在探讨 gin 的核心功能之前,我们先来看看一个 web
框架的核心是怎样的。
我们先来看看一个 URL
的结构是怎样的:scheme://host.domain:port/path/to/file,scheme
是协议名称,web 开发里面是 http 或者
https,host.domain 是域名,port
是端口,最后的 /path/to/file
是请求的资源路径(文件路径)。
在二三十年前尚未出现动态页面之前,所有的页面都是静态的页面,然后不同的页面放在不同的
html 文件中,再复杂一点,通过不同文件夹来组织这些 html 文件。
然后在用户要去访问这些页面的时候,先进入的是
index.html,然后在这个 html
文件里面通过不同的超链接跳转到不同的页面去,在我们点击不同的超链接的时候,一个新的请求到达同一个
http 服务器, 然后这个 http 服务器读取文件内容(也就是
/path/to/file 的内容),返回给客户端。
在这一阶段,判断客户端请求内容在哪里是由 http 服务器来处理的,读取请求的数据也是 http 服务器来处理的。
然后经过一段时间发展,开始出现了动态生成网页内容的技术,这个时候,之前代表文件路径的
/path/to/file 现在开始由 web 服务器来动态生成。
具体来说就是 http
服务器只是根据域名跟端口来判断这个请求具体是哪个应用的,然后将请求转发给对应的应用服务器,由应用服务器判断这个文件路径是要请求什么资源,
然后派发给对应的处理逻辑进行处理,并在处理后将数据返回给 http
服务器,最后 http 服务器将数据返回给客户端。
在这一阶段,web 应用做了之前 http 做的一些工作,如根据用户请求的文件路径进行不同的处理,并返回数据。
具体如下图:
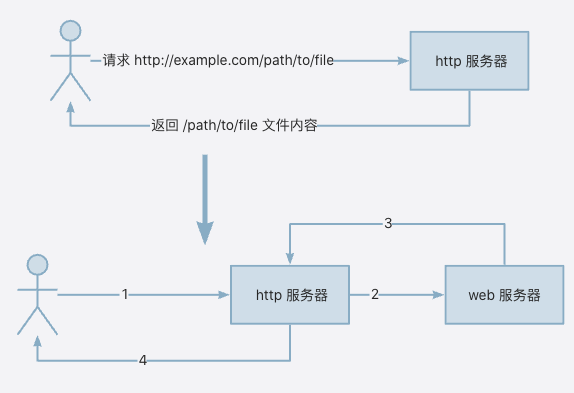
图 2 说明:
- 1:用户请求
http://example.com/path/to/file - 2:http 服务器将请求转发给 web 服务器
- 3: web 服务器处理完请求,将数据返回给 http 服务器
- 4:http 服务器将数据返回给客户端。
图 2 的形式在今天依然是主流,http
服务器,现在大多只会处理静态资源,而动态的请求大多通过反向代理将请求转发给
web 服务器进行处理。当然我们也可以选择不使用 nginx 等 http
服务器,直接在应用服务器里面处理静态资源的请求,这个功能 go 官方提供的
net/http 就有提供。
路由
上面提到了,现在的 http 服务器会将动态资源的请求通过反向代理转发给 web 服务器,所以就出现了一个必须要解决的问题,web 服务器拿到了请求的信息,如何知道应该做点什么来响应客户端的请求?
其实说起来很简单,就是通过判断 URL 里面的
/path/to/file,也就是在远古时代表示文件路径的那一段,在 web
服务器中,它现在不再表示一个静态文件,而是表示客户端想要请求数据的一个标识而已,
具体代表什么,还是看开发者怎么写。
而判断文件路径表示什么的这一操作,有一个我们惯常的叫法
路由,叫这个名字是因为它的功能跟路由器的功能相似吧,路由器是判断网络包应该发往哪一个
IP,而 web 服务器中的路由就是判断请求应该由哪一个函数来处理。
web 服务器要解决的问题是请求交给哪个函数处理,这个功能有个很常见的叫法:"路由"。
gin 应用结构体
在所有的 web
服务器里面,一般都有一个对象表示应用本身,而且往往是一个单例,比如 PHP
框架 Laravel 里面的 app() 返回的
Application,Servlet 里面的
getServletContext,再比如 Spring 里面的
ApplicationContext。
而在 gin 里面,应用实例是 gin.Engine
这个结构体,gin.Engine
里面的属性大多是一些配置项,而其中有一个很关键的属性是
RouterGroup,这个就是 gin
核心的核心,它会处理用户请求,将用户请求派发到具体的方法上处理。
1 | type Engine struct { |
而 RouterGroup 实现了 IRoutes 接口:
1 | type IRoutes interface { |
我们可以看到这个接口的定义很简单,就是定义了不同的 HTTP
请求方法跟请求路径和
HandlerFunc(请求处理函数,一个请求可以有多个)的映射关系。
我们也发现了其中还有 Use 方法, 关于
Use,其实也是 web
服务器必备的功能了,我们可以通过这个方法来定义一些中间件,可以在中间件做鉴权啥的,又或者做一些请求后的处理(中间件分请求处理前调用的中间件和请求处理后调用的中间件)。
我们也发现了,这个 IRoutes 里面所有方法都返回了
IRoutes,因为 gin
里面支持路由分组,我们可以根据前缀来划分不同的分组,对应到业务上可能就是不同的功能模块。
在
gin里面,路由会通过Engine实例来声明,因为Engine嵌套了RouterGroup结构体,路由的功能在RouterGroup中实现。
一个例子:
1 | package main |
在这个例子中,gin.Default() 是 gin
里面创建应用实例的一个方法,另一个方法是
gin.New(),创建了应用实例之后,通过 r.GET
来声明了一个路径为 /ping
的路由,并且这个路由的处理函数里面返回了一个 json 响应。
这个例子很简单,但是一个 web 的核心功能便是如此简单,声明路由(定义接收到不同 uri 请求的时候交给什么方法处理)。
gin 的请求处理流程
上面也说了,路由是 web
服务器的核心功能,当我们抛开所有乱七八糟的功能之后,其实也就只剩下最核心的路由,就如
go 的标准库 net/http,我们要使用 go 启动一个 web
服务器非常简单,几行代码即可:
1 | package main |
在所有的 go web 框架中,请求的处理最终都是由 ServeHTTP
处理,gin 也不例外,让我们抛开 Engine
中一切干扰的因素,只留下最核心的功能:
1 | // gin 实例 |
我们在这里可以看到,gin 通过 sync.Pool
实现了 Context 的复用,这样一来不用每个请求都创建新的
Context 实例了,一定程度上提高了性能。
所以,gin 的请求处理过程是这样的: HTTP 请求到达
gin 的进程之后,交给了 ServeHTTP 处理,而在
ServeHTTP 中,实际的处理方法是
engine.handleHTTPRequest(c)。 在
engine.handleHTTPRequest(c) 方法内部会通过
ResponseWriter 来输出响应给客户端。
handleHTTPRequest 内部实现
下面我们再来深入探索一下 gin 请求处理的核心逻辑:
1 | func (engine *Engine) handleHTTPRequest(c *Context) { |
上面代码写了注释,简单来说处理流程如下: * 前导处理:比如 HTTP
方法统一转换为大写等 * 路由匹配:在 gin
里面,路由的结构是一棵前缀树,当然在这里看不出来。具体实现在
root.getValue 方法中。 * 路由匹配不到,先判断是否是
405,如果也不是 405,那就是 404,不管 404 还是
405,最终都是返回关于请求错误的响应。
在这里,我们可以得知,gin
高效的另一个原因是,它的路由树使用了前缀树,有一些路由匹配实现会使用正则匹配,但是效率肯定不如前缀树高效。
gin 核心其他一些功能
除了上面提到的 Context 和路由,gin
核心也提供了一些其他的功能,比如:
- 白名单机制:对应属性
trustedProxies - 防止 json 劫持的配置:
secureJSONPrefix - 模板渲染:相关属性有
delims、HTMLRender、FuncMap
总结
贴了很多源码,说了大概如下内容:
- web 服务器的核心逻辑就是,接收从客户端或反向代理服务器的请求,然后根据请求路径将其派发给不同的函数进行处理。
gin.Engine是gin框架的应用结构体,其主要包含了路由对象,以及一些应用配置,如白名单、模板配置等。gin通过sync.Pool来保存请求内创建的Context对象,从而实现复用,从而提高性能。gin的路由设计成一棵前缀树,这棵树的根节点是/,根节点下一层的结点是不同的 HTTP 请求方法,如GET、POST等,再往下就是路由的路径了。而且路径并不是简单地根据斜杠分割的,而是使用最大公共前缀(LCP)来作为树的结点。 因为使用了前缀树,所以gin在路由匹配的时候可以获得非常高的性能。
总的来说,gin 是一个简洁的 web 框架,其主要功能就是一个
web
服务器的基本功能,就是简单的请求处理,但是其他很多现实开发中需要的东西它都没有(比如数据库、缓存),
当然它的定位应该就是提供 web
框架的基本功能,对于其他的功能,我们可以通过扩展它的方式来实现(当然,也可以直接使用其他
web 框架)。