深入理解 go reflect - 要不要传指针
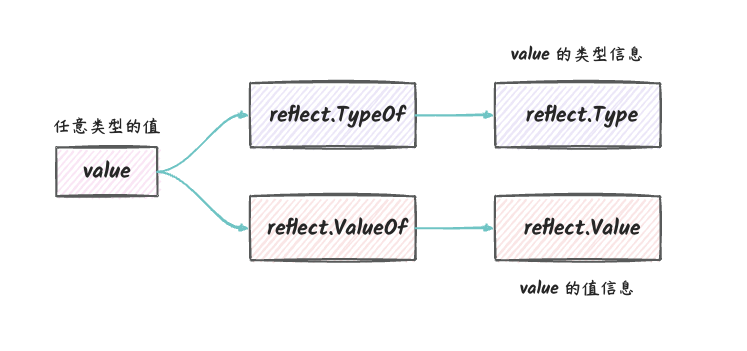
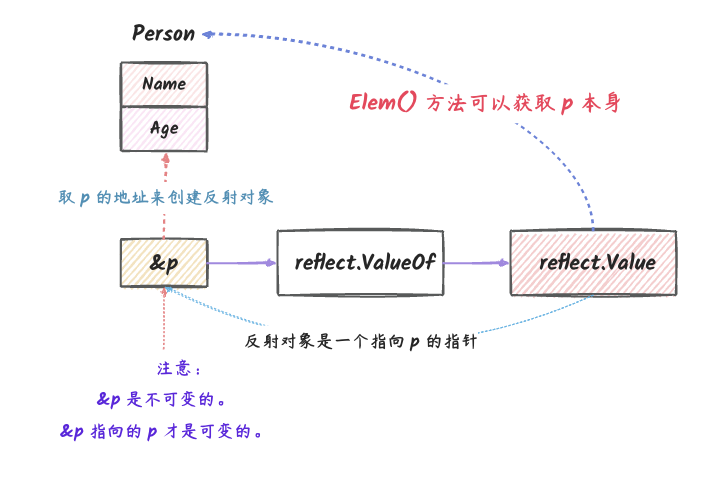
在我们看一些使用反射的代码的时候,会发现,reflect.ValueOf
或 reflect.TypeOf
的参数有些地方使用的是指针参数,有些地方又不是指针参数,
但是好像这两者在使用上没什么区别,比如下面这样:
1 | var a = 1 |
它们的区别貌似只是需不需要使用 Elem()
方法,但这个跟我们是否传递指针给 reflect.ValueOf
其实关系不大, 相信没有人为了使用一下 Elem()
方法,就去传递指针给 reflect.ValueOf 吧。
那我们什么时候应该传递指针参数呢?
什么时候传递指针?
要回答这个问题,我们可以思考一下以下列出的几点内容:
- 是否要修改变量的值,要修改就要用指针
- 结构体类型:是否要修改结构体里的字段,要修改就要用指针
- 结构体类型:是否要调用指针接收值方法,要调用就要用指针
- 对于
chan、map、slice类型,我们传递值和传递指针都可以修改其内容 - 对于非
interface类型,传递给TypeOf和ValueOf的时候都会转换为interface类型,如果本身就是interface类型,则不需转换。 - 指针类型不可修改,但是可以修改指针指向的值。(
v := reflect.ValueOf(&a),v.CanSet()是false,v.Elem().CanSet()是true) - 字符串:我们可以对字符串进行替换,但不能修改字符串的某一个字符
大概总结下来,就是:如果我们想修改变量的内容,就传递指针,否则就传递值。对于某些复合类型如果其内部包含了底层数据的指针,
也是可以通过传值来修改其底层数据的,这些类型有
chan、map、slice。
又或者如果我们想修改结构体类型里面的指针类型字段,传递结构体的拷贝也能实现。
1. 通过传递指针修改变量的值
对于一些基础类型的变量,如果我们想修改其内容,就要传递指针。这是因为在
go 里面参数传递都是值传递,如果我们不传指针,
那么在函数内部拿到的只是参数的拷贝,对其进行修改,不会影响到外部的变量(事实上在对这种反射值进行修改的时候会直接
panic)。
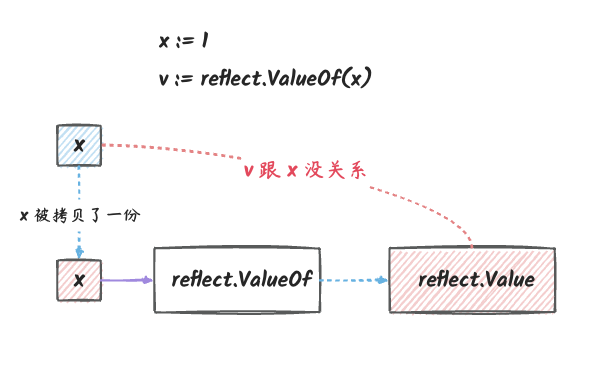
传值无法修改变量本身
1 | x := 1 |
在这个例子中,v 中保存的是 x
的拷贝,对这份拷贝在反射的层面上做修改其实是没有实际意义的,因为对拷贝进行修改并不会影响到
x 本身。
我们在通过反射来修改变量的时候,我们的预期行为往往是修改变量本身。鉴于实际的使用场景,go
的反射系统已经帮我们做了限制了,
在我们对拷贝类型的反射对象进行修改的时候,会直接
panic。
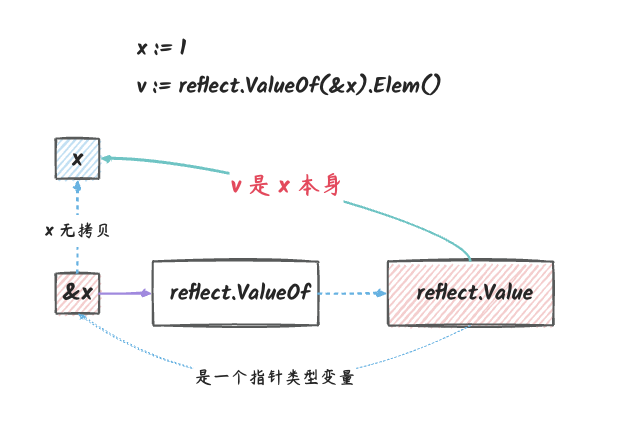
传指针可以修改变量
1 | x := 1 |
在这个例子中,我们传递了 x 的指针到
reflect.ValueOf 中,这样一来,v 指向的就是
x 本身了。 在这种情况下,我们对 v
的修改就会影响到 x 本身。
2. 通过传递指针修改结构体的字段
对于结构体类型,如果我们想修改其字段的值,也是要传递指针的。这是因为结构体类型的字段是值类型,如果我们不传递指针,
reflect.ValueOf
拿到的也是一份拷贝,对其进行修改并不会影响到结构体本身。当然,这种情况下,我们修改它的时候也会
panic。
1 | type person struct { |
3. 结构体:获取指针接收值方法
对于结构体而言,如果我们想通过反射来调用指针接收者方法,那么我们需要传递指针。
在开始讲解这一点之前,需要就以下内容达成共识:
1 | type person struct { |
在上面的代码中,p 只有一个方法 M1,而
&p 有两个方法 M1 和 M2。
但是在实际使用中,我们使用 p 来调用 M2 也是可以的,
p 之所以能调用 M2
是因为编译器帮我们做了一些处理,将 p 转换成了
&p,然后调用 M2。
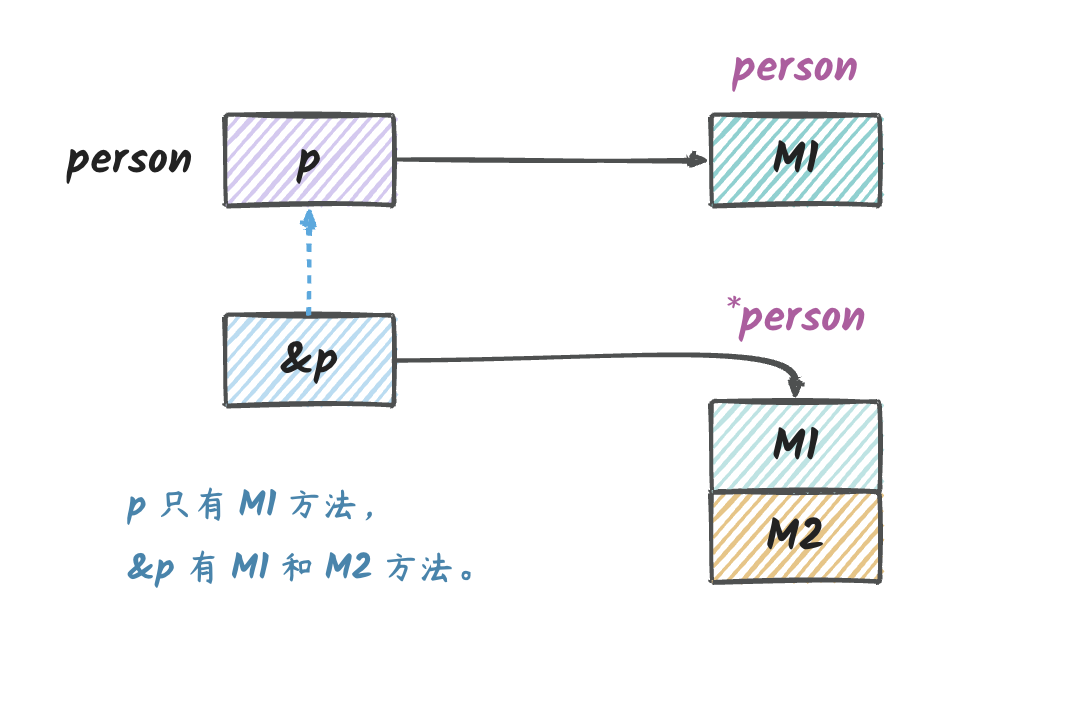
但是在反射的时候,我们是无法做到这一点的,这个需要特别注意。如果我们想通过反射来调用指针接收者的方法,就需要传递指针。
4. 变量本身包含指向数据的指针
最好不要通过值的反射对象来修改值的数据,就算有些类型可以实现这种功能。
对于 chan、map、slice
这三种类型,我们可以通过 reflect.ValueOf 来获取它们的值,
但是这个值本身包含了指向数据的指针,因此我们依然可以通过反射系统修改其数据。但是,我们最好不这么用,从规范的角度,这是一种错误的操作。
通过值反射对象修改 chan、map 和 slice
在 go 中,chan、map、slice
这几种数据结构中,存储数据都是通过一个 unsafe.Pointer
类型的变量来指向实际存储数据的内存。
这是因为,这几种类型能够存储的元素个数都是不确定的,都需要根据我们指定的大小和存储的元素类型来进行内存分配。
正因如此,我们复制
chan、map、slice
的时候,虽然值被复制了一遍,但是存储数据的指针也被复制了,
这样我们依然可以通过拷贝的数据指针来修改其数据,如下面的例子:
1 | func TestPointer1(t *testing.T) { |
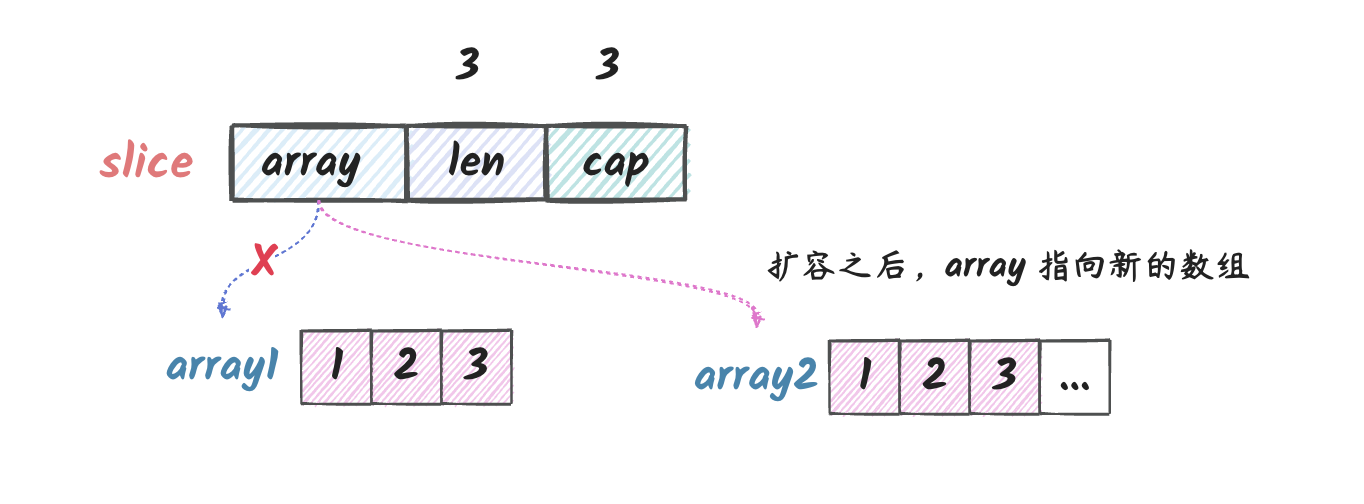
slice 反射对象扩容的影响
但是,我们需要注意的是,对于 map 和 slice
类型,在其分配的内存容纳不下新的元素的时候,会进行扩容,
扩容之后,保存数据字段的指针就指向了一片新的内存了。
这意味着什么呢?这意味着,我们通过 map 和
slice 的值创建的反射值对象中拿到的那份数据指针已经跟旧的
map 和 slice 指向的内存不一样了。
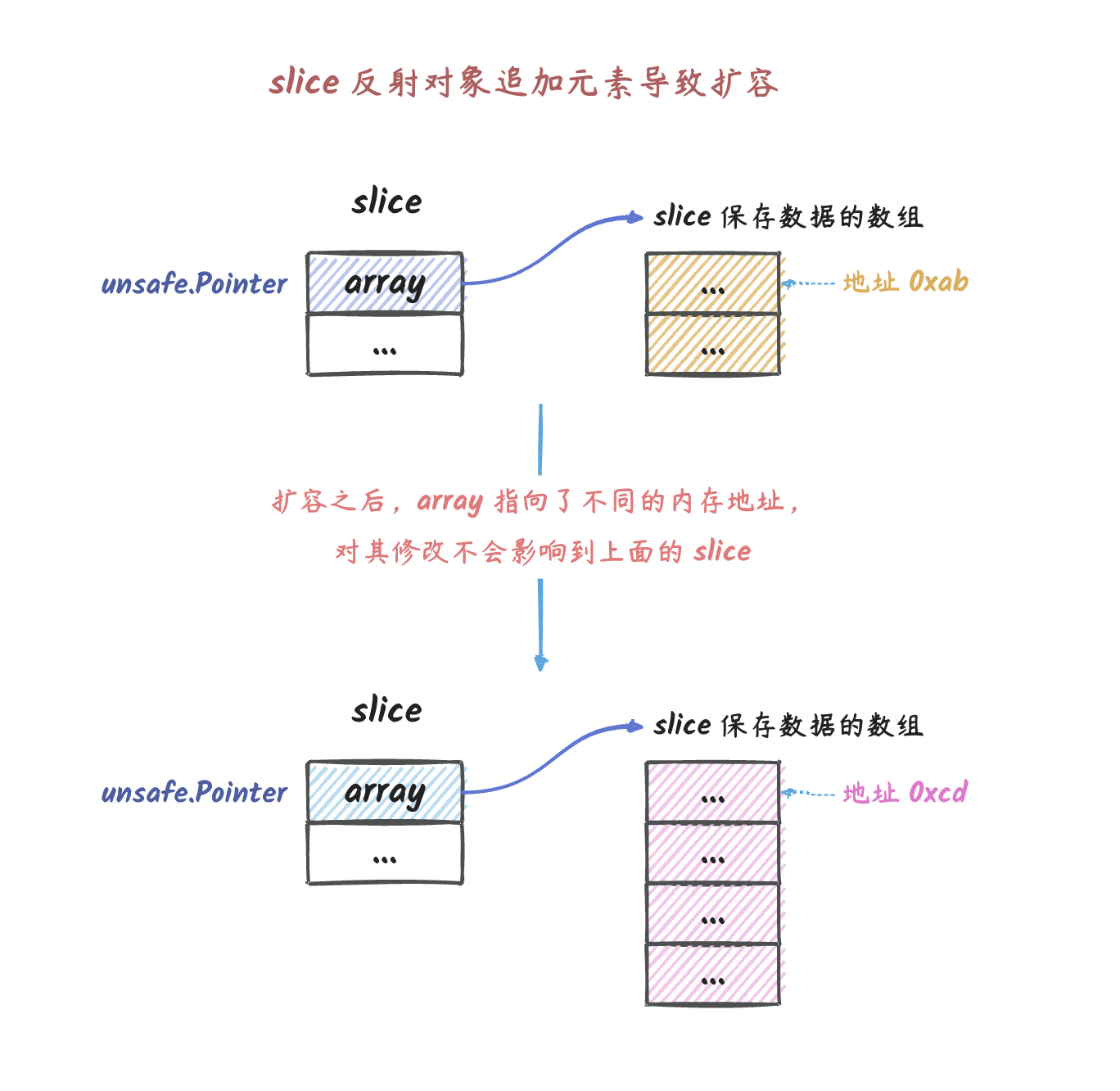
说明:在上图中,我们在反射对象中往 slice
追加元素后,导致反射对象 slice 的 array
指针指向了一片新的内存区域了,
这个时候我们再对反射对象进行修改的时候,不会影响到原
slice。这也就是我们不能通过 slice 或
map 的拷贝的反射对象来修改 slice 或
map 的原因。
示例代码:
1 | func TestPointer1(t *testing.T) { |
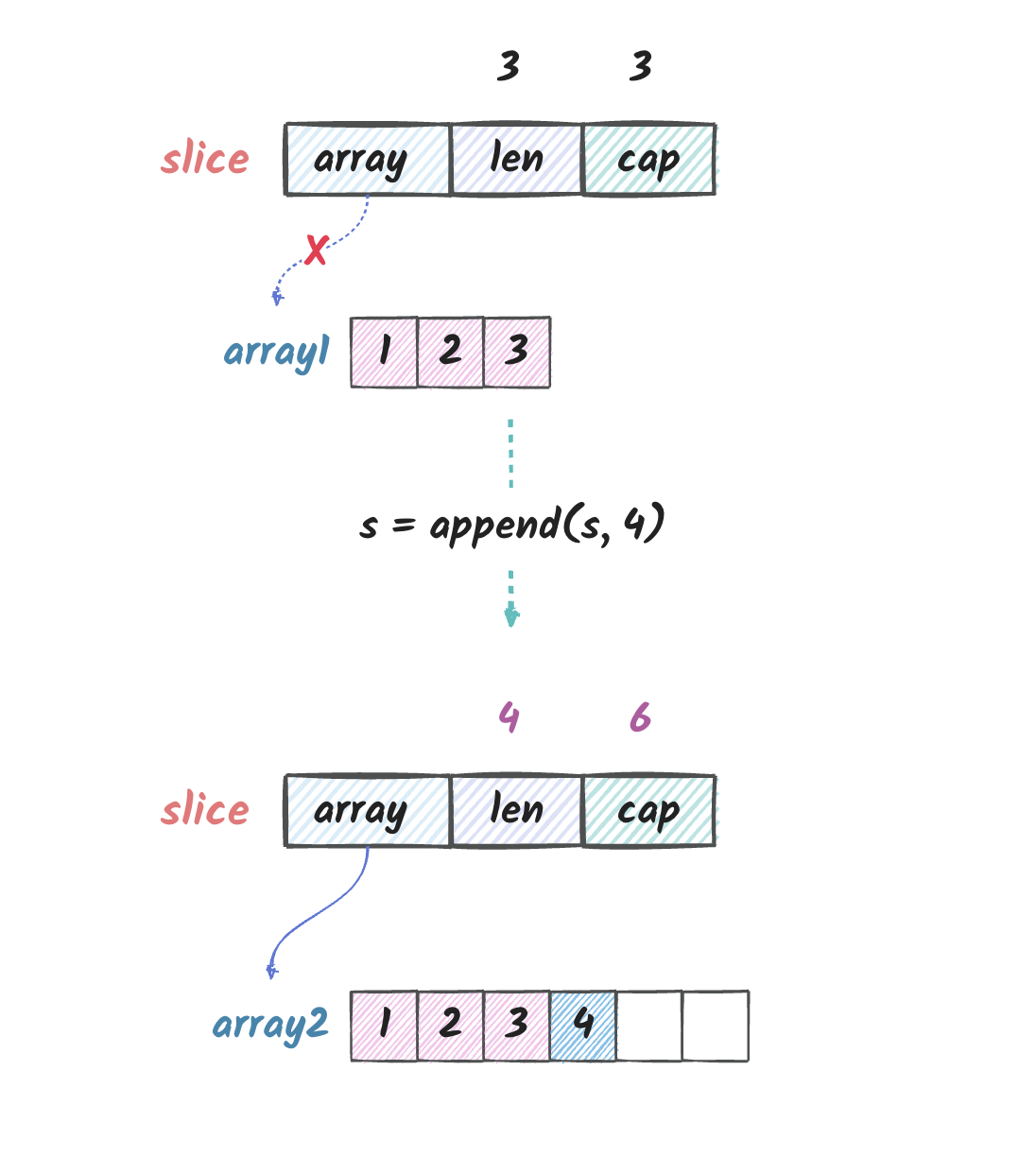
说明:在上面的代码中,v5 实际上是 v4
扩容后的切片,底层的 array 指针指向的是跟 s
不一样的 array 了, 因此在我们修改 v5
的时候,会发现原来的 s 并没有发生改变。
虽然通过值反射对象可以修改 slice 的数据,但是如果通过反射对象 append 元素到 slice 的反射对象的时候, 可能会触发 slice 扩容,这个时候再修改反射对象的时候,就影响不了原来的 slice 了。
slice 容量够的话是不是就可以正常追加元素了?
只能说,能,也不能。我们看看下面这个例子:
1 | func TestPointer000(t *testing.T) { |
在这个例子中,我们给 slice
分配了足够大的容量,但是我们通过反射对象来追加元素的时候,
虽然数据被正常追加到了 s1
底层数组,但是由于在反射对象以外的 s1 的 len
并没有发生改变, 因此 s1
还是看不到反射对象追加的元素。所以上面说可以正常追加元素。
但是,外部由于 len
没有发生改变,因此外部看不到反射对象追加的元素,所以上面也说不能正常追加元素。
因此,虽然理论上修改的是同一片内存,我们依然不能通过传值的方式来通过反射对象往
slice 中追加元素。 但是修改 [0, len(s))
范围内的元素在反射对象外部是可以看到的。
map 也不能通过值反射对象来修改其元素。
跟 slice 类似,通过 map
的值反射对象来追加元素的时候,同样可能导致扩容,
扩容之后,保存数据的内存区域会发生改变。
但是,从另一个角度看,如果我们只是修改其元素的话,是可以正常修改的。
chan 没有追加
chan 跟 slice、map
有个不一样的地方,它的长度是我们创建 chan
的时候就已经固定的了,
因此,不存在扩容导致指向内存区域发生改变的问题。
因此,对于 chan 类型的元素,我们传 ch 或者
&ch 给 reflect.ValueOf 都可以实现修改
ch。
结构体字段包含指针的情况
如果结构体里面包含了指针字段,我们也只是想通过反射对象来修改这个指针字段的话,
那么我们也还是可以通过传值给 reflect.ValueOf
来创建反射对象来修改这个指针字段:
1 | type person struct { |
在这个例子中,我们虽然使用了 p 而不是
&p 来创建反射对象, 但是我们依然可以修改
Name 字段,因为反射对象拿到了 Name
的指针的拷贝, 通过这个拷贝是可以定位到 p 的
Name 字段本身指向的内存的。
但是我们依然是不能修改 p
中的其他字段。
5. interface 类型处理
对于 interface
类型的元素,我们可以将以下两种操作看作是等价的:
1 | // v1 跟 v2 都拿到了 a 的拷贝 |
我们可以通过下面的断言来证明:
1 | assert.Equal(t, v1.Kind(), v2.Kind()) |
当然,对于指针类型也是一样的:
1 | // v1 跟 v2 都拿到了 a 的指针 |
同样的,我们可以通过下面的断言来证明:
1 | assert.Equal(t, v1.Kind(), v2.Kind()) |
interface 底层类型是值
interface 类型的底层类型是值的时候,我们将其传给
reflect.ValueOf 跟直接传值是一样的。 是没有办法修改
interface
底层数据的值的(除了指针类型字段,因为反射对象也拿到了指针字段的地址):
1 | type person struct { |
在上面这个例子中 v := reflect.ValueOf(i) 其实等价于
v := reflect.ValueOf(p), 因为在我们调用
reflect.ValueOf(p) 的时候,go 语言本身会帮我们将
p 转换为 interface{} 类型。 在我们赋值给
i 的时候,go 语言也会帮我们将 p 转换为
interface{} 类型。 这样再调用 reflect.ValueOf
的时候就不需要再做转换了。
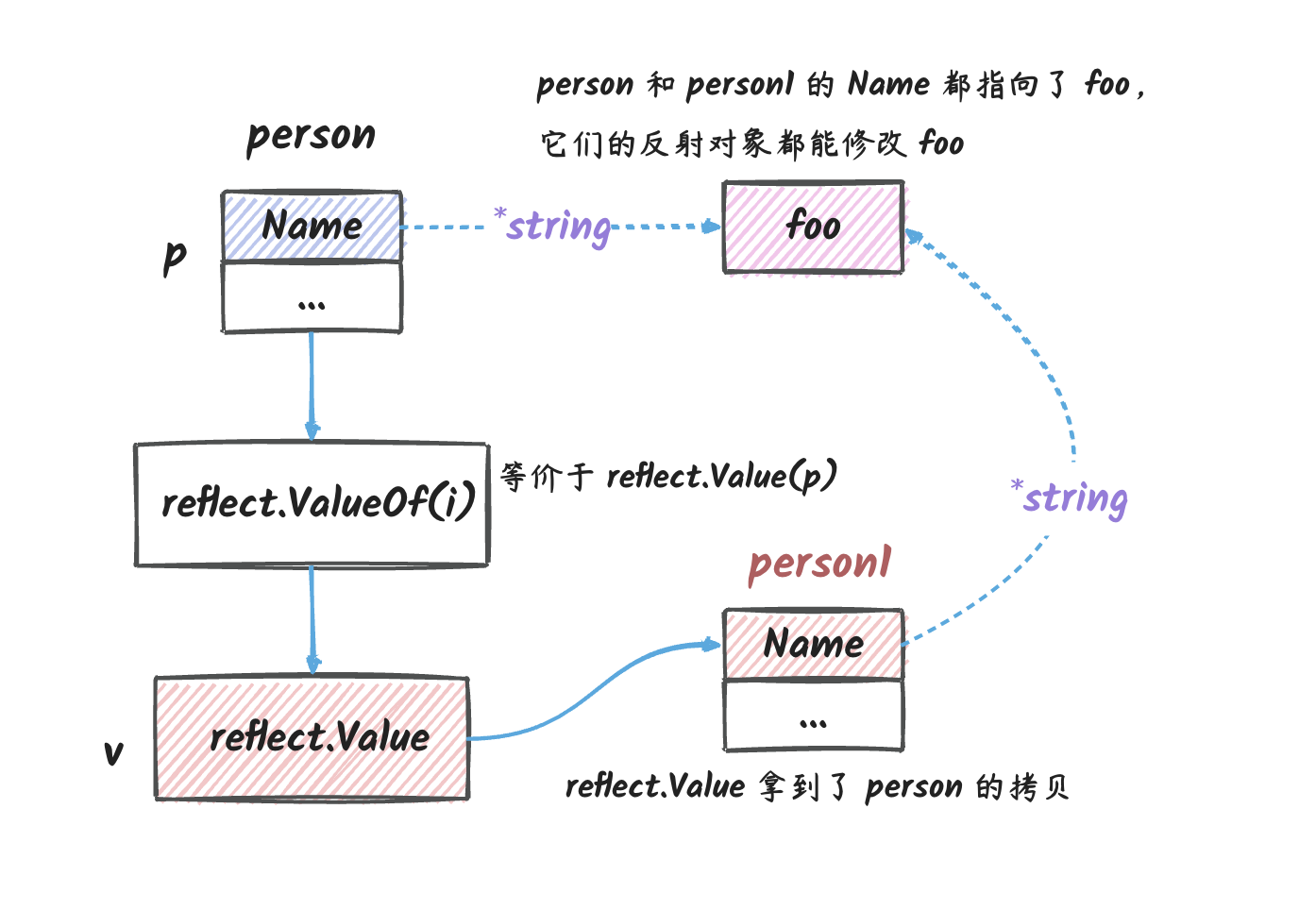
interface 底层类型是指针
传递底层数据是指针类型的 interface 给
reflect.ValueOf 的时候,我们可以修改 interface
底层指针指向的值, 效果等同于直接传递指针给
reflect.ValueOf:
1 | func TestInterface(t *testing.T) { |
不要再对接口类型取地址
能不能通过反射 Value 对象来修改变量只取决于,能不能根据反射对象拿到最初变量的内存地址。 如果拿到的只是原始值的拷贝,不管我们怎么做都无法修改原始值。
对于初学者另外一个令人困惑的地方可能是下面这样的代码:
1 | func TestInterface(t *testing.T) { |
困惑的源头在于,reflect.ValueOf() 这个函数的参数是
interface{} 类型的,
这意味着我们可以传递任意类型的值给它,包括指针类型的值。
正因如此,如果我们不懂得 reflect 包的工作原理的话,
就会传错变量到 reflect.ValueOf() 函数中,导致程序出错。
对于上面例子的 v2,它是一个指向 interface{}
类型的指针的反射对象,它也能找到最初的变量 a:
但是能不能修改
a,还是取决于a是否是可寻址的。也就是最初传递给i的值是不是一个指针类型。
1 | assert.Equal(t, "<*interface {} Value>", v2.String()) |
在上面的例子中,我们传递给 i 的是 a
的值,而不是 a 的指针,所以 i
是不可寻址的,也就是说 v2 是不可寻址的。
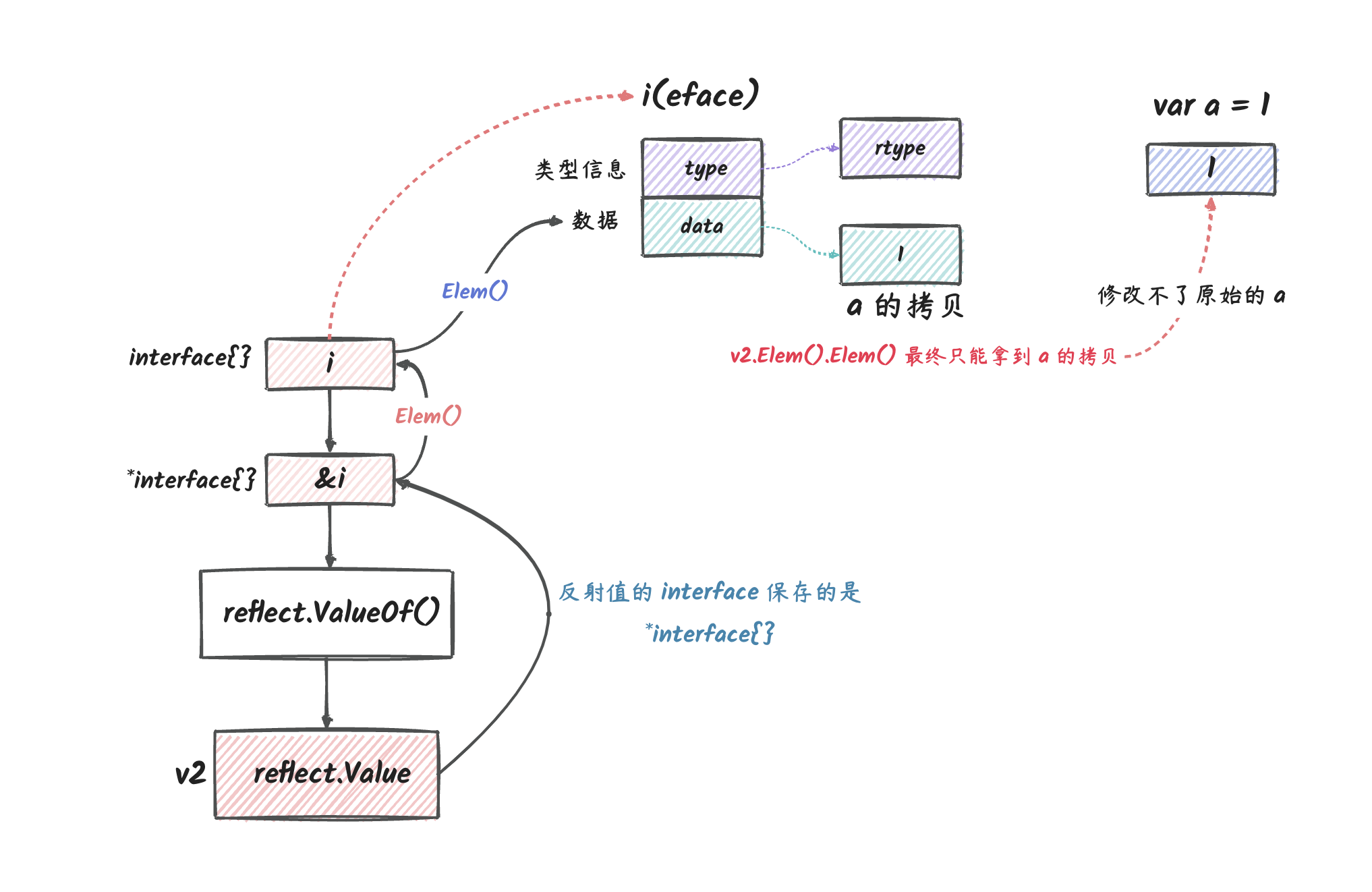
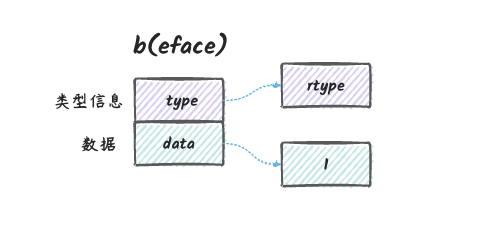
上图说明:
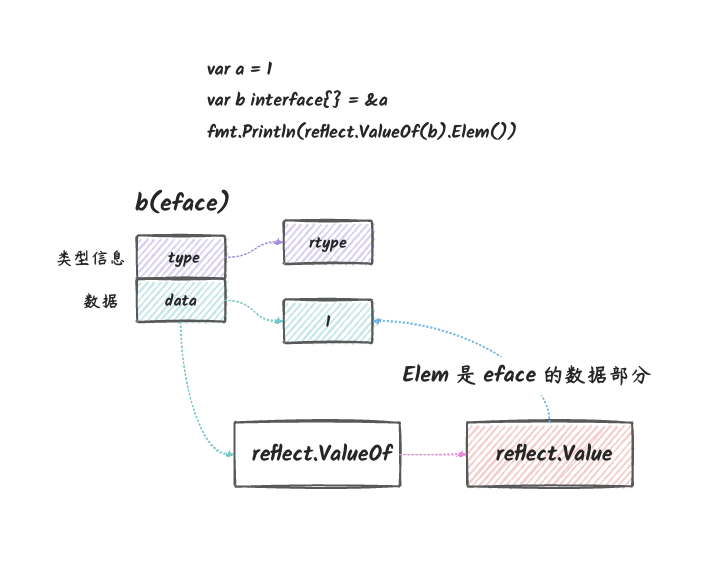
i是接口类型,它的数据部分是a的拷贝,它的类型部分是int类型。&i是指向接口的指针,它指向了上图的eface。v2是指向eface的指针的反射对象。- 最终,我们通过
v2找到i这个接口,然后通过i找到a这个变量的拷贝。
所以,绕了一大圈,我们最终还是修改不了 a
的值。到最后我们只拿到了 a 的拷贝。
6. 指针类型反射对象不可修改其指向地址
其实这一点上面有些地方也有涉及到,但是这里再强调一下。一个例子如下:
1 | func TestPointer(t *testing.T) { |
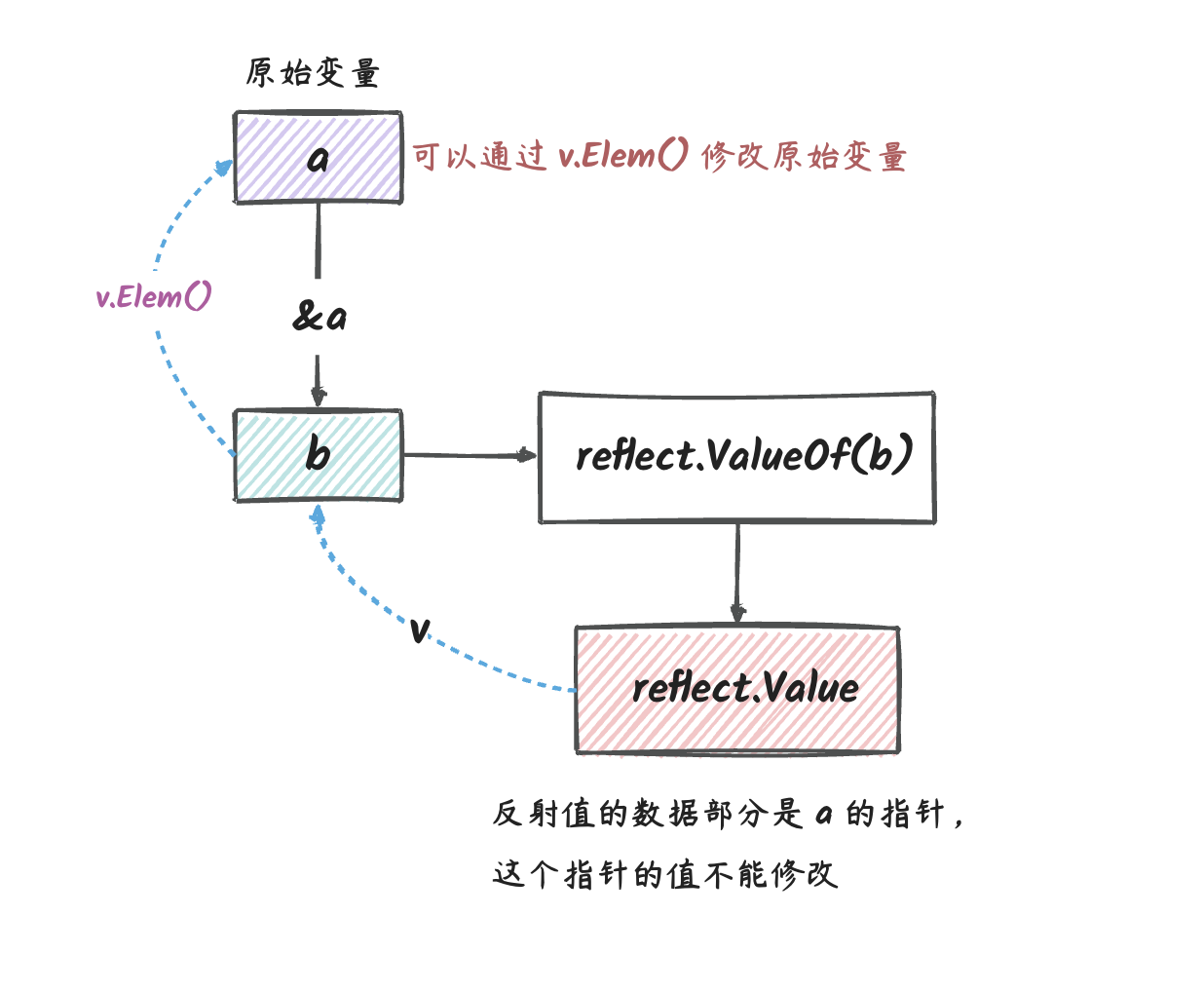
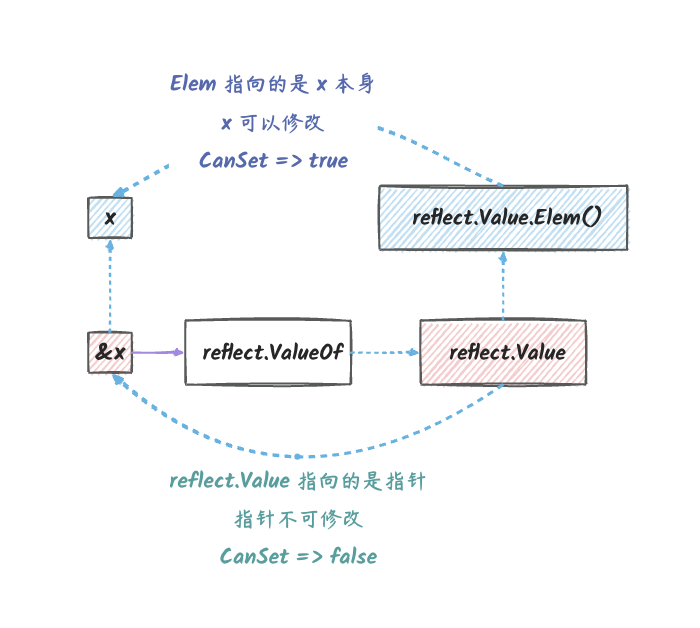
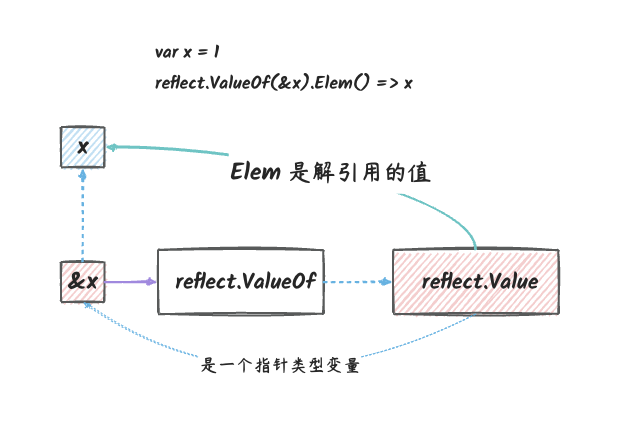
说明:
v是指向&a的指针的反射对象。- 通过这个反射对象的
Elem()方法,我们可以找到原始的变量a。 - 反射对象本身不能修改,但是它的
Elem()方法返回的反射对象可以修改。
对于指针类型的反射对象,其本身不能修改,但是它的
Elem()方法返回的反射对象可以修改。
7. 反射也不能修改字符串中的字符
这是因为,go 中的字符串本身是不可变的,我们无法像在 C
语言中那样修改其中某一个字符。 其实不止是
go,其实很多编程语言的字符串都是不可变的,比如 Java 中的
String 类型。
在 go 中,字符串是用一个结构体来表示的,大概长下面这个样子:
1 | type StringHeader struct { |
Data是指向字符串的指针。Len是字符串的长度(单位为字节)。
在 go 中 str[1] = 'a'
这样的操作是不允许的,因为字符串是不可变的。
相同的字符串只有一个实例
假设我们定义了两个相同的字符串,如下:
1 | s1 := "hello" |
这两个字符串的值是相同的,但是它们的地址是不同的。那既然如此,为什么我们还是不能修改它的其中某一个字符呢?
这是因为,虽然 s1 和 s2
的地址不一样,但是它们实际保存 hello
这个字符串的地址是一样的:
1 | v1 := (*reflect.StringHeader)(unsafe.Pointer(&s1)) |
两个字符串内存表示如下:
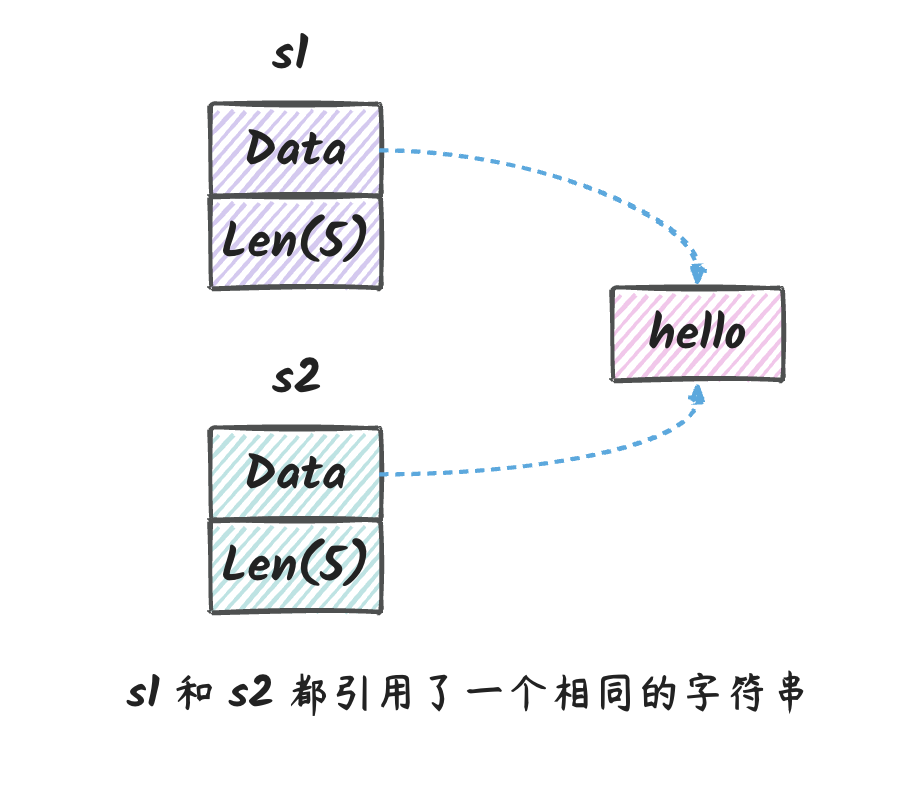
所以,我们可以看到,s1 和 s2
实际上是指向同一个字符串的指针,所以我们无法修改其中某一个字符。
因为如果允许这种行为存在的话,我们对其中一个字符串实例修改,也会影响到另外一个字符串实例。
字符串本身可以替换
虽然我们不能修改字符串中的某一个字符,但是我们可以通过反射对象把整个字符串替换掉:
1 | func TestStirng(t *testing.T) { |
这里实际上是把 s 中保存字符串的地址替换成了指向
world 这个字符串的地址,而不是将 hello
指向的内存修改成 world:
1 | func TestStirng(t *testing.T) { |
这可以用下图表示:
总结
- 如果我们需要通过反射对象来修改变量的值,那么我们必须得有办法拿到变量实际存储的内存地址。这种情况下,很多时候都是通过传递指针给
reflect.ValueOf()方法来实现的。 - 但是对于
chan、map和slice或者其他类似的数据结构,它们通过指针来引用实际存储数据的内存,这种数据结构是通过通过传值给reflect.ValueOf()方法来实现修改其中的元素的。因为这些数据结构的数据部分可以通过指针的拷贝来修改。 - 但是
map和slice有可能会扩容,如果通过反射对象来追加元素,可能导致追加失败。这是因为,通过反射对象追加元素的时候,如果扩容了,那么原来的内存地址就会失效,这样我们其实就修改不了原来的map和slice了。 - 同样的,结构体传值来创建反射对象的时候,如果其中有指针类型的字段,那么我们也可以通过指针来修改其中的元素。但是其他字段也还是修改不了的。
- 如果我们创建反射对象的参数是
interface类型,那么能不能修改元素的变量还是取决于我们这个interface类型变量的数据部分是值还是指针。如果interface变量中存储的是值,那么我们就不能修改其中的元素了。如果interface变量中存储的是指针,就可以修改。 - 我们无法修改字符串的某一个字符,通过反射也不能,因为字符串本身是不可变的。不同的
stirng类型的变量,如果它们的值是一样的,那么它们会共享实际存储字符串的内存。 - 但是我们可以直接用一个新的字符串替代旧的字符串。
但其实说了那么多,简单来说只有一点,就是我们只能通过反射对象来修改指针类型的变量。如果拿不到实际存储数据的指针,那么我们就无法通过反射对象来修改其中的元素了。