// Set is used to store a new key/value pair exclusively for this context. // It also lazy initializes c.Keys if it was not used previously. func(c *Context) Set(key string, value any) { // 获取锁 c.mu.Lock() // 如果 Keys 还没初始化,则进行初始化 if c.Keys == nil { c.Keys = make(map[string]any) }
// 设置键值对 c.Keys[key] = value // 释放锁 c.mu.Unlock() }
同样的,对 Keys 做读操作的时候也需要使用互斥锁:
1 2 3 4 5 6 7 8 9 10 11
// Get returns the value for the given key, ie: (value, true). // If the value does not exist it returns (nil, false) func(c *Context) Get(key string) (value any, exists bool) { // 获取锁 c.mu.RLock() // 读取 key value, exists = c.Keys[key] // 释放锁 c.mu.RUnlock() return }
可能会有人觉得奇怪,为什么从 map
中读也还需要锁。这是因为,如果读的时候没有锁保护, 那么就有可能在
Set 设置的过程中,同时也在进行读操作,这样就会
panic 了。
func(p *Pool) pinSlow() (*poolLocal, int) { // Retry under the mutex. // Can not lock the mutex while pinned. runtime_procUnpin() allPoolsMu.Lock() // 获取锁 defer allPoolsMu.Unlock() // 函数返回的时候释放锁 pid := runtime_procPin() // poolCleanup won't be called while we are pinned. s := p.localSize l := p.local ifuintptr(pid) < s { return indexLocal(l, pid), pid } if p.local == nil { allPools = append(allPools, p) // 全局变量修改 } // If GOMAXPROCS changes between GCs, we re-allocate the array and lose the old one. size := runtime.GOMAXPROCS(0) local := make([]poolLocal, size) atomic.StorePointer(&p.local, unsafe.Pointer(&local[0])) // store-release runtime_StoreReluintptr(&p.localSize, uintptr(size)) // store-release return &local[pid], pid }
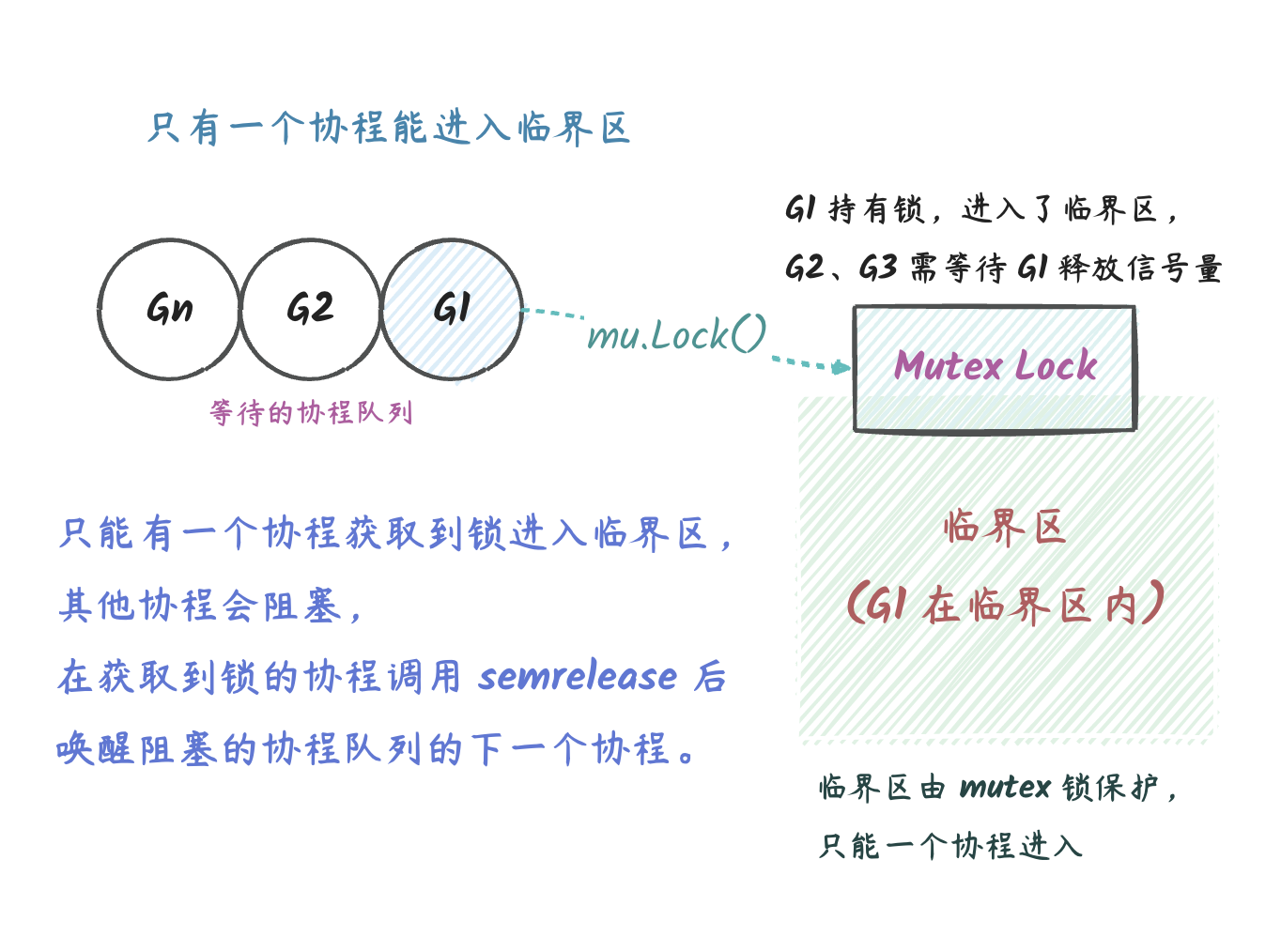
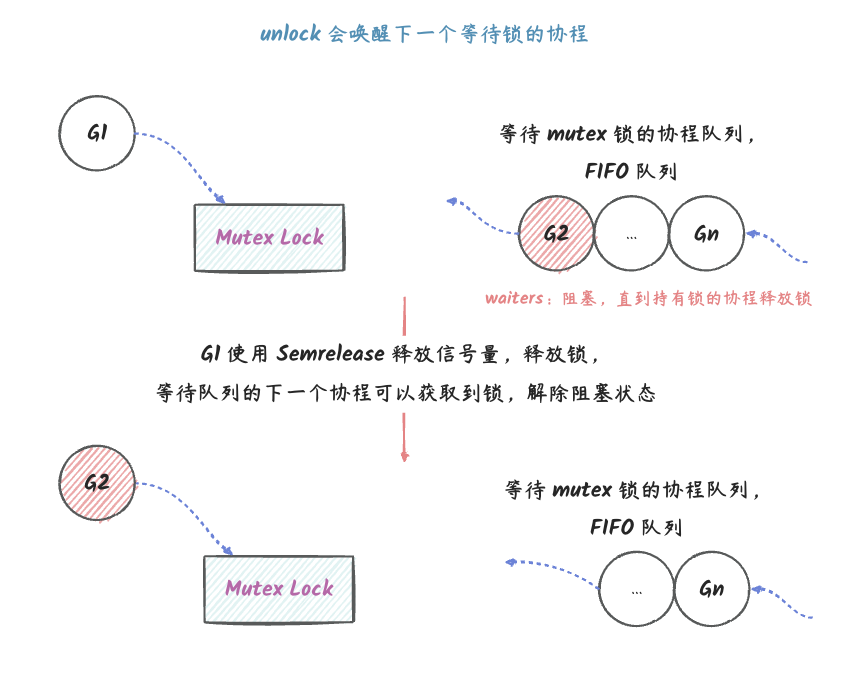
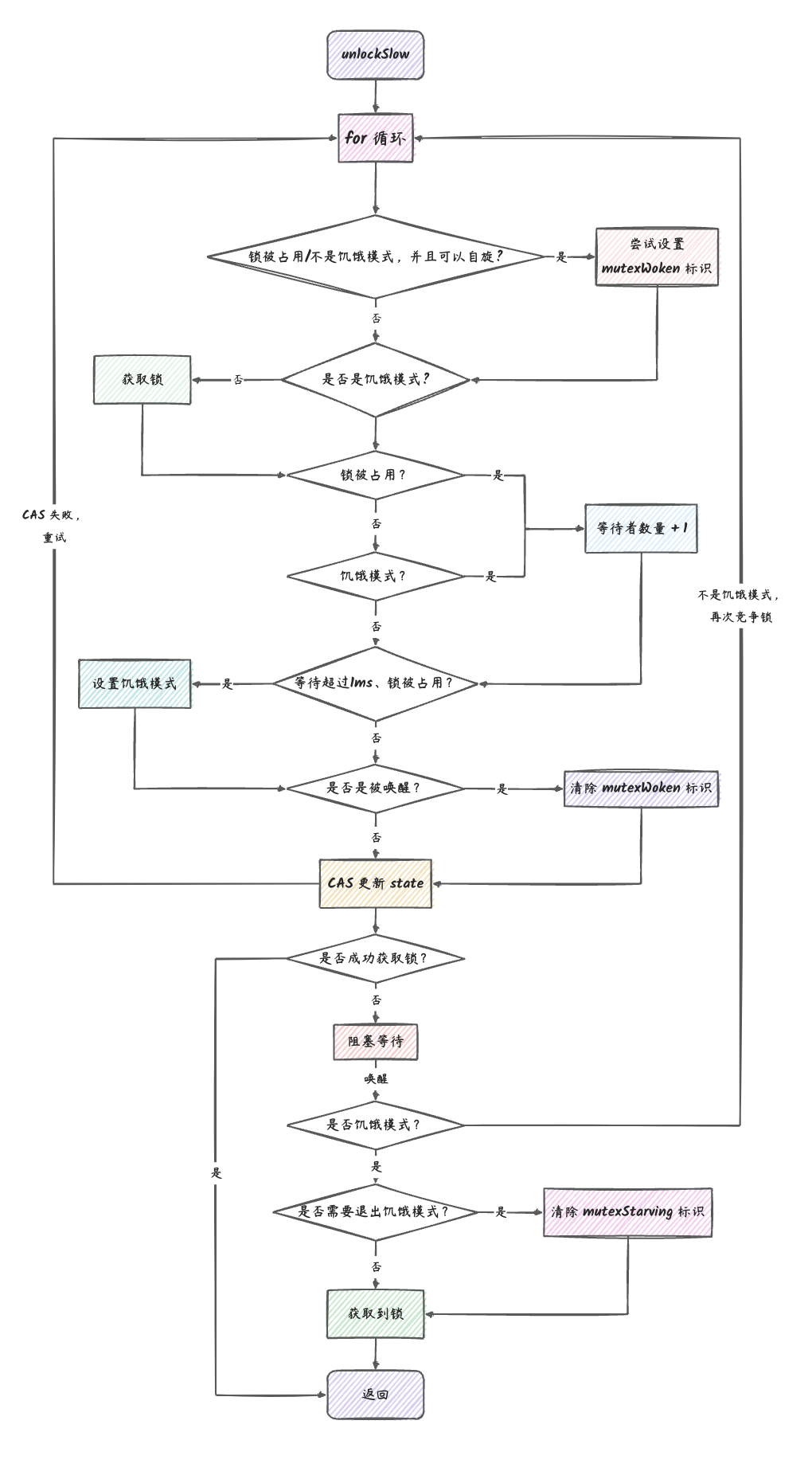
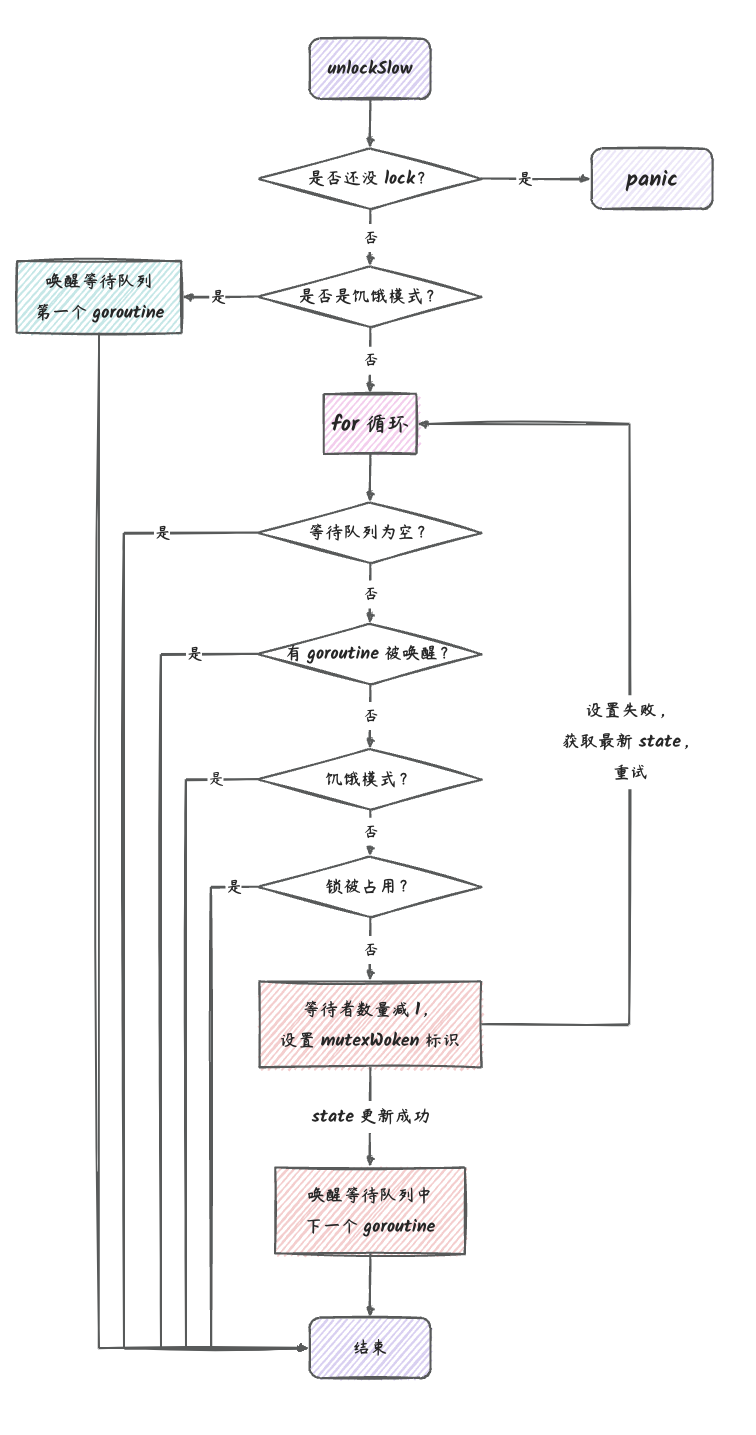
// Take takes the first element out of q if not empty. func(q *Queue) Take() (any, bool) { // 获取互斥锁(只能有一个协程获取到锁) q.lock.Lock() // 函数返回的时候释放互斥锁(获取到锁的协程释放锁之后,其他协程才能进行抢占锁) defer q.lock.Unlock()
// 下面的代码只有抢占到(也就是互斥锁锁定的代码块) if q.count == 0 { returnnil, false }
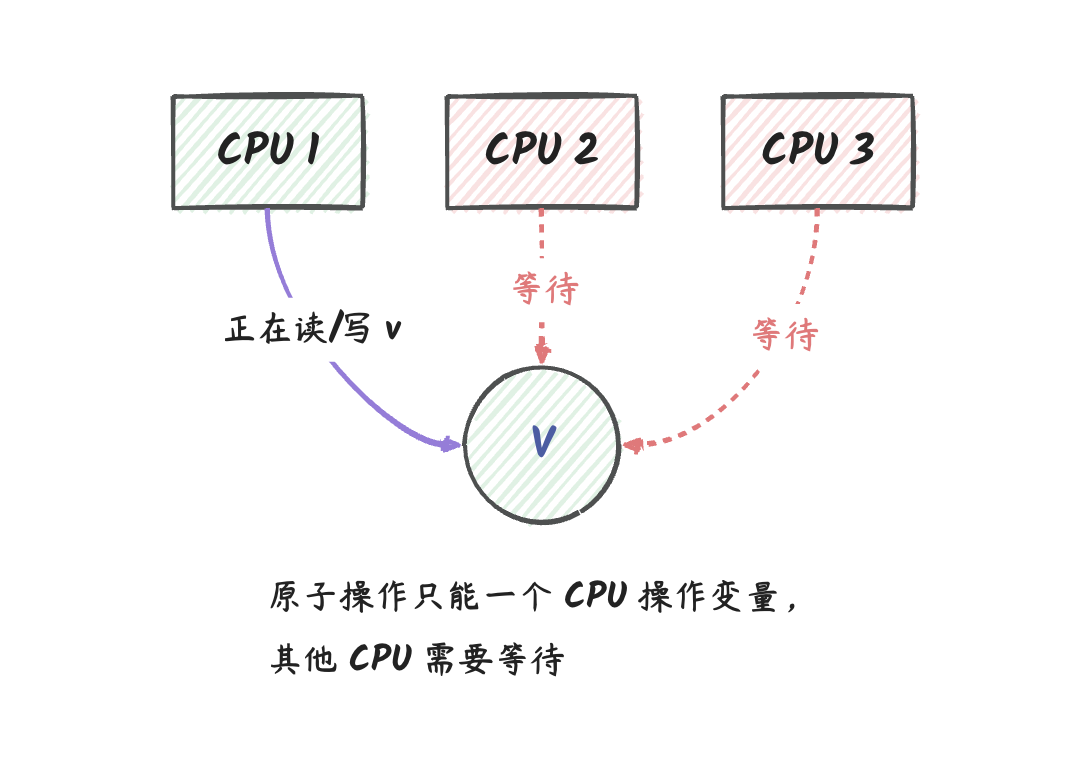
这是因为,CPU 在对 sum 做加法的时候,需要先将
sum 目前的值读取到 CPU
的寄存器中,然后再进行加法操作,最后再写回到内存中。 如果有两个 CPU
同时取了 sum
的值,然后都进行了加法操作,然后都再写回到内存中,那么就会导致
sum 的值被覆盖,从而导致结果不正确。
举个例子,目前内存中的 sum 为 1,然后两个 CPU
同时取了这个 1 来做加法,然后都得到了结果 2, 然后这两个 CPU
将各自的计算结果写回到内存中,那么内存中的 sum 就变成了
2,而不是 3。
在这种场景下,我们可以使用原子操作来实现并发安全的加法操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
funcTestAtomic1(t *testing.T) { // 将 sum 的类型改成 int32,因为原子操作只能针对 int32、int64、uint32、uint64、uintptr 这几种类型 var sum int32 = 0 var wg sync.WaitGroup wg.Add(1000)
// 启动 1000 个协程,每个协程对 sum 做加法操作 for i := 0; i < 1000; i++ { gofunc() { defer wg.Done() // 将 sum++ 改成下面这样 atomic.AddInt32(&sum, 1) }() }
一般情况下,原子操作的实现需要特殊的 CPU 指令或者系统调用。
这些指令或者系统调用可以保证在执行期间不会被其他操作或事件中断,从而保证操作的原子性。
例如,在 x86 架构的 CPU 中,可以使用 LOCK
前缀来实现原子操作。 LOCK
前缀可以与其他指令一起使用,用于锁定内存总线,防止其他 CPU
访问同一内存地址,从而实现原子操作。 在使用 LOCK
前缀的指令执行期间,CPU
会将当前处理器缓存中的数据写回到内存中,并锁定该内存地址, 防止其他 CPU
修改该地址的数据(所以原子操作总是可以读取到最新的数据)。 一旦当前 CPU
对该地址的操作完成,CPU 会释放该内存地址的锁定,其他 CPU
才能继续对该地址进行访问。
x86 LOCK 的时候发生了什么
我们再来捋一下上面的内容,看看 LOCK
前缀是如何实现原子操作的:
CPU
会将当前处理器缓存中的数据写回到内存中。(因此我们总能读取到最新的数据)
然后锁定该内存地址,防止其他 CPU 修改该地址的数据。
一旦当前 CPU 对该地址的操作完成,CPU 会释放该内存地址的锁定,其他
CPU 才能继续对该地址进行访问。
Store 可以将 val 值保存到
*addr 中,Store 操作是原子性的,因此在执行
Store 操作时,当前计算机的任何 CPU 都不会进行针对
*addr 的读写操作。
原子性存储会将 val 值保存到 *addr
中。
与读操作对应的写入操作,sync/atomic 提供了与原子值载入
Load 函数相对应的原子值存储 Store
函数,原子性存储函数均以 Store 为前缀。
Store 操作有下面这些:
1 2 3 4 5 6
funcStoreInt32(addr *int32, val int32) funcStoreInt64(addr *int64, val int64) funcStoreUint32(addr *uint32, val uint32) funcStoreUint64(addr *uint64, val uint64) funcStoreUintptr(addr *uintpre, val uintptr) funcStorePointer(addr *unsafe.Pointer, val unsafe.Pointer)
// 判断 atomic.Value 的类型 typ := LoadPointer(&vp.typ) // 第一次 Store 还没有完成,直接返回 nil if typ == nil || typ == unsafe.Pointer(&firstStoreInProgress) { // firstStoreInProgress 是一个特殊的变量,存储到 typ 中用来表示第一次 Store 还没有完成 returnnil }
// 获取 atomic.Value 的值 data := LoadPointer(&vp.data) // 将 val 转换为 efaceWords 类型 vlp := (*efaceWords)(unsafe.Pointer(&val)) // 分别赋值给 val 的 typ 和 data vlp.typ = typ vlp.data = data return }
// Store 将 Value 的值设置为 val。 func(v *Value) Store(val any) { // 不能存储 nil 值 if val == nil { panic("sync/atomic: store of nil value into Value") } // atomic.Value 转换为 efaceWords vp := (*efaceWords)(unsafe.Pointer(v)) // val 转换为 efaceWords vlp := (*efaceWords)(unsafe.Pointer(&val)) // 自旋进行原子操作,这个过程不会很久,开销相比互斥锁小 for { // LoadPointer 可以保证获取到的是最新的 typ := LoadPointer(&vp.typ) // 第一次 store 的时候 typ 还是 nil,说明是第一次 store if typ == nil { // 尝试开始第一次 Store。 // 禁用抢占,以便其他 goroutines 可以自旋等待完成。 // (如果允许抢占,那么其他 goroutine 自旋等待的时间可能会比较长,因为可能会需要进行协程调度。) runtime_procPin() // 抢占失败,意味着有其他 goroutine 成功 store 了,允许抢占,再次尝试 Store // 这也是一个原子操作。 if !CompareAndSwapPointer(&vp.typ, nil, unsafe.Pointer(&firstStoreInProgress)) { runtime_procUnpin() continue } // 完成第一次 store // 因为有 firstStoreInProgress 标识的保护,所以下面的两个原子操作是安全的。 StorePointer(&vp.data, vlp.data) // 存储值(原子操作) StorePointer(&vp.typ, vlp.typ) // 存储类型(原子操作) runtime_procUnpin() // 允许抢占 return }
// 另外一个 goroutine 正在进行第一次 Store。自旋等待。 if typ == unsafe.Pointer(&firstStoreInProgress) { continue }
// 第一次 Store 已经完成了,下面不是第一次 Store 了。 // 需要检查当前 Store 的类型跟第一次 Store 的类型是否一致,不一致就 panic。 if typ != vlp.typ { panic("sync/atomic: store of inconsistently typed value into Value") }
// 后续的 Store 只需要 Store 值部分就可以了。 // 因为 atomic.Value 只能保存一种类型的值。 StorePointer(&vp.data, vlp.data) return } }
在 Store 中,有以下几个注意的点:
使用 firstStoreInProgress 来确保第一次
Store 的时候,只有一个 goroutine 可以进行
Store 操作,其他的 goroutine
需要自旋等待。如果没有这个保护,那么存储 typ 和
data
的时候就会出现竞争(因为需要两个原子操作),导致数据不一致。在这里其实可以将
firstStoreInProgress 看作是一个互斥锁。
在进行第一次 Store 的时候,会将当前的 goroutine 和
P 绑定,这样拿到 firstStoreInProgress
锁的协程就可以尽快地完成第一次 Store
操作,这样一来,其他的协程也不用等待太久。
在第一次 Store
的时候,会有两个原子操作,分别存储类型和值,但是因为有
firstStoreInProgress 的保护,所以这两个原子操作本质上是对
interface{} 的一个原子存储操作。
其他协程在看到有 firstStoreInProgress
标识的时候,就会自旋等待,直到第一次 Store 完成。
在后续的 Store 操作中,只需要存储值就可以了,因为
atomic.Value 只能保存一种类型的值。
Swap - 交换
Swap 将 Value 的值设置为 new
并返回旧值。对给定值的所有交换调用必须使用相同具体类型的值。同时,不一致类型的交换会发生恐慌,Swap(nil)
也会 panic。
// Swap 将 Value 的值设置为 new 并返回旧值。 func(v *Value) Swap(new any) (old any) { // 不能存储 nil 值 ifnew == nil { panic("sync/atomic: swap of nil value into Value") }
// atomic.Value 转换为 efaceWords vp := (*efaceWords)(unsafe.Pointer(v)) // new 转换为 efaceWords np := (*efaceWords)(unsafe.Pointer(&new)) // 自旋进行原子操作,这个过程不会很久,开销相比互斥锁小 for { // 下面这部分代码跟 Store 一样,不细说了。 // 这部分代码是进行第一次存储的代码。 typ := LoadPointer(&vp.typ) if typ == nil { runtime_procPin() if !CompareAndSwapPointer(&vp.typ, nil, unsafe.Pointer(&firstStoreInProgress)) { runtime_procUnpin() continue } StorePointer(&vp.data, np.data) StorePointer(&vp.typ, np.typ) runtime_procUnpin() returnnil } if typ == unsafe.Pointer(&firstStoreInProgress) { continue } if typ != np.typ { panic("sync/atomic: swap of inconsistently typed value into Value") }
// ---- 下面是 Swap 的特有逻辑 ---- // op 是返回值 op := (*efaceWords)(unsafe.Pointer(&old)) // 返回旧的值 op.typ, op.data = np.typ, SwapPointer(&vp.data, np.data) return old } }
CompareAndSwap - 比较并交换
CompareAndSwap 将 Value 的值与
old 比较,如果相等则设置为 new 并返回
true,否则返回 false。
对给定值的所有比较和交换调用必须使用相同具体类型的值。同时,不一致类型的比较和交换会发生恐慌,CompareAndSwap(nil, nil)
也会 panic。
// CompareAndSwap 比较并交换。 func(v *Value) CompareAndSwap(old, new any) (swapped bool) { // 注意:old 是可以为 nil 的,new 不能为 nil。 // old 是 nil 表示是第一次进行 Store 操作。 ifnew == nil { panic("sync/atomic: compare and swap of nil value into Value") }
// atomic.Value 转换为 efaceWords vp := (*efaceWords)(unsafe.Pointer(v)) // new 转换为 efaceWords np := (*efaceWords)(unsafe.Pointer(&new)) // old 转换为 efaceWords op := (*efaceWords)(unsafe.Pointer(&old))
// old 和 new 类型必须一致,且不能为 nil if op.typ != nil && np.typ != op.typ { panic("sync/atomic: compare and swap of inconsistently typed values") }
// 自旋进行原子操作,这个过程不会很久,开销相比互斥锁小 for { // LoadPointer 可以保证获取到的 typ 是最新的 typ := LoadPointer(&vp.typ) if typ == nil { // atomic.Value 是 nil,还没 Store 过 // 准备进行第一次 Store,但是传递进来的 old 不是 nil,compare 这一步就失败了。直接返回 false if old != nil { returnfalse }
// 下面这部分代码跟 Store 一样,不细说了。 // 这部分代码是进行第一次存储的代码。 runtime_procPin() if !CompareAndSwapPointer(&vp.typ, nil, unsafe.Pointer(&firstStoreInProgress)) { runtime_procUnpin() continue } StorePointer(&vp.data, np.data) StorePointer(&vp.typ, np.typ) runtime_procUnpin() returntrue } if typ == unsafe.Pointer(&firstStoreInProgress) { continue } if typ != np.typ { panic("sync/atomic: compare and swap of inconsistently typed value into Value") }
// 通过运行时相等性检查比较旧版本和当前版本。 // 这允许对值类型进行比较,这是包函数所没有的。 // 下面的 CompareAndSwapPointer 仅确保 vp.data 自 LoadPointer 以来没有更改。 data := LoadPointer(&vp.data) var i any (*efaceWords)(unsafe.Pointer(&i)).typ = typ (*efaceWords)(unsafe.Pointer(&i)).data = data if i != old { // atomic.Value 跟 old 不相等 returnfalse } // 只做 val 部分的 cas 操作 return CompareAndSwapPointer(&vp.data, data, np.data) } }
这里需要特别说明的只有最后那个比较相等的判断,也就是
data := LoadPointer(&vp.data) 以及往后的几行代码。
在开发 atomic.Value
第一版的时候,那个开发者其实是将这几行写成
CompareAndSwapPointer(&vp.data, old.data, np.data)
这种形式的。 但是在旧的写法中,会存在一个问题,如果我们做
CAS 操作的时候,如果传递的参数 old
是一个结构体的值这种类型,那么这个结构体的值是会被拷贝一份的,
同时再会被转换为 interface{}/any
类型,这个过程中,其实参数的 old 的 data
部分指针指向的内存跟 vp.data 指向的内存是不一样的。
这样的话,CAS 操作就会失败,这个时候就会返回
false,但是我们本意是要比较它的值,出现这种结果显然不是我们想要的。
funcTestCas(t *testing.T) { var sum int32 = 0 var wg sync.WaitGroup wg.Add(1000)
for i := 0; i < 1000; i++ { gofunc() { defer wg.Done() // cas 失败的时候,重新获取 sum 的值进行计算。 // cas 成功则返回。 for { if atomic.CompareAndSwapInt32(&sum, sum, sum+1) { return } } }() }
Pool 是一组可以安全在多个 goroutine
间共享的临时对象的集合。 存储在 Pool
中的任何项目都可能在任何时候被移除,因此 Pool
不适合保存那些有状态的对象,如数据库连接、TCP 连接等。 Pool
的目的是缓存已分配但未使用的项以供以后使用,从而减少垃圾收集器的压力。
也就是说,它可以轻松构建高效、线程安全的空闲列表,但是,它并不适用于所有空闲列表。
使用实例
下面以几个实际的例子来说明 Pool 的一些使用场景。
下面是两个非常典型的使用场景,但是在实际使用中,对于那些需要频繁创建和销毁的对象的场景,我们都可以考虑使用
Pool。
gin 里面 Context 对象使用
Pool 保存
在 gin 的 Engine 结构体中的
ServeHTTP 方法中,可以看到 Context 对象是从
Pool 中获取的。 然后在处理完请求之后,将
Context 对象放回 Pool 中。
为了快速访问队列中的元素,使用数组是最好的选择,但是数组的大小是固定的,如果队列中的元素很多,那么数组就会很快被填满。
如果我们还想继续往队列中添加元素,那么就需要对数组进行扩容,这个成本是很高的(因为本来就是需要频繁分配/销毁对象的场景才会使用
Pool)。 同时,我们知道 Pool
设计的目的就是为了减少频繁内存分配带来的性能问题,如果在使用
Pool 的过程中频繁对其进行扩容,那么就违背了
Pool 设计的初衷了。
为了解决数组扩容的问题,我们可以考虑一下使用链表。在我们
Put 的时候往链表的头部添加一个元素,然后 Get
的时候从链表的尾部取出一个元素(还需要移除)。
但是这样我们就需要一个结构体来表示我们的节点了,那么问题来了,我们又需要频繁地分配/销毁这个结构体,这样就又回到了最开始的问题了(频繁创建/销毁对象)。
所以,只使用链表也不是一个好的选择。
所以,Pool 采用了 数组 + 链表
的方式来实现双端队列,它们的关系如下:
数组:存储队列中的元素,数组的大小是固定的。
链表:当一个数组存储满了之后,就会新建一个数组,然后通过链表将这两个数组串联起来。
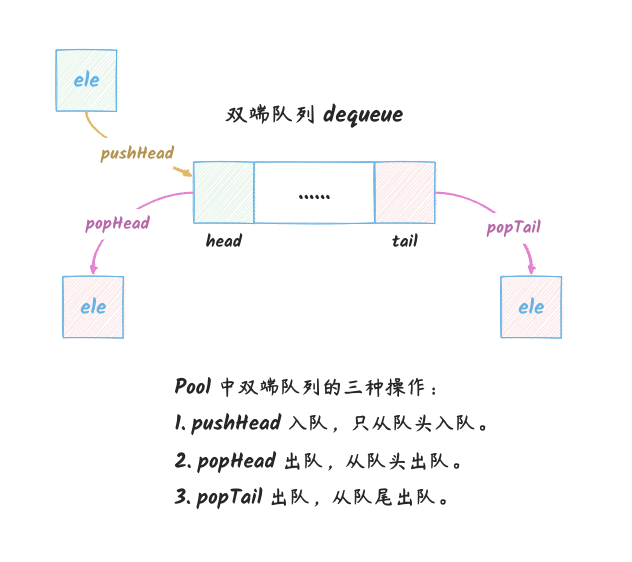
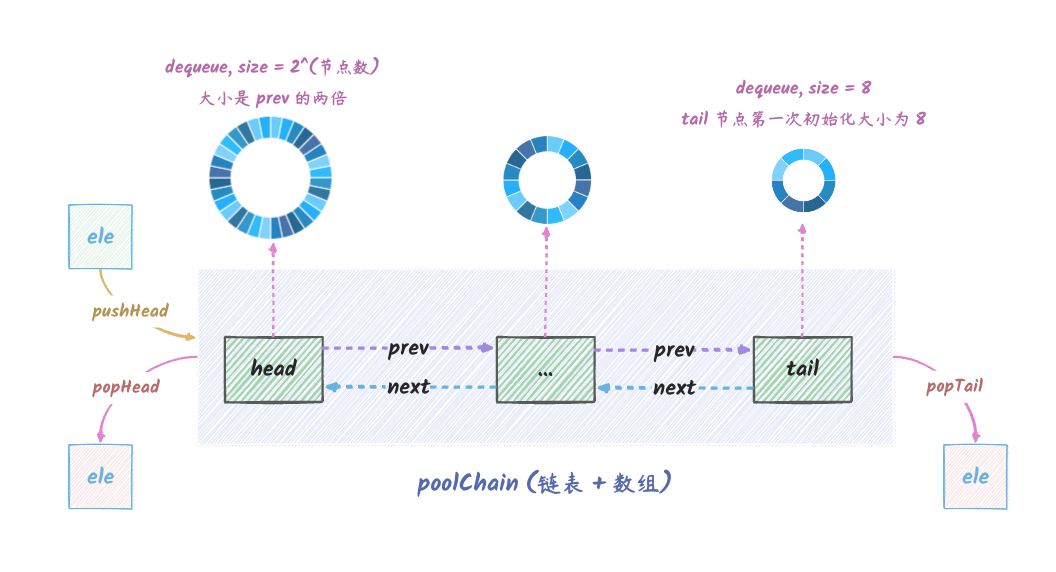
最终,Pool 的双端队列的结构如下:
pool_2
数组如何实现队列
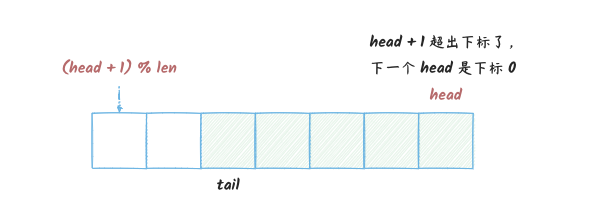
我们知道,数组的存储空间是固定的一块连续的内存,所以我们可以通过下标来访问数组中的元素。
我们 push 的时候,将 head 下标
+1,然后 pop 的时候,也要修改对应的下标,
但是这样会导致一个问题是,早晚 head
会超出数组的下标范围,但这个时候数组可能还有很多空间, 因为在我们
push 的时候,可能也同时在
pop,所以数组中的空间可能还有很多。
所以,就可以在 head 超出数组下标范围的时候,将
head 对数组长度取模,这样就可以循环使用数组了:
pool_3
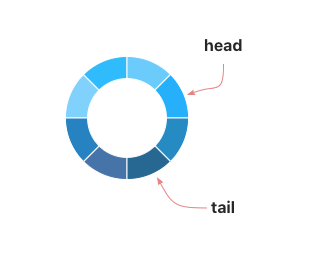
不过对于这种情况,使用下面的图更加直观:
pool_4
Pool 里面是使用 poolDequeue
这个结构体来表示上图这个队列的,本身是一个数组,但是是当作环形队列使用的。
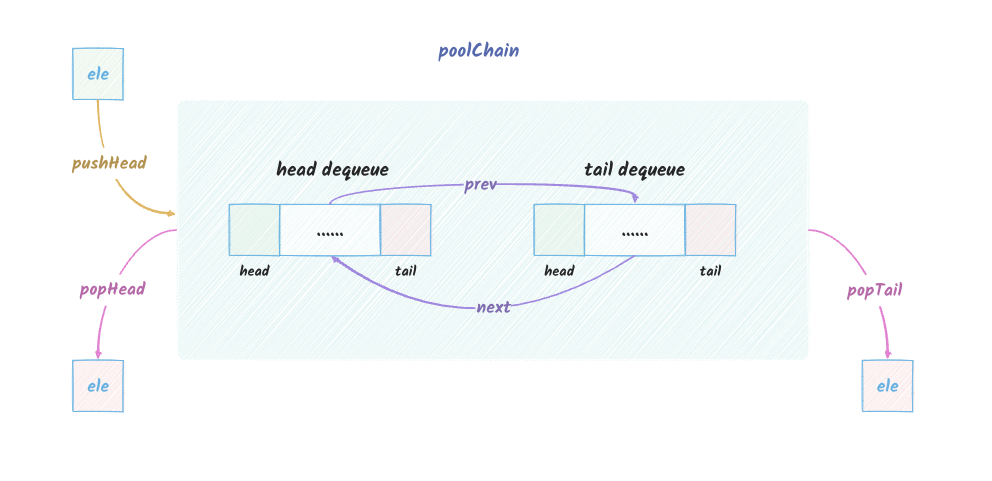
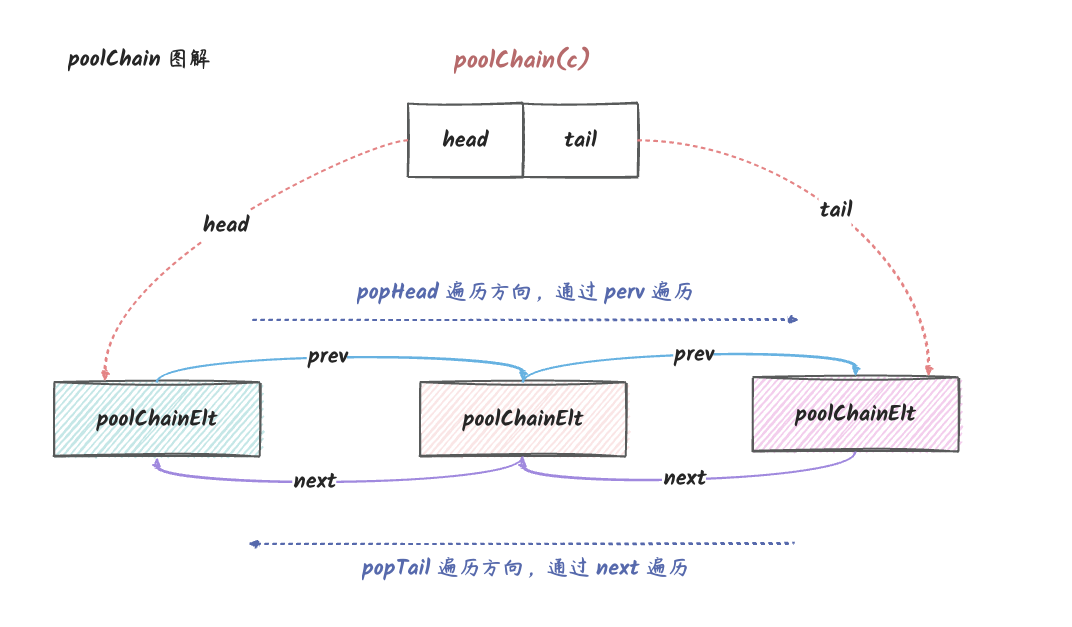
poolChain 的最终模型
poolChain 就是上面说的 数组 + 链表
的组合,它的最终模型如下:
pool_5
说明:
poolChain 本身是一个双向链表,每个节点都是一个
poolDequeue,每个节点都有 prev 和
next 指针指向前后节点。上图的 head
是头节点,tail 是尾节点。
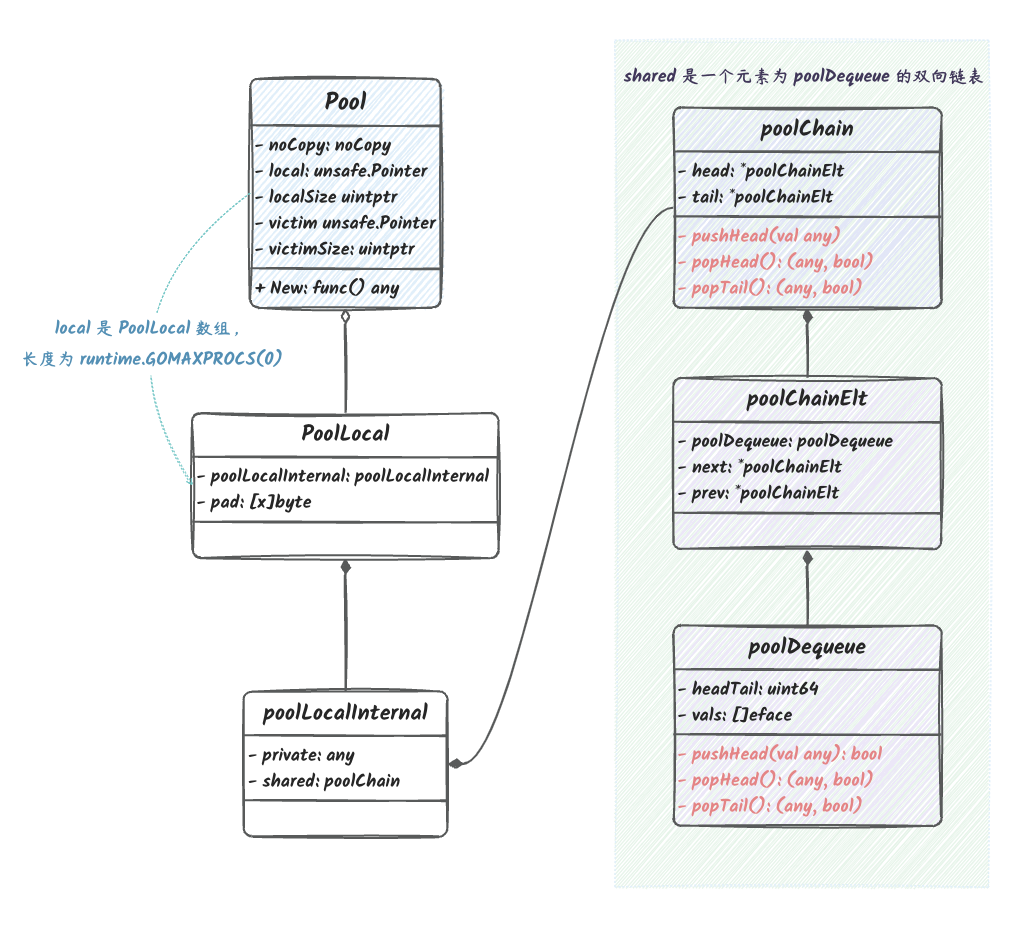
type Pool struct { // noCopy 用于防止 Pool 被复制(可以使用 go vet 检测) noCopy noCopy
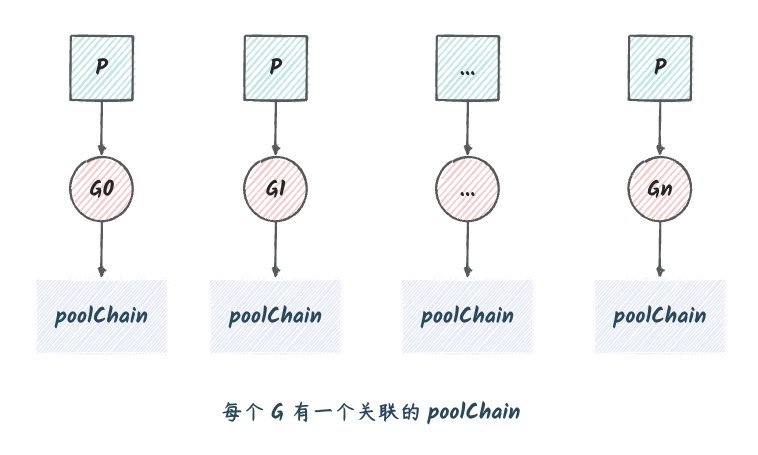
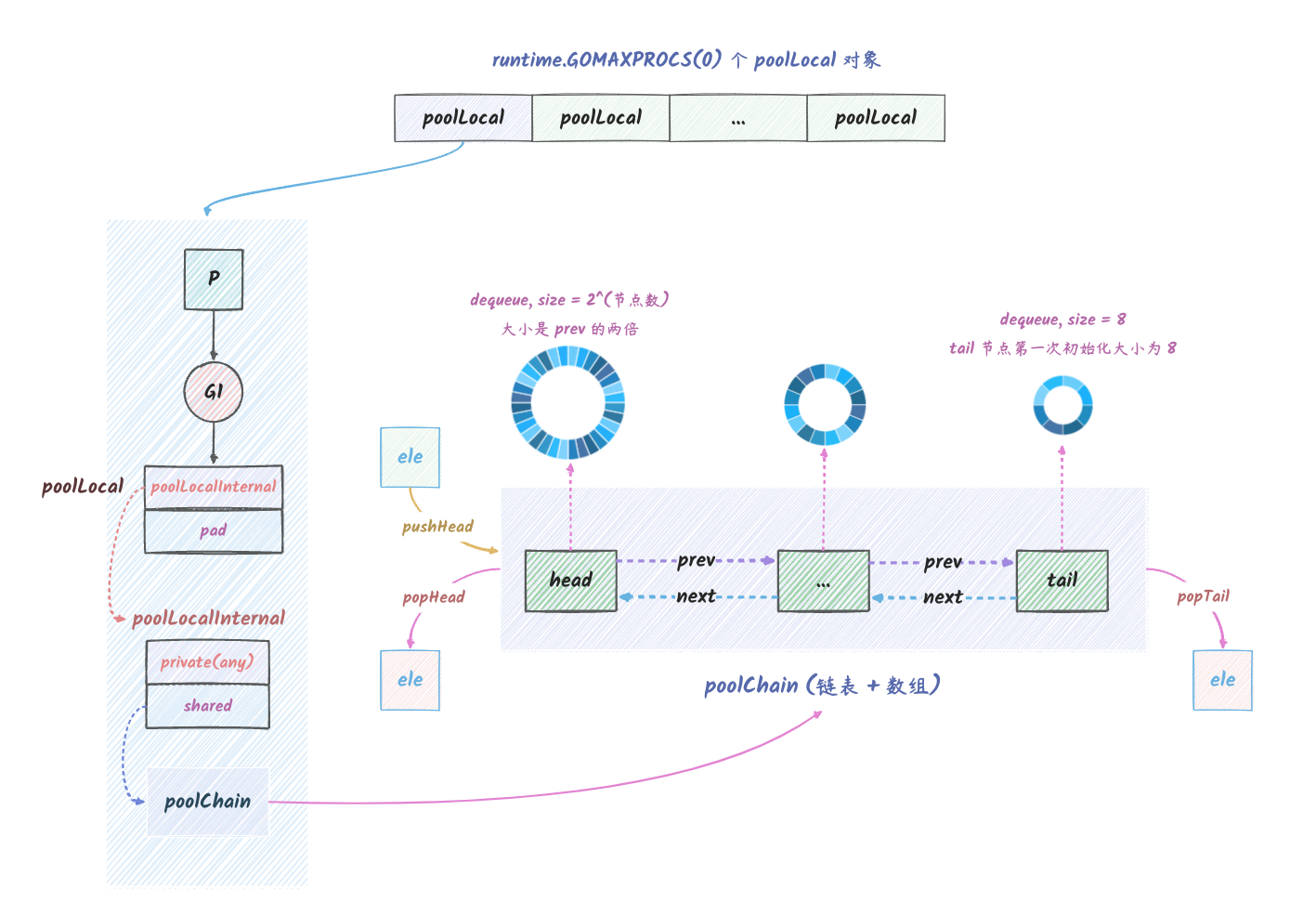
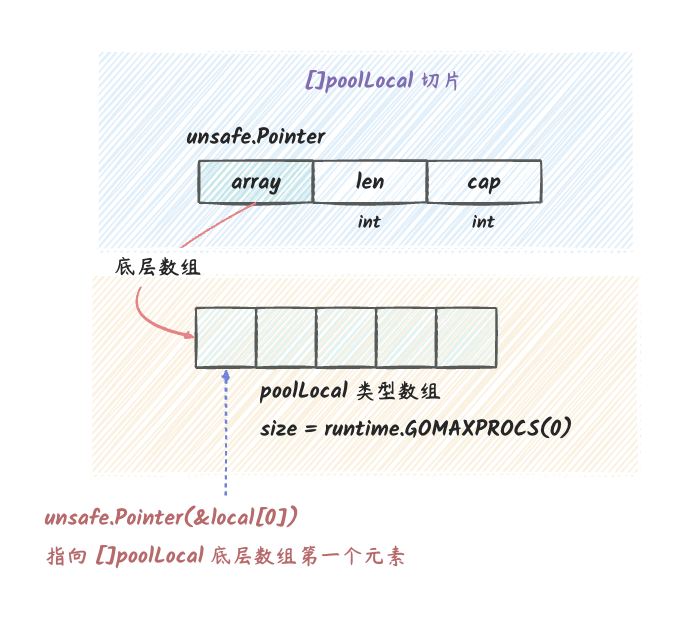
// local 的主要作用是,多个 goroutine 同时访问 Pool 时,可以减少竞争,提升性能。 // 实际类型是 [P]poolLocal。长度是 localSize。 local unsafe.Pointer // []poolLocal 的长度。也就是 local 切片的长度 localSize uintptr
// 实际存储 Pool 的数据的结构体 type poolLocalInternal struct { // private 用于存储 Pool 的 Put 方法传入的数据。 // Get 的时候如果 private 不为空,那么直接返回 private 中的数据。 // 只能被当前 P 使用。 private any // 本地 P 可以pushHead/popHead // 任何 P 都可以 popTail。 shared poolChain }
// Pool 中的 local 属性的元素类型。 // Pool 中的 local 是一个元素类型为 poolLocal 的切片,长度为 runtime.GOMAXPROCS(0)。 type poolLocal struct { poolLocalInternal
// pad 用于填充 poolLocalInternal 到 cache line 的大小。 // 为了避免伪共享,将 poolLocalInternal 放在第一个字段。 pad [128 - unsafe.Sizeof(poolLocalInternal{})%128]byte }
其实这里比较关键的地方是 pad 字段的作用,我们知道,CPU
会将内存分成多个 cache line,CPU 从内存中读取数据的时候,
并不是一个字节一个字节地读取,而是一次性读取一个 cache line
的数据。但是如果我们的数据结构中的字段不是按照 cache line
的大小来排列的, 比如跨了两个 cache
line,那么在读取的时候就会产生伪共享,这样就会降低性能。
pool_11
伪共享的原因是,数据跨了两个 cache line,那么在读取的时候,就会将两个
cache line 都读取到 CPU 的 cache 中, 这样有可能会导致不同 CPU
在发生数据竞争的时候,会使一些不相关的数据也会失效,从而导致性能下降。
如果对齐到 cache
line,那么从内存读取数据的时候,就不会将一些不相关的数据也读取到 CPU 的
cache 中,从而避免了伪共享。
poolChain、poolChainElt
和 poolDequeue 结构体
为什么要把这三个放一起讲呢?因为这三个结构体就是 Pool
中做实际存取数据的结构体,三者作用如下:
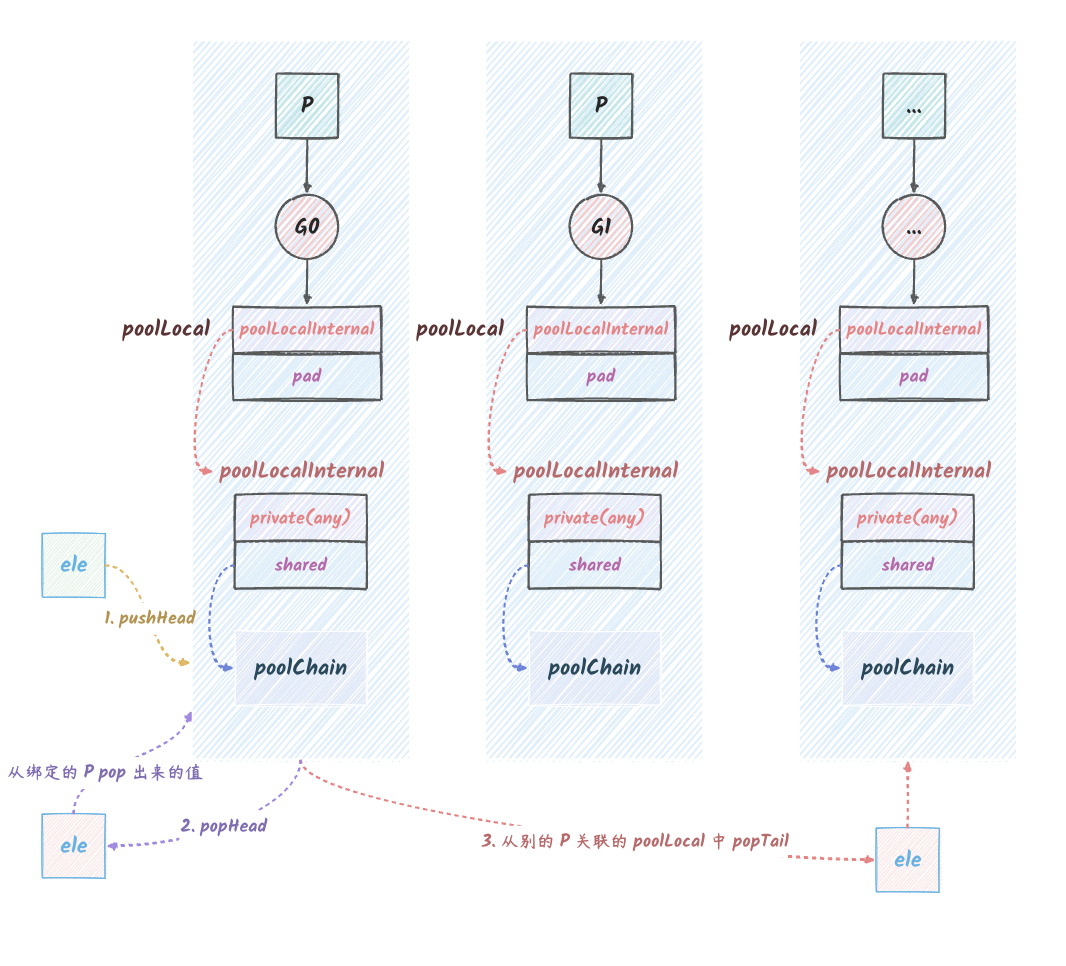
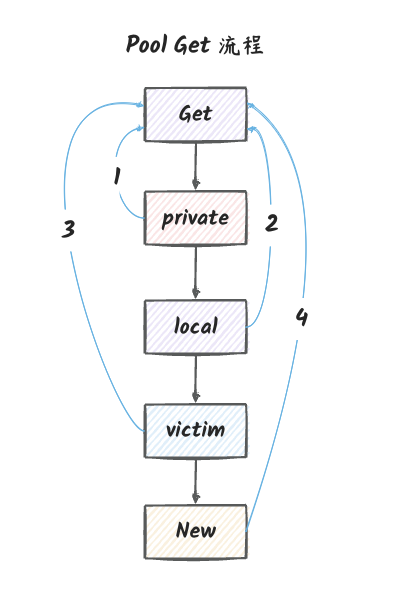
// Get 从 Pool 中获取一个对象 func(p *Pool) Get() any { // ... // pin 将当前的 goroutine 和 P 绑定,禁止被抢占,返回当前 P 的本地缓存(poolLocal)和 P 的 ID。 l, pid := p.pin() // 先看 private 是否为 nil,如果不为 nil,就直接返回 private,并将 private 置为 nil。 x := l.private l.private = nil if x == nil { // 尝试从本地 shared 的头部取。 x, _ = l.shared.popHead() if x == nil { // 如果本地 shared 的头部取不到,就从其他 P 的 shared 的尾部取。 x = p.getSlow(pid) } } // 将当前的 goroutine 和 P 解绑,允许被抢占。 runtime_procUnpin() // ... // 如果 x 为 nil 并且 p.New 不为 nil,则返回 p.New() 的结果。 // 没有就 New 一个。 if x == nil && p.New != nil { x = p.New() } return x }
PoolGet 的流程可以总结如下:
将当前的 goroutine 和 P
绑定,禁止被抢占,返回当前 P
的本地缓存(poolLocal)和 P 的
ID。
从本地 private 取,如果取不到,就从本地
shared 的头部取,如果取不到,就从其他 P 的
shared 的尾部取。获取到则返回
如果从其他的 P 的 shared
的尾部也获取不到,则从 victim 获取。获取到则返回
将当前的 goroutine 和 P
解绑,允许被抢占。
如果 p.New 不为 nil,则返回
p.New 的结果。
再贴一下上面那个图(当然,下图包含了下面的 getSlow
的流程,并不只是 Get):
pool_10
在 Pool 中一个很关键的操作是
pin,它的作用是将当前的 goroutine 和
P 绑定,禁止被抢占。 这样就可以保证在 Get 和
Put 的时候,都可以获取到当前 P
的本地缓存(poolLocal), 否则,有可能在 Get
和 Put 的时候,P 会被抢占,导致获取到的
poolLocal 不一致,这样 poolLocal
就会失去意义, 不得不再次陷入跟其他 goroutine
竞争的状态,又不得不考虑在如何在不同 goroutine
之间进行同步了。
而绑定了 P 后,在 Get 和 Put
的时候,就可以使用原子操作来代替其他更大粒度的锁了,
但是我们也不必太担心,因为绑定 P 的时间窗口其实很小。
getSlow 源码剖析
在 Get 中,如果从 private 和
shared 中都取不到,就会调用 getSlow
方法。它的作用是:
pinSlow 的流程: 1. 解除当前 P 的绑定。 2.
加全局 Pool 的锁。 3. 重新绑定当前 P。 4.
如果当前 P 的 id 小于
localSize,那么就返回当前 P 的
poolLocal。(典型的 double-checking) 5. 如果
local 还没初始化,那么将当前 P 的
poolLocal 添加到 allPools 中。 6. 初始化
local。最后返回当前 P 的
poolLocal。
对于 local
的初始化,我们可以参考一下下图(我们需要知道的是,切片的底层结构体的第一个字段是一个数组):
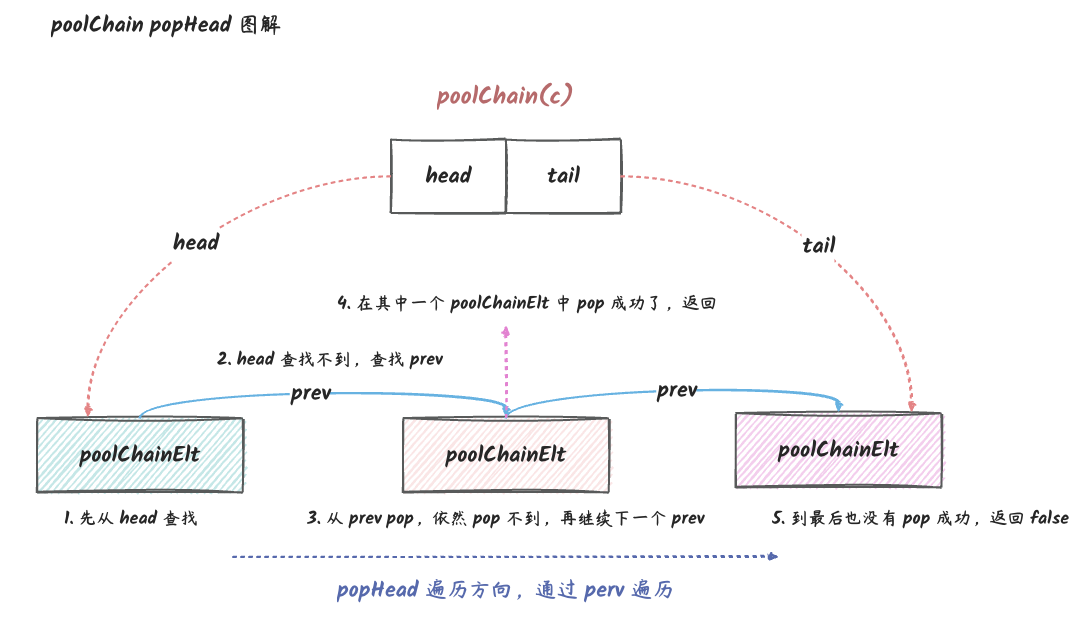
// popHead 会从链表头部 pop 出一个元素。 // 返回值: // 1. any:pop 出的元素。 // 2. bool:是否成功 pop 出元素。 func(c *poolChain) popHead() (any, bool) { d := c.head // d == nil 的情况: // 1. 链表为空。 // 2. 链表只有一个元素,且这个元素已经 pop 完了。(被其他协程 pop 了) for d != nil { // 这是因为,在我们拿到 d 之后,还没来得及 pop 的话,其他协程可能已经 pop 了。 // 所以需要 for 循环。典型的无锁编程。 // // poolQueue 还没空的时候可以成功 pop,popHead 会返回 true。 if val, ok := d.popHead(); ok { return val, ok }
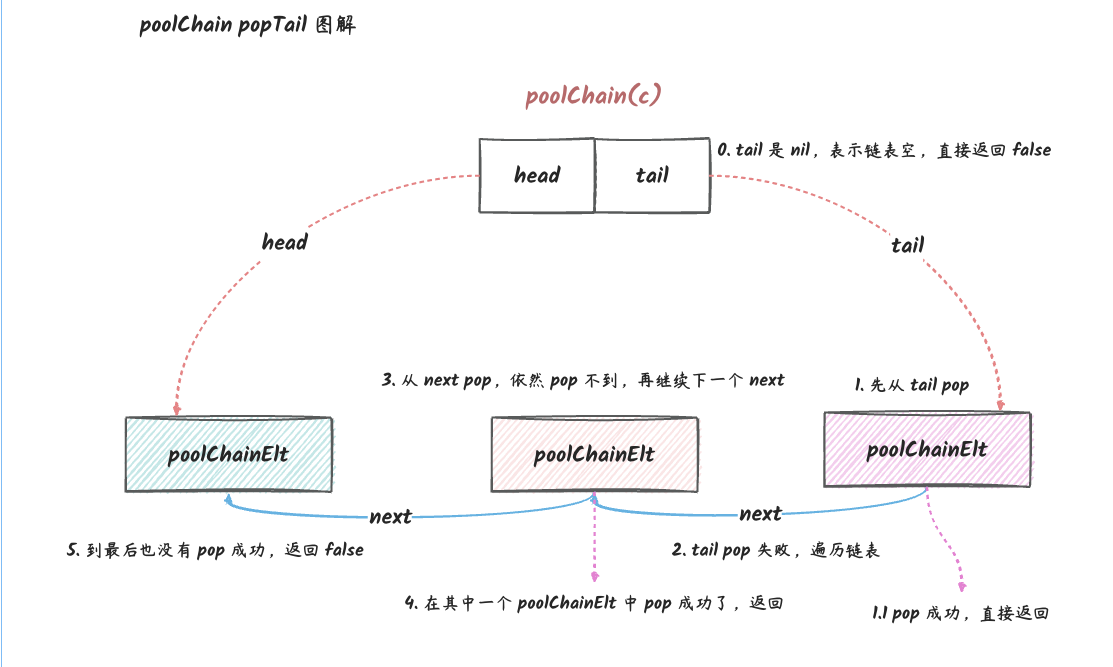
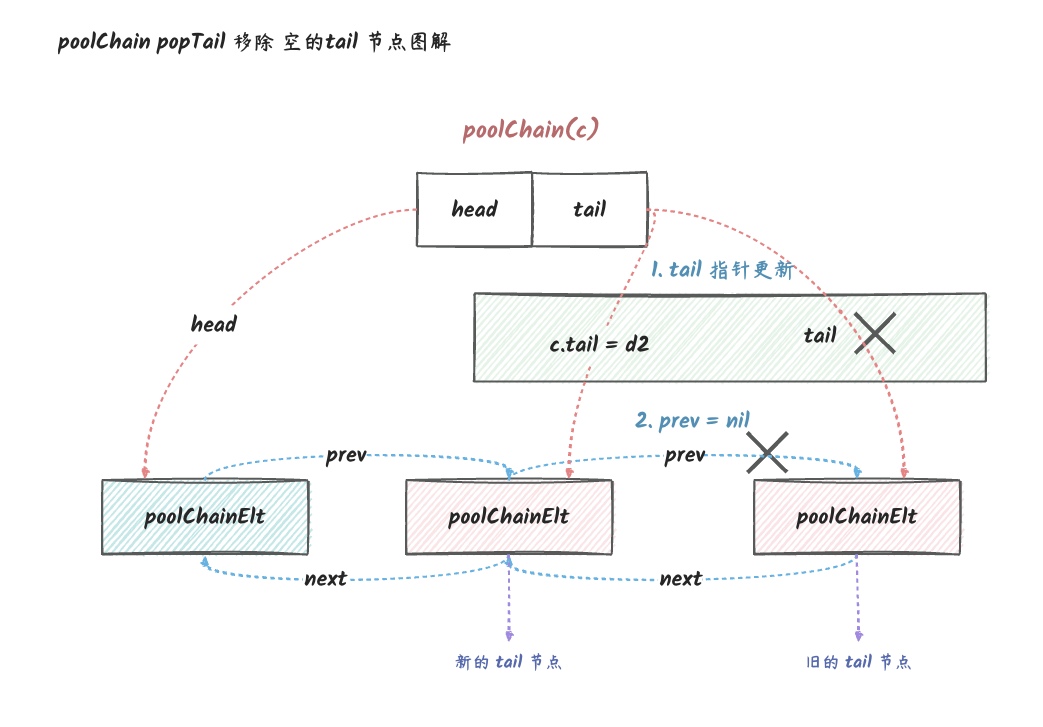
// 从队列尾取出一个元素 func(c *poolChain) popTail() (any, bool) { // 获取链表尾部的 poolChainElt // 如果链表为空,返回 nil,false d := loadPoolChainElt(&c.tail) if d == nil { returnnil, false }
for { // 在我们 popTail 之前获取 next 指针很重要。 // 一般来说,d 可能暂时为空,但如果 next 在 pop 之前为非 nil, // 并且 pop 失败,则 d 永久为空,这是唯一可以安全地将 d 从链中删除的条件。 // // 解析:next 非 nil,但是 pop 失败:d 肯定是空的了,这个时候我们可以安全地将 d 从链表中删除。 d2 := loadPoolChainElt(&d.next)
// poolQueue 还没空的时候可以成功 pop,popTail 会返回 true。 if val, ok := d.popTail(); ok { return val, ok }
// 队列已经空了 if d2 == nil { // d 是唯一的 dequeue。它现在是空的,但以后可能会有新的元素 push 进来。 returnnil, false }
// popHead 和 popTail 都有取值,然后将槽置空的过程,但是它们的实现是不一样的。 // 在 popHead 中,是直接将槽的值设置为 eface{},而在 popTail 中, // 先将 val 设置为 nil,然后将 typ 通过原子操作设置为 nil。 // 这样在 pushHead 的时候就可以安全操作了,只要先使用原子操作判断 typ 是否为 nil 就可以了。
// popTail removes and returns the element at the tail of the queue. // It returns false if the queue is empty. It may be called by any // number of consumers. // // popTail 删除并返回队列尾部的元素。 // 如果队列为空,则返回 false。 // 它可以被任意数量的消费者调用。(如何保证并发安全?原子操作) func(d *poolDequeue) popTail() (any, bool) { // slot 用来保存从队列尾取出来的值 var slot *eface // 获取队列尾部的值 for { ptrs := atomic.LoadUint64(&d.headTail) head, tail := d.unpack(ptrs) if tail == head { // Queue is empty. // 队列为空,直接返回 returnnil, false }
// Confirm head and tail (for our speculative check // above) and increment tail. If this succeeds, then // we own the slot at tail. // // 确认 head 和 tail(对于我们上面的推测性检查)并增加 tail。 // 如果成功,那么我们就拥有 tail 的插槽。 ptrs2 := d.pack(head, tail+1) // 新的 headTail // 如果返回 false,说明从 Load 到 CompareAndSwap 期间,有其他 goroutine 修改了 headTail。 // 则需要重新 Load,再次尝试(再次执行 for 循环)。 if atomic.CompareAndSwapUint64(&d.headTail, ptrs, ptrs2) { // Success. slot = &d.vals[tail&uint32(len(d.vals)-1)] break } }
在 sync.Pool
中,我们可以看到它有许许多多的编程技巧,为了实现一个高性能的
Pool 要做的东西是非常复杂的,
但是对于我们而言,我们只会用到它暴露出来的两个非常简单的接口
Put、Get,这其实也算是 Go
语言的一种设计哲学吧,
把复杂留给自己,把简单留给用户。但是,我们还是要知道它的实现原理,这样才能更好的使用它。
poolDequeue
中存储数据的结构是一个环形队列,是连续的内存,可以充分利用 CPU 的
cache。在访问 poolDequeue
某一项时,其附近的数据项都有可能加载到统一 cache line
中,有利于提升性能。同时它是预先分配内存的,因此其中的数据项可不断复用。
总结
最后,总结一下本文内容:
sync.Pool
是一个非常有用的工具,它可以帮助我们减少内存的分配和回收(通过复用对象),提升程序的性能。但是,我们要注意它的使用场景,它适合那些没有状态的对象,同时,我们不能对那些从
Pool 中 Get 出来的对象做任何假设。
我们在 Put 或者 Get
之前,可能需要对我们操作的对象重置一下,防止对后续的操作造成影响。
Pool
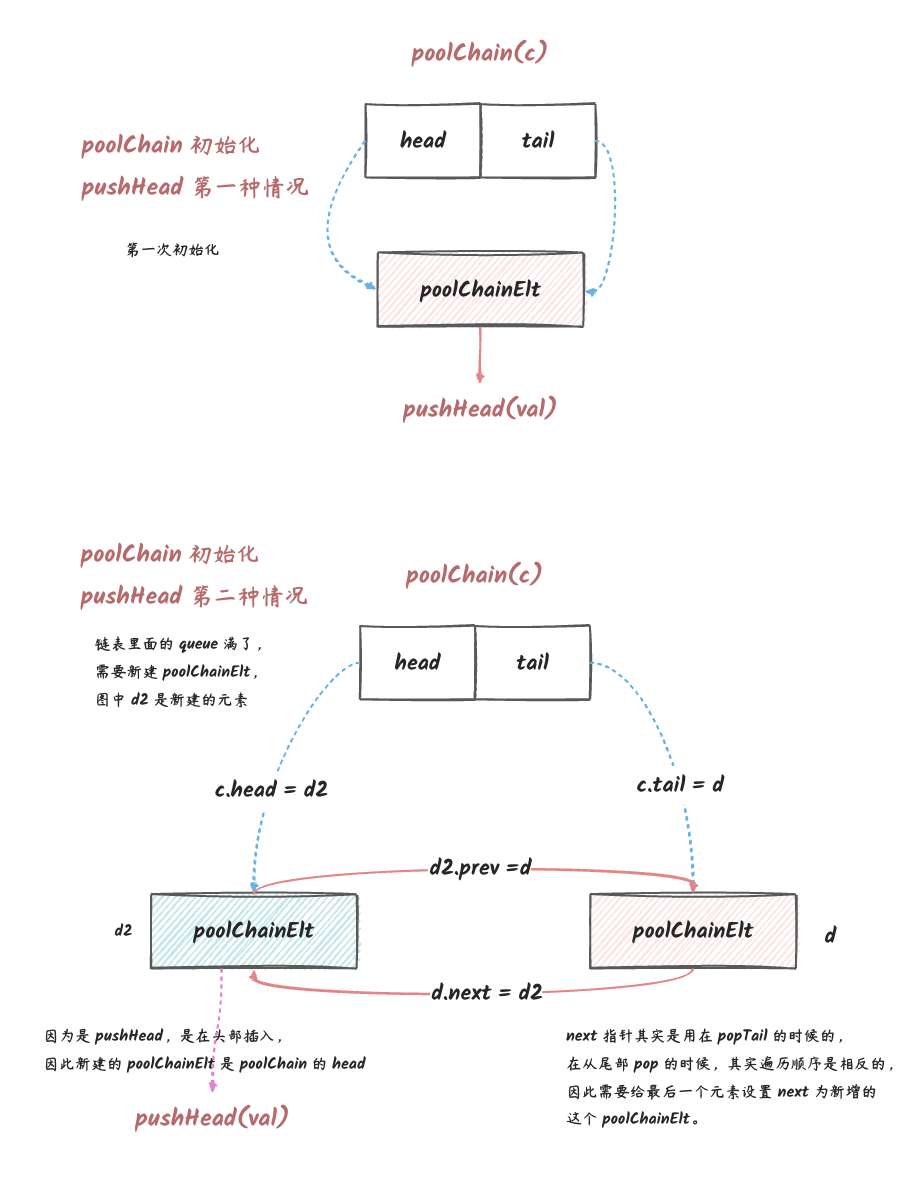
中的对象存储是使用队列的方式,这个队列的实现是一个链表(poolChain),链表的每一个节点都是一个环形队列(poolDequeue)。这个队列支持以下三种操作:
pushHead:将一个对象放到队列的头部。
popHead:将队列的头部的对象取出来。
popTail:将队列的尾部的对象取出来。
sync.Pool 的实现中,使用了很多编程技巧,比如
noCopy、pin、pad、原子操作等等,这些技巧都是为了实现一个高性能的
Pool
而做的一些优化,我们可以学习一下,具体参考上一节。
sync.Pool 中,Put 和 Get
操作的时候会先将 goroutine 与 P
绑定,然后再去操作 P 关联的
poolLocal,这样可以减少竞争,提升性能。因为每一个
P 都有一个关联的 poolLocal,所以多个
goroutine
操作的时候,可以充分利用多核。在操作完成后,再解除绑定。
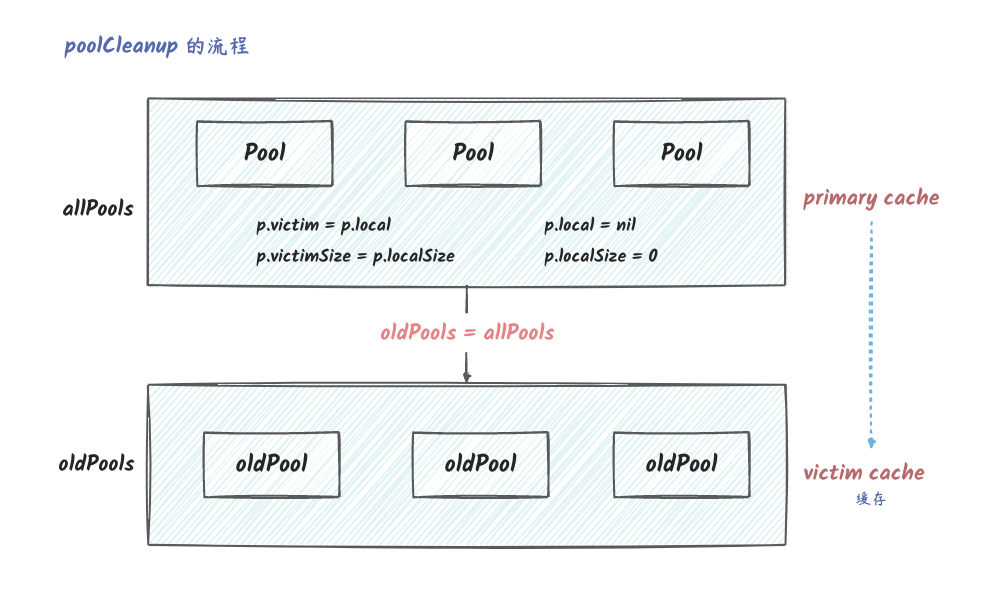
考虑到 GC 直接清除 Pool 中的对象会在
GC 后可能会产生性能抖动,所以在 GC
的时候,其实并不会马上清除 Pool
中的对象,而是将这些对象放到 victim 字段中,在
Get 的过程中,如果所有的 poolLocal
中获取不到对象,则会从 victim 中去找。但是再进行
GC 的时候,旧的 victim 会被清除。也就是
Pool 中对象的淘汰会经历两次 GC。