from langchain_openai import ChatOpenAI llm = ChatOpenAI( model_name="gpt-4", temperature=0.7, max_tokens=1000, ) from langchain.agents import Tool
tools = [ Tool( name="Get current info", func=query_web, description="""only invoke it when you need to answer question about realtime info. And the input should be a search query.""" ), Tool( name="query spotmax info", func=qa, description="""only invoke it when you need to get the info about spotmax/maxgroup/maxarch/maxchaos. And the input should be the question.""" ), Tool( name="create an image", func=create_image, description="""invoke it when you need to create an image. And the input should be the description of the image.""" ) ] from langchain.memory import ConversationBufferWindowMemory from langchain.agents import ZeroShotAgent, AgentExecutor from langchain.chains.llm import LLMChain
prefix = """Have a conversation with a human, answering the following questions as best you can. You have access to the following tools:""" suffix = """Begin!" {chat_history} Question: {input} {agent_scratchpad}"""
AgentExecutor
的处理过程如下(Thought -> Action -> Observation -> Thought -> Final Answer):
1 2 3 4 5 6 7 8 9 10 11 12 13
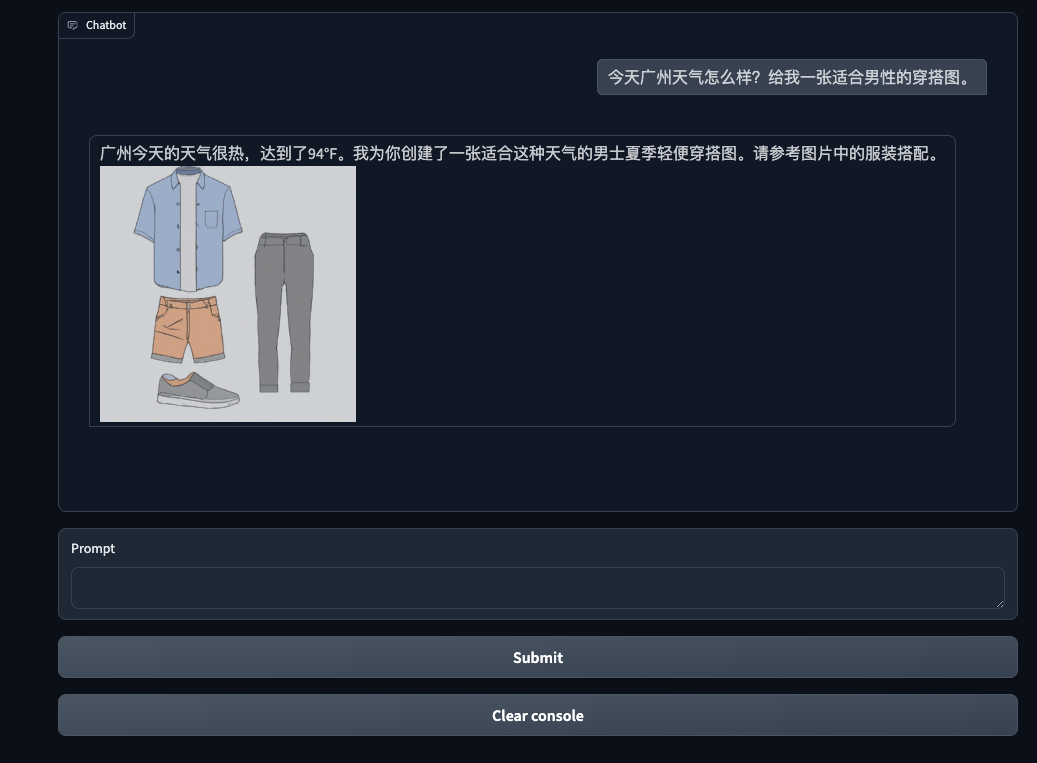
> Entering new AgentExecutor chain... Thought: The question is asking for the current weather in Guangzhou and a male outfit recommendation. I can use the 'Get current info' tool to find the weather, and the 'create an image' tool to generate the outfit image. Action: Get current info Action Input: Guangzhou weather today Observation: 94°F Thought:The weather in Guangzhou is quite hot today. Now I need to think of an outfit that would be suitable for such warm weather. Action: create an image Action Input: A light summer outfit for men suitable for 94°F weather Observation:  Thought:I now have the final answer. Final Answer: 广州今天的天气很热,达到了94°F。我为你创建了一张适合这种天气的男士夏季轻便穿搭图。请参考图片中的服装搭配。
> Finished chain.
我们可以看到在我提这个问题的时候,它做了如下操作:
思考,然后发现需要获取今天广州的天气,这是 LLM 不懂的,所以使用了
Get current info 工具。
获取到了天气信息之后,思考,然后发现需要生成一张图片,而我们有一个
create an image 工具,因此使用了这个工具来生成图片
最终返回了今天广州的天气状况以及一张图片。
当然,我们也可以问它关于本地知识库的问题,比如 “什么是
spotmax?”(根据你自己的 pdf 提问,这里只是一个示例)
from langchain_openai import ChatOpenAI llm = ChatOpenAI( model_name="gpt-4", temperature=0.7, max_tokens=1000, ) from langchain.agents import Tool
tools = [ Tool( name="Get current info", func=query_web, description="""only invoke it when you need to answer question about realtime info. And the input should be a search query.""" ), Tool( name="query spotmax info", func=qa, description="""only invoke it when you need to get the info about spotmax/maxgroup/maxarch/maxchaos. And the input should be the question.""" ), Tool( name="create an image", func=create_image, description="""invoke it when you need to create an image. And the input should be the description of the image.""" ) ] from langchain.memory import ConversationBufferWindowMemory from langchain.agents import ZeroShotAgent, AgentExecutor from langchain.chains.llm import LLMChain
prefix = """Have a conversation with a human, answering the following questions as best you can. You have access to the following tools:""" suffix = """Begin!" {chat_history} Question: {input} {agent_scratchpad}"""