一文搞懂 Golang 高性能日志库 - Zap
Zap 是由 Uber 开发的专为 Go
应用程序设计的结构化日志记录包。根据它们在 GitHub 上的 README
文档,它提供了 “极快” 的结构化、分级日志记录,且分配资源最小。
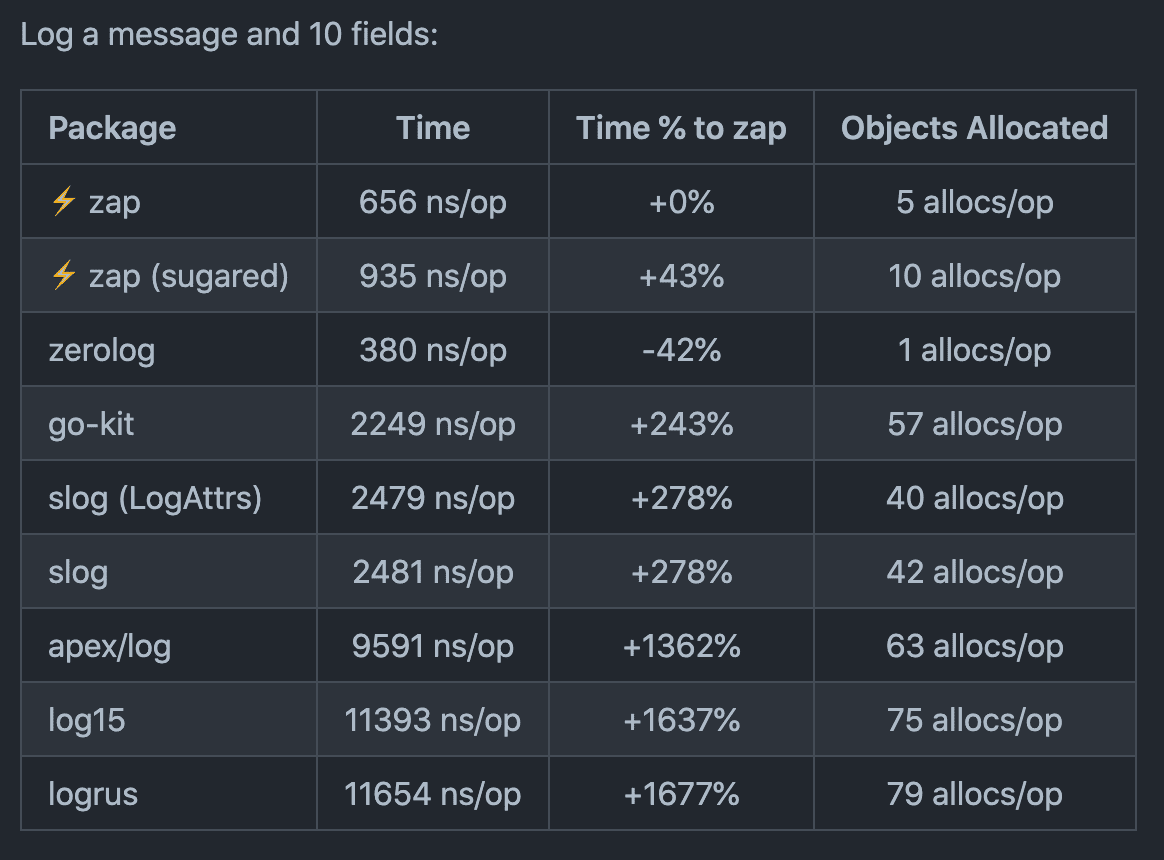
这一说法得到了它们的基准测试结果的支持,这些结果表明 Zap
在性能上几乎优于 Go 的其他大部分可比较的结构化日志记录库,除了
Zerolog:
开始使用 Zap
在开始使用Zap之前,您需要通过以下命令将其安装到您的项目中:
1 | go get -u go.uber.org/zap |
一旦你安装了 Zap,你可以像这样在你的程序中开始使用它:
1 | package main |
输出:
1 | {"level":"info","ts":1706518203.525694,"caller":"gopprof/main.go:12","msg":"Hello from Zap logger!"} |
与 Go 的大多数其他日志记录包不同,Zap
不提供预先配置的全局日志记录器供直接使用。因此,在开始记录日志之前,您必须创建一个
zap.Logger 实例。 NewProduction() 方法返回一个
Logger,配置为以 JSON
格式记录到标准错误,并将其最低日志级别设置为 INFO 。
生成的输出相对简单,没有什么意外,除了其默认的时间戳格式(ts),它以自
1970年1月1日 UTC 起经过的纳秒数呈现,而不是典型的
ISO-8601 格式。
您还可以利用 NewDevelopment
来创建更适用于开发环境的日志记录,以 DEBUG
级别记录并使用更符合人类习惯的格式:
1 | logger := zap.Must(zap.NewDevelopment()) |
输出:
1 | 2023-05-14T20:42:39.137+0100 INFO zap/main.go:12 Hello from Zap logger! |
您可以轻松地通过环境变量在开发和生产 Logger
之间进行切换:
1 | logger := zap.Must(zap.NewProduction()) |
设置全局 logger
如果您想在不先创建实例的情况下编写日志,可以在 init()
函数中使用 ReplaceGlobals() 方法:
1 | package main |
这种方法将通过 zap.L() 访问的全局记录器替换为一个功能
Logger 实例,这样你就可以直接通过将 zap
包导入到你的文件中来使用它。
Zap 基本 API
Zap 提供了两个主要的日志 API。第一个是低级别的 Logger
类型,它提供了一种结构化的记录消息的方式。
它专为在性能敏感的环境中使用而设计,其中每个分配都很重要,它只支持强类型的上下文字段:
1 | func main() { |
输出:
1 | {"level":"info","ts":1706518317.8943732,"caller":"gopprof/main.go:12","msg":"User logged in","username":"johndoe","userid":123456,"provider":"google"} |
该类型为每个支持的日志级别(Info(),Warn(),Error()等)公开了一个方法,并且每个方法都接受一个消息和零个或多个字段,这些字段是强类型的键/值对,如上例所示。
第二个高级 API 是 SugaredLogger
类型,它代表了一种更随意的日志记录方法。它的 API 比 Logger
类型更简洁,但性能略有损失。在底层,它依赖于 Logger
类型进行实际的日志记录操作。
1 | func main() { |
输出:
1 | {"level":"info","ts":1684147807.960761,"caller":"zap/main.go:17","msg":"Hello from Zap logger!"} |
一个 Logger 可以通过调用它的 Sugar()
方法转换为 SugaredLogger 类型。相反,Desugar()
方法将 SugaredLogger 转换为 Logger
,您可以根据需要执行这些转换,因为性能开销可以忽略不计。
1 | sugar := zap.Must(zap.NewProduction()).Sugar() |
这个特性意味着你不必在你的代码库中选择其中一个。例如,你可以在通常情况下默认使用
SugaredLogger
以获得灵活性,然后在性能敏感代码的边界处转换为 Logger
类型。
SugaredLogger 类型为每个支持的级别提供了四种方法:
第一个(
Info(),Error(),等等)与Logger上的level方法同名,但它接受一个或多个any类型的参数。在内部,它们使用fmt.Sprint()方法将参数连接到输出的msg属性中。以
ln结尾的方法(如Infoln()和Errorln())与第一个方法相同,只是使用fmt.Sprintln()来构建和记录消息。以
f结尾的方法使用fmt.Sprintf()方法来构建和记录一个模板化的消息。最后,以
w结尾的方法允许您向日志记录中添加强类型和弱类型的键值对混合。日志消息是第一个参数;随后的参数应该按照上面的示例以键值对的形式提供。
使用松散类型的键/值对时需要注意的一点是,键始终预期为字符串,而值可以是任何类型。如果使用非字符串键,程序将在开发中出现恐慌:
1 | sugar.Infow("User logged in", 1234, "userID") |
1 | 2023-05-15T12:06:12.996+0100 ERROR zap@v1.24.0/sugar.go:210 Ignored key-value pairs with non-string keys. {"invalid": [{"position": 0, "key": 1234, "value": "userID"}]} |
在生产环境中,会记录一个单独的错误,并跳过键/值对:
1 | {"level":"error","ts":1684148883.086758,"caller":"zap@v1.24.0/sugar.go:210","msg":"Ignored key-value pairs with non-string keys.","invalid":[{"position":0,"key":1234,"value":"userID"}],"stacktrace":"go.uber.org/zap.(*SugaredLogger).Infow\n\t/home/ayo/go/pkg/mod/go.uber.org/zap@v1.24.0/sugar.go:210\nmain.main\n\t/home/ayo/dev/demo/zap/main.go:14\nruntime.main\n\t/usr/local/go/src/runtime/proc.go:250"} |
传递一个孤立的键(没有对应的值)的行为类似:在开发中会引发恐慌,在生产中会产生错误。由于这些松散类型的键/值对存在所有这些警告,我们建议始终使用强类型的上下文字段,无论您是否使用
Logger 或 SugaredLogger。
Zap 中的日志级别
Zap 提供以下日志级别,按严重程度递增。每个级别都与相应的整数关联:
DEBUG(-1): 用于记录调试消息的有用信息。INFO(0): 用于描述正常应用程序操作的消息。WARN(1): 用于记录指示发生了可能需要注意的异常情况的消息,以防升级为更严重的问题。ERROR(2): 用于记录程序中的意外错误条件。DPANIC(3): 用于记录开发中的严重错误条件。它在开发中的行为类似于PANIC,在生产中的行为类似于ERROR。PANIC(4): 在记录错误条件后调用panic()FATAL(5): 在记录错误条件后调用os.Exit(1)
这些级别在 zapcore 包中定义,该包定义并实现了 Zap
构建的底层接口。
值得注意的是,没有 TRACE
级别,也没有办法向记录器添加自定义级别,这可能会成为一些人的瓶颈。
如前所述,生产记录器的默认日志级别是 INFO
。如果您希望修改此设置,必须创建一个自定义记录器,我们将在接下来的部分详细介绍。
创建自定义记录器(logger)
到目前为止,我们已经展示了如何通过 Zap 提供的生产和开发预设来使用默认配置。现在让我们来看看如何使用自定义配置选项创建一个实例。
使用Zap创建自定义 Logger
有两种主要方法。第一种方法是使用其 Config
类型来构建自定义记录器,如下所示:
1 | package main |
输出:
1 | {"level":"info","timestamp":"2023-05-15T12:40:16.647+0100","caller":"zap/main.go:42","msg":"Hello from Zap!","pid":2329946} |
上面的 createLogger() 函数返回一个新的
zap.Logger,它的功能类似于 NewProduction()
Logger,但有一些不同之处。 我们将 Zap
的生产配置作为我们自定义日志记录器的基础,通过调用
NewProductionEncoderConfig() 并稍微修改它,将
ts 字段更改为 timestamp ,并将时间格式更改为
ISO-8601。 zapcore 包公开了 Zap
构建在其上的接口,以便您可以自定义和扩展其功能。
该 Config 对象包含创建新 Logger
时所需的许多常见配置选项。每个字段代表的详细描述都在项目文档中,因此我们在这里不会重复列举它们,除了一些特殊情况:
OutputPaths指定一个或多个日志输出的目标(详见Open以获取更多详情)。ErrorOutputPaths类似于OutputPaths,但仅用于 Zap 内部错误,而不是由您的应用程序生成或记录的错误(例如由不匹配的松散类型键/值对引起的错误)。InitialFields指定了应该包含在从Config对象创建的每个记录器产生的每个日志条目中的全局上下文字段。我们这里只包括程序的进程 ID,但您可以添加其他有用的全局元数据,比如运行程序的 Go 版本、git 提交哈希或应用程序版本、环境或部署信息等。
一旦您设置了首选配置设置,必须调用 Build() 方法来生成
Logger。请查看 Config 和
zapcore.EncoderConfig 的文档,了解所有可用选项。
创建自定义记录器的第二种更高级的方法涉及使用 zap.New()
方法。它接受一个 zapcore.Core 接口和零个或多个选项来配置
Logger 。以下是一个示例,同时将彩色输出记录到控制台,并以
JSON 格式记录到文件中:
1 | func createLogger() *zap.Logger { |
1 | 2023-05-15T16:15:05.466+0100 INFO Hello from Zap! |
1 | {"level":"info","timestamp":"2023-05-15T16:15:05.466+0100","msg":"Hello from Zap!"} |
这个示例使用 Lumberjack
包自动旋转日志文件,以防它们变得过大。NewTee()方法将日志条目复制到两个或更多目的地。
在这种情况下,日志以带颜色的纯文本格式发送到标准输出,而 JSON
等效内容发送到logs/app.log文件。
顺便说一句,我们通常建议使用像 Logrotate 这样的外部工具来管理和轮转日志文件,而不是在应用程序本身中进行操作。
为您的日志添加上下文
如前所述,使用 Zap 进行上下文日志记录是通过在日志消息后传递强类型的键值对来完成的,就像这样:
1 | logger.Warn("User account is nearing the storage limit", |
1 | {"level":"warn","ts":1684166023.952419,"caller":"zap/main.go:46","msg":"User account is nearing the storage limit","username":"john.doe","storageUsed":4.5,"storageLimit":5} |
使用子记录器,您还可以向特定范围内产生的所有日志添加上下文属性。这有助于避免在日志点处不必要的重复。子记录器是使用
With() 上的 Logger 方法创建的:
1 | func main() { |
注意两个日志中都存在 service 和
requestID
1 | {"level":"info","ts":1684164941.7644951,"caller":"zap/main.go:52","msg":"user registration successful","service":"userService","requestID":"abc123","username":"john.doe","email":"john@example.com"} |
您可以使用相同的方法向所有日志添加全局元数据。例如,您可以像这样做,将程序的进程ID和编译程序所使用的 Go 版本包含在所有记录中:
1 | func createLogger() *zap.Logger { |
使用 Zap 记录错误
错误是最重要的日志记录目标之一,因此在采用框架之前了解框架如何处理错误是至关重要的。在
Zap 中,您可以使用 Error() 方法记录错误。如果使用
zap.Error() 方法,则输出中还包括 stacktrace 和
error 属性:
1 | logger.Error("Failed to perform an operation", |
输出:
1 | {"level":"error","ts":1684164638.0570025,"caller":"zap/main.go:47","msg":"Failed to perform an operation","operation":"someOperation","error":"something happened","retryAttempts":3,"user":"john.doe","stacktrace":"main.main\n\t/home/ayo/dev/demo/zap/main.go:47\nruntime.main\n\t/usr/local/go/src/runtime/proc.go:250"} |
对于更严重的错误,可使用 Fatal()
方法。在写入和刷新日志消息后,它会调用 os.Exit(1)。
1 | logger.Fatal("Something went terribly wrong", |
输出:
1 | {"level":"fatal","ts":1684170760.2103574,"caller":"zap/main.go:47","msg":"Something went terribly wrong","context":"main","code":500,"error":"An error occurred","stacktrace":"main.main\n\t/home/ayo/dev/demo/zap/main.go:47\nruntime.main\n\t/usr/local/go/src/runtime/proc.go:250"} |
如果错误是可恢复的,您可以使用 Panic() 方法。它记录在
PANIC 级别,并调用 panic() 而不是
os.Exit(1)。 还有一个 DPanic()
级别,只在开发中记录在 DPANIC
级别后才会引发恐慌。在生产环境中,它会在 DPANIC
级别记录,而不会实际引发恐慌。
如果您不想使用非标准级别,比如 PANIC 和
DPANIC ,您可以使用以下代码将两种方法都配置为记录在
ERROR 级别:
1 | func lowerCaseLevelEncoder( |
输出:
1 | {"level":"error","timestamp":"2023-05-15T18:55:33.534+0100","msg":"this was never supposed to happen"} |
使用 Zap 进行日志采样
日志抽样是一种技术,通过选择性地捕获和记录日志事件的子集来减少应用程序日志量。其目的是在需要全面记录日志和记录过多数据可能带来的潜在性能影响之间取得平衡。
与捕获每个日志事件不同,日志抽样允许您根据特定标准或规则选择代表性的日志消息子集。这样可以大大减少生成的日志数据量,在高吞吐量系统中尤其有益。
在Zap中,可以通过使用 zapcore.NewSamplerWithOptions()
方法来配置采样,如下所示:
1 | func createLogger() *zap.Logger { |
通过记录在指定时间间隔内具有特定级别和消息的前N个条目来采样 Zap 样本。在上述示例中,仅在一秒间隔内记录具有相同级别和消息的前 3 个日志条目。由于此处指定了 0 ,在该间隔内将丢弃每个其他日志条目。
你可以通过登录一个 for 循环来测试这个:
1 | func main() { |
因此,您应该只看到六个日志条目,而不是观察 20 个。
1 | {"level":"info","timestamp":"2023-05-17T16:00:17.611+0100","msg":"an info message"} |
在这里,只有循环的前三次迭代产生了一些输出。这是因为在其他七次迭代中产生的日志由于采样配置而被丢弃。同样,当类似条目由于负载过重或应用程序出现一连串错误而被记录多次时,Zap 会删除重复条目。
尽管日志抽样可以减少日志量和日志记录的性能影响,但也可能导致一些日志事件被忽略,从而影响故障排除和调试工作。因此,在仔细考虑特定应用程序的要求之后,才应该应用抽样。
在日志中隐藏敏感细节
一种防止意外记录具有敏感字段的类型的技术是在记录点对数据进行编辑或掩码处理。在
Zap 中,可以通过实现 Stringer
接口,然后定义在记录类型时应返回的确切字符串来实现此目的。以下是一个简短的演示:
1 | type User struct { |
输出:
1 | {"level":"info","timestamp":"2023-05-17T17:00:59.899+0100","msg":"user login","user":{"id":"USR-12345","name":"John Doe","email":"john.doe@example.com"}} |
在这个例子中,整个 user
都被记录下来,不必要地暴露了用户的电子邮件地址。您可以通过以下方式实现
Stringer 接口来防止这种情况发生:
1 | func (u User) String() string { |
这将在日志中用 ID 字段完全替换 User 类型:
1 | {"level":"info","timestamp":"2023-05-17T17:05:01.081+0100","msg":"user login","user":"USR-12345"} |
如果您需要更多控制,可以创建自己的 zapcore.Encoder,并将
JSON 编码器用作基础,同时过滤掉敏感字段:
1 | type SensitiveFieldEncoder struct { |
这段代码确保 email 属性被编辑,而其他字段保持不变:
1 | {"level":"info","timestamp":"2023-05-17T17:38:11.749+0100","msg":"user login","user":{"id":"USR-12345","name":"John Doe","email":"[REDACTED]"}} |
当然,如果 User 类型被记录在不同的键下,比如
user_details ,这样做就不会有太大帮助。您可以移除
if field.Key == "user"
条件,以确保无论提供的键是什么,都会执行编辑。
自定义编码器的一些注意事项
在使用Zap的自定义编码时,就像在前一节中一样,您可能还需要在
zapcore.Encoder 接口上实现 Clone()
方法,以便它也适用于使用 With() 方法创建的子记录器:
1 | child := logger.With(zap.String("name", "main")) |
在实施 Clone() 之前,您会注意到自定义
EncodeEntry()
不会为子记录器执行,导致电子邮件字段显示为未编辑状态:
1 | {"level":"info","timestamp":"2023-05-20T09:14:46.043+0100","msg":"an info log","name":"main","user":{"id":"USR-12345","name":"John Doe","email":"john.doe@example.com"}} |
当 With() 用于创建子记录器时,将执行配置的
Encoder 上的 Clone()
方法来复制它,并确保添加的字段不会影响原始记录器。
如果在自定义编码器类型上未实现此方法,则将调用嵌入的
zapcore.Encoder(在本例中为JSON编码器)上声明的
Clone() 方法,这意味着子记录器将不使用您的自定义编码。
您可以通过以下方式实现 Clone() 方法来纠正这种情况:
1 | func (e *SensitiveFieldEncoder) Clone() zapcore.Encoder { |
您现在将观察到正确的已编辑输出:
1 | {"level":"info","timestamp":"2023-05-20T09:28:31.231+0100","msg":"an info log","name":"main","user":{"id":"USR-12345","name":"John Doe","email":"[REDACTED]"}} |
然而,请注意,自定义编码器不会影响使用 With()
方法附加的字段,因此如果您这样做:
1 | child := logger.With(zap.String("name", "main"), zap.Any("user", u)) |
无论是否实现 Clone(),您都将获得先前的未编辑输出,因为
EncodeEntry() 的参数中只有在日志点添加的字段存在:
1 | {"level":"info","timestamp":"2023-05-20T09:31:11.919+0100","msg":"an info log","name":"main","user":{"id":"USR-12345","name":"John Doe","email":"john.doe@example.com"}} |
将 Zap 用作 Slog 的后端
Go 语言引入了新的结构化日志包Slog后,开始着手在 Zap 中实现
slog.Handler 接口,以便利用 Slog API 与
Zap 后端。这种集成确保了在各种依赖项中日志 API
的一致性,并便于无需大幅更改代码即可无缝切换日志包。
目前为止,Slog 尚未包含在官方的 Go
发布版本中。因此,Zap 与 Slog
的官方集成已经提供在一个单独的模块中,可以使用以下命令进行安装:
1 | go get go.uber.org/zap/exp/zapslog |
之后,您可以在您的程序中像这样使用它:
1 | func main() { |
输出:
1 | {"level":"info","ts":1684613929.8395753,"msg":"incoming request","method":"GET","path":"/api/user","status":200} |
如果您决定切换到不同的后端,唯一需要更改的是 slog.New()
方法的参数。例如,您可以通过进行以下更改从 Zap 切换到 Slog
的 JSONHandler 后端:
1 | func main() { |
除了日志输出可能会根据您的配置略有不同之外,其他一切都应该继续正常工作。
1 | {"time":"2023-05-20T21:21:43.335894635+01:00","level":"INFO","msg":"incoming request","method":"GET","path":"/api/user","status":200} |
总结
本文分析了 Zap 包,这是 Go
程序中最受欢迎的日志包之一。文章重点介绍了该包的许多关键特性,还涵盖了一些高级日志技术,以及如何将其与新的标准库
Slog 包集成。