go interface 设计与实现
在上一篇文章《go
interface 基本用法》中,我们了解了 go 中 interface
的一些基本用法,其中提到过
接口本质是一种自定义类型,本文就来详细说说为什么说
接口本质是一种自定义类型,以及这种自定义类型是如何构建起 go
的 interface 系统的。
本文使用的源码版本: go 1.19。另外本文中提到的
interface和接口是同一个东西。
前言
在了解 go interface
的设计过程中,看了不少资料,但是大多数资料都有生成汇编的操作,但是在我的电脑上指向生成汇编的操作的时候,
生成的汇编代码却不太一样,所以有很多的东西无法验证正确性,这部分内容不会出现在本文中。本文只写那些经过本机验证正确的内容,但也不用担心,因为涵盖了
go interface
设计与实现的核心部分内容,但由于水平有限,所以只能尽可能地传达我所知道的关于
interface
的一切东西。对于有疑问的部分,有兴趣的读者可以自行探索。
如果想详细地了解,建议还是去看看
iface.go,里面有接口实现的一些关键的细节。但是还是有一些东西被隐藏了起来,
导致我们无法知道我们 go 代码会是 iface.go
里面的哪一段代码实现的。
接口是什么?
接口(
interface)本质上是一种结构体。
我们先来看看下面的代码:
1 | // main.go |
我们可以通过 go tool compile -N -S -l main.go 命令来生成
main.go
的伪汇编代码,生成的代码会很长,下面省略所有跟本文主题无关的代码:
1 | // main.go:10 => println(f1) |
我们从这段汇编代码中可以看到,我们 println(f1)
实际上是对 runtime.printeface 的调用,我们看看这个
printeface 方法:
1 | func printeface(e eface) { |
我们看到了,这个 printeface 接收的参数实际上是
eface 类型,而不是 interface{}
类型,我们再来看看 println(f2) 实际调用的
runtime.printiface 方法:
1 | func printiface(i iface) { |
也就是说 interface{} 类型在底层实际上是
eface 类型,而 Flyable 类型在底层实际上是
iface 类型。
这就是本文要讲述的内容,go 中的接口变量其实是用 iface 和
eface 这两个结构体来表示的:
iface表示某一个具体的接口(含有方法的接口)。eface表示一个空接口(interface{})
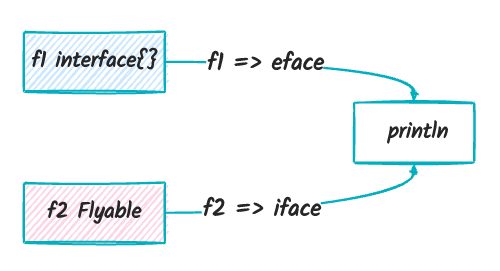
iface 和 eface 结构体
iface 和 eface
的结构体定义(runtime/iface.go):
1 | // 非空接口(如:io.Reader) |
go 底层的类型信息是使用
_type结构体来存储的。
比如,我们有下面的代码:
1 | package main |
在上面代码中,efc 是 eface
类型的变量,对应到 eface 结构体的话,_type
就是 Bird 这个类型本身,而 data 就是
&bird 这个指针:
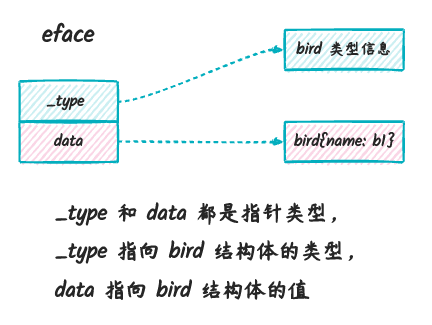
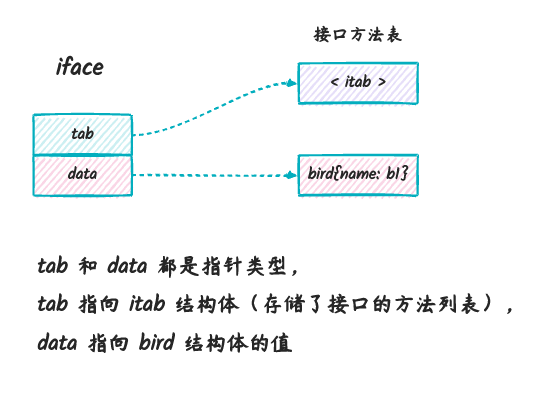
类似的,ifc 是 iface 类型的变量,对应到
iface 结构体的话,data 也是
&bird 这个指针:
_type 是什么?
在 go 中,_type
是保存了变量类型的元数据的结构体,定义如下:
1 | // _type 是 go 里面所有类型的一个抽象,里面包含 GC、反射、大小等需要的细节, |
这个 _type 结构体定义大家随便看看就好了,实际上,go
底层的类型表示也不是上面这个结构体这么简单。
但是,我们需要知道的一点是(与本文有关的信息),通过
_type 我们可以得到结构体里面所包含的方法这些信息。
具体我们可以看 itab 的 init
方法(runtime/iface.go),我们会看到如下几行:
1 | typ := m._type |
在底层,go 是通过 _type 里面 uncommon
返回的地址,加上一个偏移量(x.moff)来得到实际结构体类型的方法列表的。
我们可以参考一下下图想象一下:
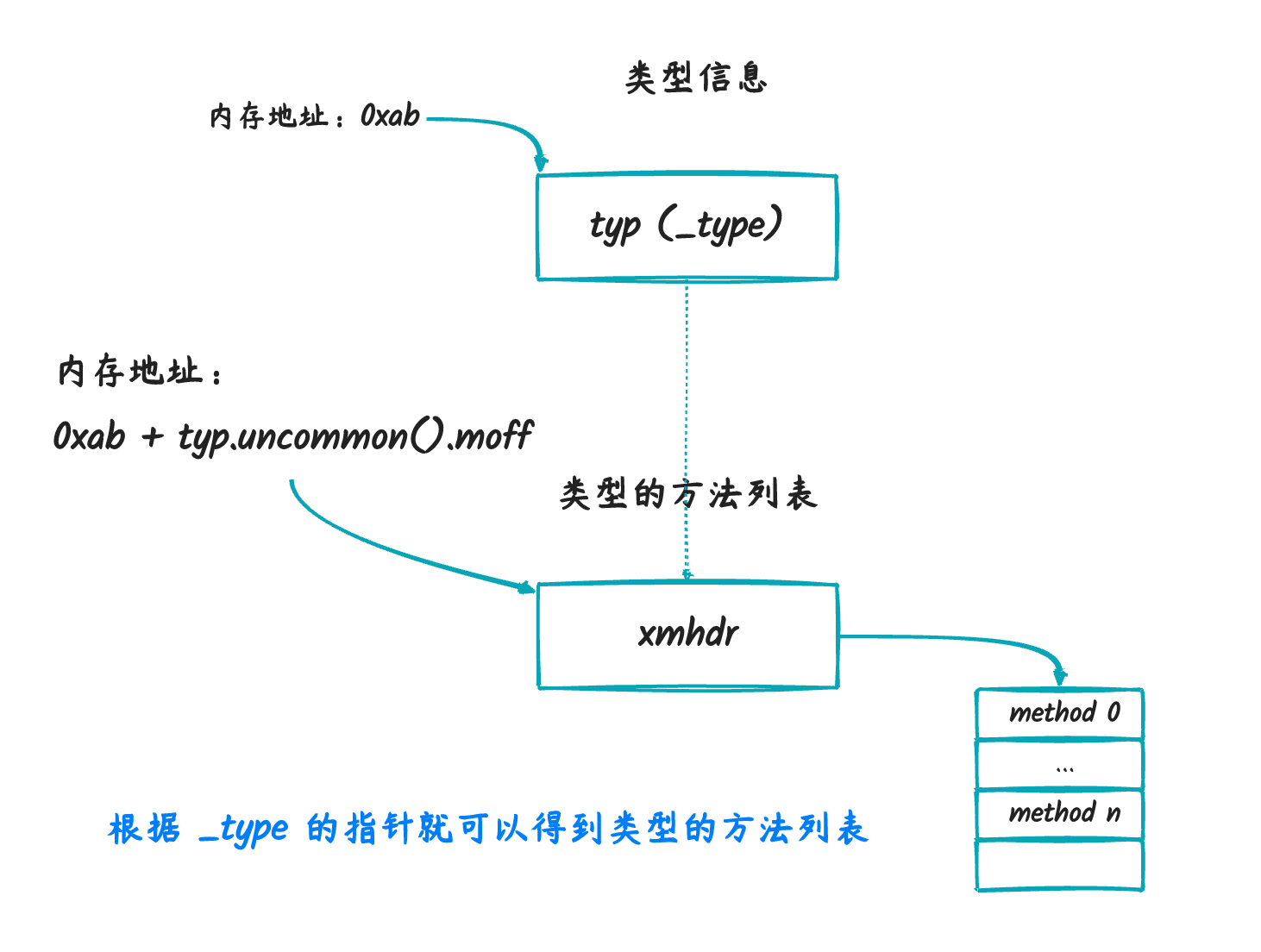
itab 是什么?
我们从 iface 中可以看到,它包含了一个 *itab
类型的字段,我们看看这个 itab 的定义:
1 | // 编译器已知的 itab 布局 |
根据
interfacetype我们可以得到关于接口所有方法的信息。同样的,通过_type也可以获取结构体类型的所有方法信息。
从定义上,我们可以看到 itab 跟
*interfacetype 和 *_type
有关,但实际上有什么关系从定义上其实不太能看得出来,
但是我们可以看它是怎么被使用的,现在,假设我们有如下代码:
1 | // i 在底层是一个 interfacetype 类型 |
下图描述了上面代码对应的 itab 生成的过程:
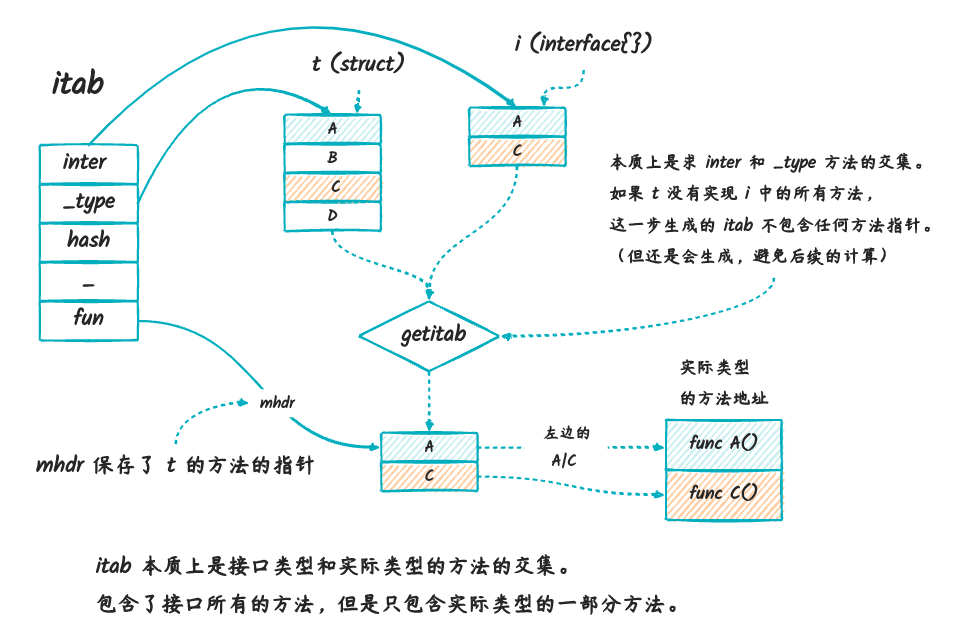
说明:
itab里面的inter是接口类型的指针(比如通过type Reader interface{}这种形式定义的接口,记录的是这个类型本身的信息),这个接口类型本身定义了一系列的方法,如图中的i包含了A、C两个方法。_type是实际类型的指针,记录的是这个实际类型本身的信息,比如这个类型包含哪些方法。图中的i实现了A、B、C、D四个方法,因为实现了i的所有方法,所以说t实现了i接口。- 在底层做类型转换的时候,比如
t转换为i的时候(var v i = t{}),会生成一个itab,如果t没有实现i中的所有方法,那么生成的itab中不包含任何方法。 - 如果
t实现了i中的所有方法,那么生成的itab中包含了i中的所有方法指针,但是实际指向的方法是实际类型的方法(也就是指向的是t中的方法地址) mhdr就是itab中的方法表,里面的方法名就是接口的所有方法名,这个方法表中保存了实际类型(t)中同名方法的函数地址,通过这个地址就可以调用实际类型的方法了。
所以,我们有如下结论:
itab实际上定义了interfacetype和_type之间方法的交集。作用是什么呢?就是用来判断一个结构体是否实现某个接口的。itab包含了接口的所有方法,这里面的方法是实际类型的子集。itab里面的方法列表包含了实际类型的方法指针(也就是实际类型的方法的地址),通过这个地址可以对实际类型进行方法的调用。itab在实际类型没有实现接口的所有方法的时候,生成失败(失败的意思是,生成的itab里面的方法列表是空的,在底层实现上是用fun[0] = 0来表示)。
生成的 itab 是怎么被使用的?
go 里面定义了一个全局变量 itabTable,用来缓存
itab,因为在判断某一个结构体是否实现了某一个接口的时候,
需要比较两者的方法集,如果结构体实现了接口的所有方法,那么就表明结构体实现了接口(这也就是生成
itab 的过程)。
如果在每一次做接口断言的时候都要做一遍这个比较,性能无疑会大大地降低,因此
go 就把这个比较得出的结果缓存起来,也就是 itab。
这样在下一次判断结构体是否实现了某一个接口的时候,就可以直接使用之前的
itab,性能也就得到提升了。
1 | // 表里面缓存了 itab |
itabTableType 里面的 entries
是一个哈希表,在实际保存的时候,会用 interfacetype 和
_type 这两个生成一个哈希表的键。 也就是说,这个保存
itab 的缓存哈希表中,只要我们有 interfacetype
和 _type 这两个信息,就可以获取一个 itab。
具体怎么使用,我们可以看看下面的例子:
1 | package main |
我们对上面的代码生成伪汇编代码:
1 | GOOS=linux GOARCH=amd64 go tool compile -N -S -l main.go > main.s |
然后我们去查看
main.s,就会发现类型断言的代码,本质上是对
runtime.assert*
方法的调用(assertI2I、assertI2I2、assertE2I、assertE2I2),
这几个方法名都是以 assert 开头的,assert
在编程语言中的含义是,判断后面的条件是否为 true,如果
false 则抛出异常或者其他中断程序执行的操作,为
true 则接着执行。
这里的用处就是,判断一个接口是否能够转换为另一个接口或者另一个类型。
但在这里有点不太一样,这里有两个函数最后有个数字 2
的,表明了我们对接口的类型转换会有两种情况,我们上面的代码生成的汇编其实已经很清楚了,
一种情况是直接断言,使用 i.(T)
这种形式,另外一种是在 switch...case
里面使用,。
我们可以看看它们的源码,看看有什么不一样:
1 | // 直接根据 interfacetype/_type 获取 itab |
getitab的源码后面会有。
从上面的代码可以看到,其实带 2 和不带 2
后缀的关键区别在于:getitab 的调用允不允许失败。
这有点类似于 chan 里面的
select,chan 的 select 语句中读写
chan 不会阻塞,而其他地方会阻塞。
assertE2I2 是用在 switch...case
中的,这个调用是允许失败的,因为我们还需要判断能否转换为其他类型;
又或者 v, ok := i.(T)
的时候,也是允许失败的,但是这种情况会返回第二个值给用户判断是否转换成功。
而直接使用类型断言的时候,如 i.(T) 这种,如果
i 不能转换为 T 类型,则直接
panic。
对于 go 中的接口断言可以总结如下:
assertI2I用于将一个iface转换为另一个iface,转换失败的时候会panicassertI2I2用于将一个iface转换为另一个iface,转换失败的时候不会panicassertE2I用于将一个eface转换为另一个iface,转换失败的时候会panicassertE2I2用于将一个eface转换为另一个iface,转换失败的时候不会panicassert相关的方法后缀的I2I、E2E里面的I表示的是iface,E表示的是eface- 带
2后缀的允许失败,用于v, ok := i.(T)或者switch x.(type) ... case中 - 不带
2后缀的不允许失败,用于i.(T)这种形式中
当然,这里说的转换不是说直接转换,只是说,在转换的过程中会用到 assert* 方法。
如果我们足够细心,然后也去看了 assertI2I 和
assertI2I2 的源码,就会发现,这几个方法本质上都是, 通过
interfacetype 和 _type 来获取一个
itab 然后转换为另外一个 itab 或者 `iface。
同时,我们也应该注意到,上面的转换都是转换到 iface 而没有转换到 eface 的操作,这是因为,所有类型都可以转换为空接口(interface{},也就是 eface)。根本就不需要断言。
上面的内容可以结合下图理解一下:
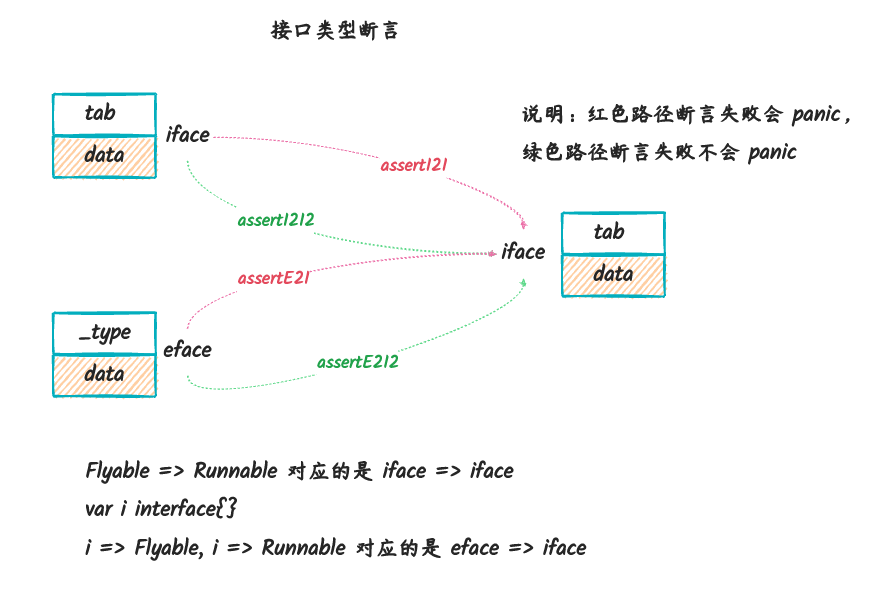
itab 关键方法的实现
下面,让我们再来深入了解一下 itab
是怎么被创建出来的,以及是怎么保存到全局的哈希表中的。我们先来看看下图:
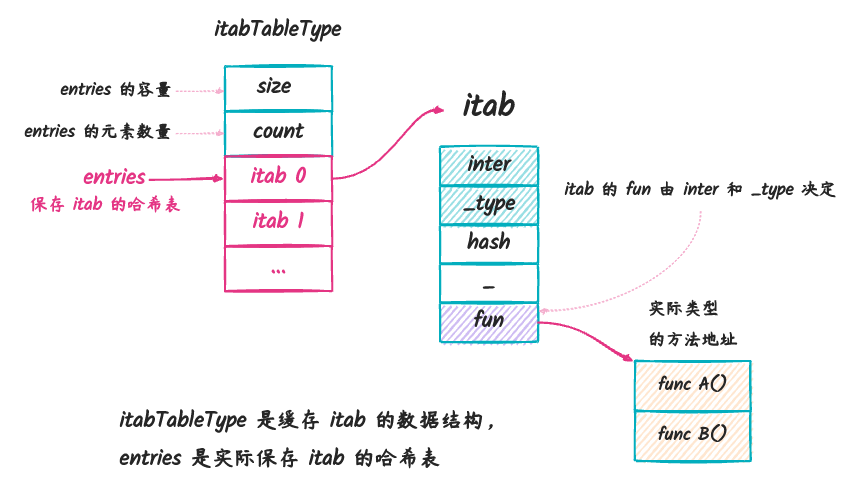
这个图描述了 go 底层存储 itab 的方式:
- 通过一个
itabTableType类型来存储所有的itab。 - 在调用
getitab的时候,会先根据inter和_type计算出哈希值,然后从entries中查找是否存在,存在就返回对应的itab,不存在则新建一个itab。 - 在调用
itabAdd的时候,会将itab加入到itabTableType类型变量里面的entries中,其中entries里面的键是根据inter和_type做哈希运算得出的。
itab 两个比较关键的方法:
getitab让我们可以通过interfacetype和_type获取一个itab,会现在缓存中找,找不到会新建一个。itabAdd是在我们缓存找不到itab,然后新建之后,将这个新建的itab加入到缓存的方法。
getitab 方法的第三个参数 canfail
表示当前操作是否允许失败,上面说了,如果是用在
switch...case 或者 v, ok := i.(T)
这种是允许失败的。
1 | // 获取某一个类型的 itab(从 itabTable 中查找,键是 inter 和 _type 的哈希值) |
itabAdd 将给定的 itab 添加到
itab 哈希表中(itabTable)。
注意:
itabAdd中在判断到哈希表的使用量超过75%的时候,会进行扩容,新的容量为旧容量的 2 倍。
1 | // 必须保持 itabLock。 |
其实 itabAdd
的关键路径比较清晰,只是因为它是一个哈希表,所以里面在判断到当前
itab 的数量超过 itabTable 容量的
75% 的时候,会对 itabTable 进行 2 倍扩容。
根据 interfacetype 和 _type 初始化 itab
上面那个图我们说过,itab 本质上是
interfacetype 和 _type
方法的交集,这一节我们就来看看,itab
是怎么根据这两个类型来进行初始化的。
itab 的 init 方法实现:
1 | // init 用 m.inter/m._type 对的所有代码指针填充 m.fun 数组。 |
接口断言过程总览(类型转换的关键)
具体来说有四种情况,对应上面提到的 runtime.assert*
方法:
- 实际类型转换到
iface iface转换到另一个iface- 实际类型转换到
eface eface转换到iface
这其中的关键是
interfacetype+_type可以生成一个itab。
上面的内容可能有点混乱,让人摸不着头脑,但是我们通过上面的讲述,相信已经了解了 go 接口中底层的一些实现细节,现在,就让我们重新来捋一下,看看 go 接口到底是怎么实现的:
首先,希望我们可以达成的一个共识就是,go
的接口断言本质上是类型转换,switch...case 里面或
v, ok := i.(T) 允许转换失败,而 i.(T).xx()
这种不允许转换失败,转换失败的时候会 panic。
接着,我们就可以通过下图来了解 go 里面的接口整体的实现原理了(还是以上面的代码作为例子):
- 将结构体赋值给接口类型:
var f Flyable = Bird{}
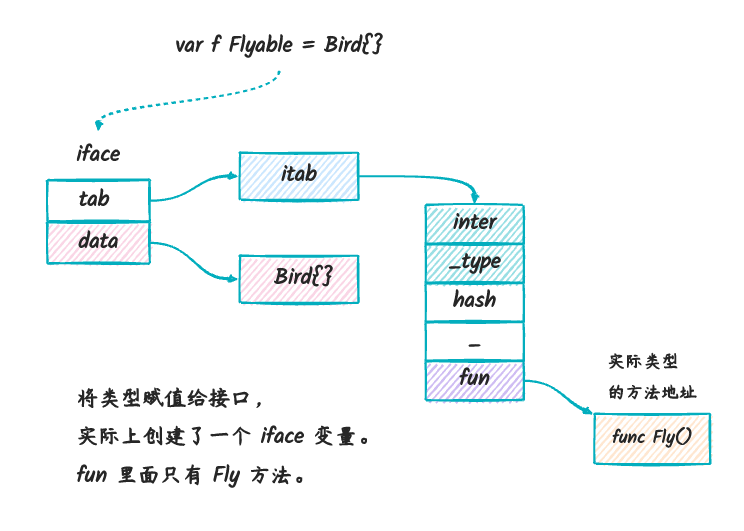
在这个赋值过程中,创建了一个 iface
类型的变量,这个变量中的 itab 的方法表只包含了
Flyable 定义的方法。
iface转另一个iface:
f.(Runnable)_, ok := f.(Runnable)switch f.(type)里面的case是Runnable
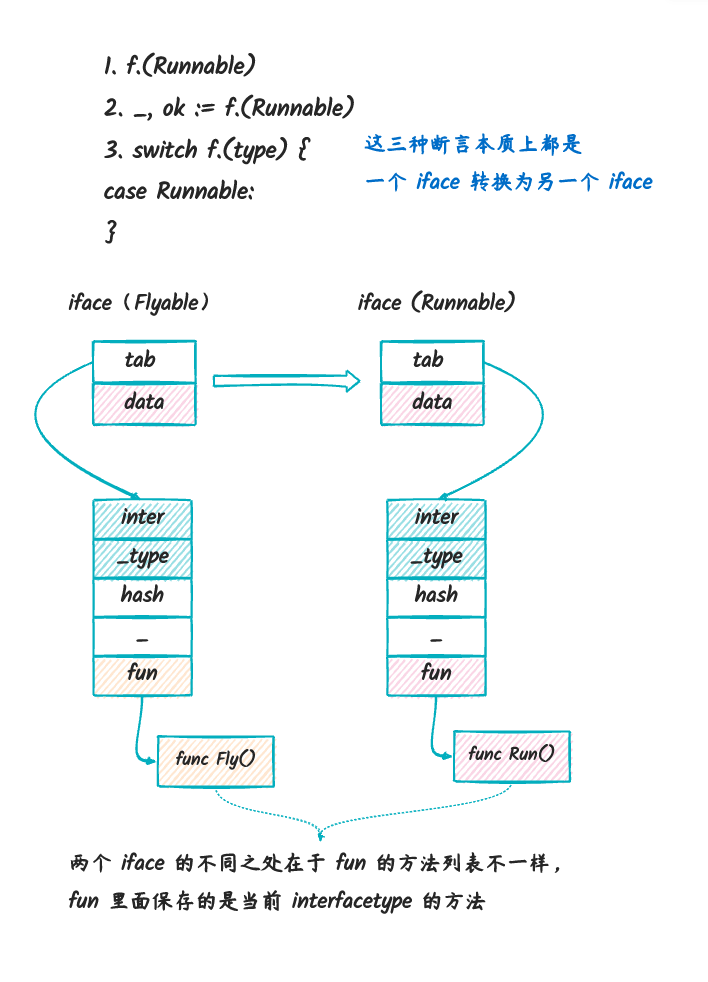
在这个断言过程中,会将 Flyable 转换为
Runnable,本质上是一个 iface 转换到另一个
iface。但是有个不同之处在于, 两个 iface
里面的方法列表是不一样的,只包含了当前 interfacetype
里面定义的方法。
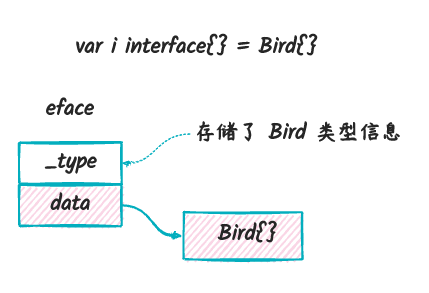
- 将结构体赋值给空接口:
var i interface{} = Bird{}
在这个过程中,创建了一个 eface 类型的变量,这个
eface 里面只包含了类型信息以及实际的 Bird
结构体实例。
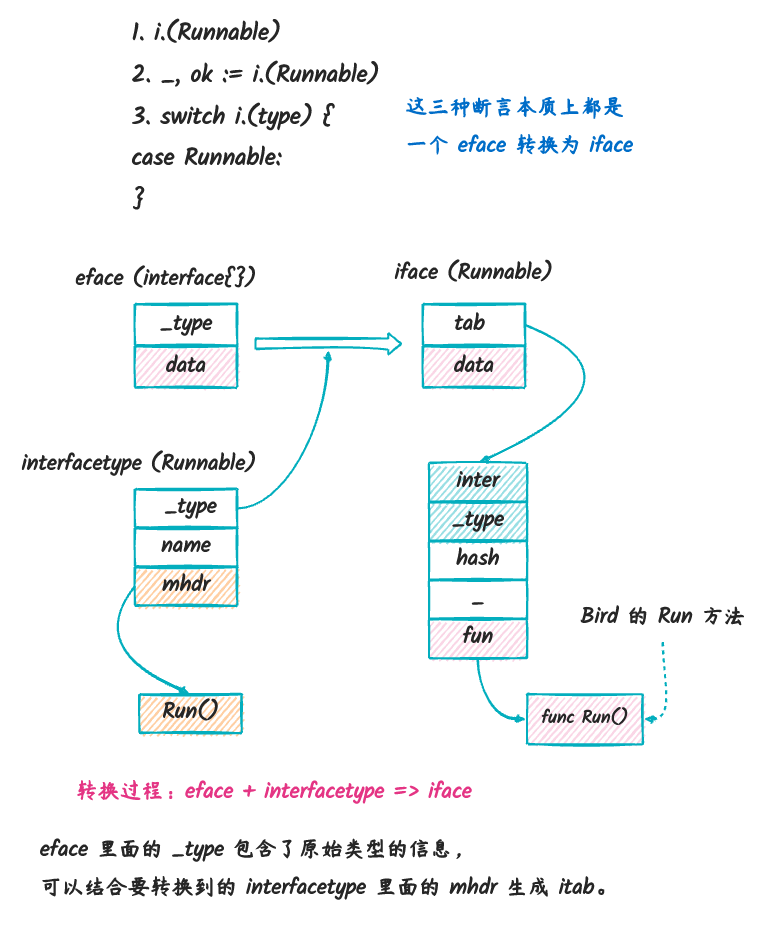
eface转换到iface
i.(Flyable)_, ok := i.(Runnable)switch i.(type)里面的case是Flyable
因为 _type 包含了 Bird 类型的所有信息,而
data 包含了 Bird
实例的值,所以这个转换是可行的。
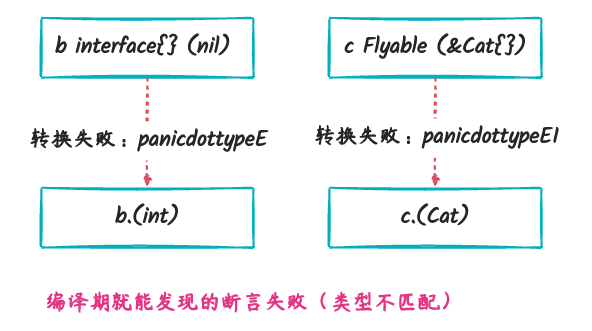
panicdottypeI 与 panicdottypeE
从前面的几个小节,我们知道,go 的 iface 类型转换使用的是
runtime.assert* 几个方法,还有另外一种情况就是,
在编译期间编译器就已经知道了无法转换成功的情况,比如下面的代码:
1 | package main |
上面的两个转换都是错误的,第一个 b.(int) 尝试将
nil 转换为 int 类型,第二个尝试将
*Cat 类型转换为 Cat 类型,
这两个错误的类型转换都在编译期可以发现,因此它们生成的汇编代码调用的是
runtime.panicdottypeE 和 runtime.panicdottypeI
方法:
1 | // 在执行 e.(T) 转换时如果转换失败,则调用 panicdottypeE |
这两个方法都是引发一个
panic,因为我们的类型转换失败了:
iface 和 eface 里面的 data 是怎么来的?
我们先看看下面的代码:
1 | package main |
我们生成伪汇编代码发现,里面将结构体变量赋值给接口类型变量的时候,实际上是调用了
convT 方法。
convT* 方法
iface 里面还包含了几个 conv*
前缀的函数,在我们将某一具体类型的值赋值给接口类型的时候,go
底层会将具体类型的值通过 conv* 函数转换为
iface 里面的 data 指针:
1 | // convT 将 v 指向的 t 类型的值转换为可以用作接口值的第二个字的指针(接口的第二个字是指向 data 的指针)。 |
我们发现,在这个过程,实际上是将值复制了一份:
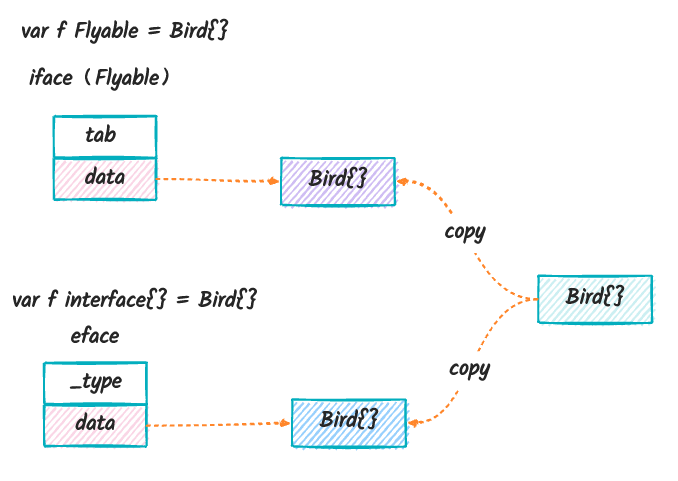
iface.go 里面还有将无符号值转换为 data
指针的函数,但是还不知道在什么地方会用到这些方法,如:
1 | // 转换 uint16 类型值为 interface 里面 data 的指针。 |
个人猜测,仅仅代表个人猜测,在整数赋值给 iface 或者
eface
的时候会调用这类方法。不管调不调用,我们依然可以看看它的设计,因为有些值得学习的地方:
staticuint64s 是一个全局整型数组,里面存储的是
0~255 的整数。上面的代码可以表示为下图:
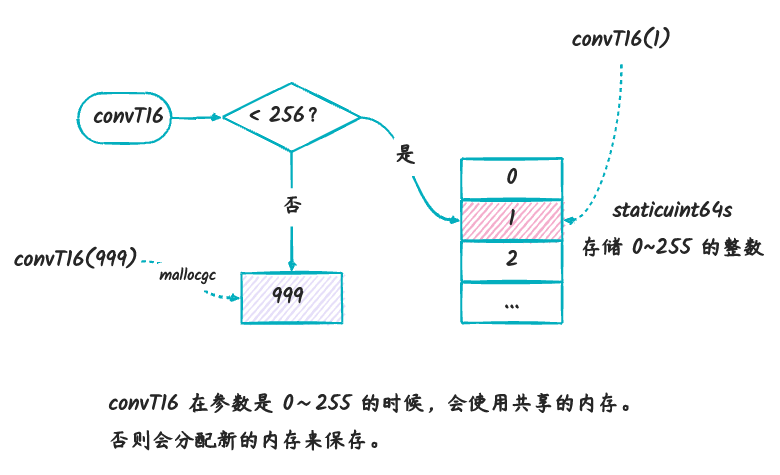
这个函数跟上面的 convT
的不同之处在于,它在判断整数如果小于 256 的时候,则使用的是
staticuint64s 数组里面对应下标的地址。
为什么这样做呢?本质上是为了节省内存,因为对于数字来说,其实除了值本身,没有包含其他的信息了,所以如果对于每一个整数都分配新的内存来保存,
无疑会造成浪费。按 convT16 里面的实现方式,对于
0~255
之间的整数,如果需要给它们分配内存,就可以使用同一个指针(指向
staticuint64s[] 数组中元素的地址)。
这实际上是享元模式。
Java 里面的小整数享元模式
go 里使用 staticuint64s 的方式,其实在 Java
里面也有类似的实现,Java 中对于小整数也是使用了享元模式,
这样在装箱的时候,就不用分配新的内存了,就可以使用共享的一块内存了,当然,某一个整数能节省的内存非常有限,如果需要分配内存的小整数非常大,那么节省下来的内存就非常客观了。
当然,也不只是能节省内存这唯一的优点,从另一方面说,它也节省了垃圾回收器回收内存的开销,因为不需要管理那么多内存。
我们来看看 Java 中的例子:
1 | class Test { |
Java 里面有点不一样,它是对 -128~127
范围内的整数做了享元模式的处理,而 go 里面是 0~255。
上面的代码中,当我们使用 == 来比较 Integer
的时候,值相等的两个数,在 -128~127 的范围的时候,返回的是
true,超出这个范围的时候比较返回的是 false。
这是因为在 -128~127
的时候,值相等的两个数字指向了相同的内存地址,超出这个范围的时候,值相等的两个数指向了不同的地址。
Java 的详细实现可以看
java.lang.Integer.IntegerCache。
总结
- go 的的接口(
interface)本质上是一种结构体,底册实现是iface和eface,iface表示我们通过type i interface{}定义的接口,而eface表示interface{}/any,也就是空接口。 iface里面保存的itab中保存了具体类型的方法指针列表,data保存了具体类型值的内存地址。eface里面保存的_type包含了具体类型的所有信息,data保存了具体类型值的内存地址。itab是底层保存接口类型跟具体类型方法交集的结构体,如果具体类型实现了接口的所有方法,那么这个itab里面的保存有指向具体类型方法的指针。如果具体类型没有实现接口的全部方法,那么itab中的不会保存任何方法的指针(从itab的作用上看,我们可以看作是一个空的itab)。- 不管
itab的方法列表是否为空,interfacetype和_type比较之后生成的itab会缓存下来,在后续比较的时候可以直接使用缓存。 _type是 go 底层用来表示某一个类型的结构体,包含了类型所需空间大小等信息。- 类型断言
i.(T)本质上是iface到iface的转换,或者是eface到iface的转换,如果没有第二个返回值,那么转换失败的时候会引发panic。 switch i.(type) { case ...}本质上也是iface或eface到iface的转换,但是转换失败的时候不会引发panic。- 全局的保存
itab的缓存结构体,底层是使用了一个哈希表来保存itab的,在哈希表使用超过75%的时候,会触发扩容,新的哈希表容量为旧的2倍。 staticuint64s使用了享元模式,Java 中也有类似的实现。