对构建高质量软件的一点点理解
最近在实现一个 go 云存储库的过程中,思考了比较多关于软件设计的问题,这里就简单记录一下思考的东西吧。
对于很多人来说,我也一样,工作多年了,对于实现需求这一点上没啥问题,但是写出来的代码大部分情况都是难以维护的。毕竟很多情况下,在要求的时间内把功能实现已经是一件比较艰难的事了。
这样的结果便是,代码改起来往往比较痛苦,本文就聊聊我们可以做点什么,让我们在开发的过程中不那么痛苦(当然,最简单直接的办法当然是加入某团、某滴。)。
设计原则
设计原则,也就是 SOLID(单一职责原则、开闭原则、里氏替换原则、接口隔离原则、依赖倒置原则)。我就不说里氏替换原则和接口隔离原则了,还没有深入地去实践过,没有发言权。个人观点,也许你可以不那么懂设计模式,但是这几个设计原则最好还是可以了解一下,因为这些原则离我们更加近,而设计模式往往在特定场景下才需要。
- 单一职责原则:这里举一些反例吧
- 最常见的不好的写法是,service 里面一个方法做完了一个请求的全部事情,比如参数校验、业务逻辑、数据库查询。 => 更好的做法也许是将数据库访问的代码从业务逻辑中抽离出去。
- 又或者在一个方法里面混杂了不同抽象层级的代码,比如一个方法要做两件事,A、B,A 有方法封装起来了,但是 B 没有,然后我们可能会看到这样的代码,调用 A 方法,然后在当前的方法内去实现 B 的逻辑,包含了全部 B 的细节部分的内容。=> 也许更好的处理方式是,将 B 也重构为一个方法,我们在阅读的时候,可以看到清晰的逻辑 A->B->...,而不是在看完 A 之后,迷失在 B 的细节之中。
- 做了不该做的事情,比如在处理当前业务的代码中,却中途穿插了其他业务模块的逻辑代码。 => 更好的方法也许将其他业务模块的代码从中抽取出去。
- 开闭原则:要做到这一点,我们要在开发的时候就预留可以扩展点,主要目的是为了让后续增加功能的时候,可以尽量少改或者不改旧的代码,通过增加代码就实现新的功能。
- 比如,
Laravel框架里面,我们可以很容易地通过ServiceProvider来扩展框架的功能,但是不需要对框架本身做任何修改(也就是说Laravel对扩展是开放的,对修改是封闭的)。
- 比如,
- 依赖倒置原则:简单来说就是高层模块跟底层模块不相互依赖,两者共同依赖于抽象出来的接口。
- 比如在
Laravel中,我们使用Cache的时候,并不关心具体使用的是哪一种缓存(有可能是 redis、memcached、file),我们需要只知道Cache给我们提供了哪些接口就可以使用缓存这个功能了。同样的,Laravel框架在实现缓存的redis、file驱动的时候,也不需要关心应用开发者是怎么使用缓存这个功能的,因为Cache接口已经规定了有哪些接口,缓存驱动之需要实现这些接口就足够了。 - 因为抽象是基本不会变的,会变的是底层细节部分。这样一来,底层细节发生变动的时候,对应用开发者是完全透明的,因为应用开发者依赖的抽象接口并没有发生变动。
- 比如在
软件结构
窃以为,好的软件结构应该是自顶向下、逐步细化的,我们去阅读一个软件的时候,应该先看到的是其顶层设计结构里面有哪些功能模块,然后从某一个功能模块进去,我们可以看到这个功能模块里面有哪些子模块,然后到子模块的实现细节等。
在今天我们很多项目中,也许从某一个角度来说,符合这种结构。从哪个角度呢?从业务需求的角度。但现实是,业务需求之间往往有很多关联,每一个业务之间肯定不会是完全独立的,每一个业务的子模块也不是完全独立的。如果只是仅仅按照业务功能来进行软件模块的设计的话,不同业务模块之间的相互依赖最终会导致非常高的耦合产生。
好像 DDD 是关于这方面的,但是没有过太深入的了解,读者感兴趣可以自行阅读。
关于这一点,个人没有想到太多具体可行的办法,但是在编码过程中,多思考一下我们这个模块大概是什么样子的会有利于我们设计出一个结构良好的模块。
简单的接口
虽然子标题是简单,但是并不意味着要写出简单的接口也是一件简单的事情,恰恰相反,把代码写复杂是一件很简单的事,但是把代码写简单却是一件非常困难的事。
这里的简单指的是,更好的封装,这样别人使用你提供的类/接口的时候,更容易使用。
这一点可以通过一个更具体的例子来说明,就是我们的类(OOP 里的类)。
有很多人在定义一个类的时候,好像习惯性地把所有的属性、方法都设置为 public,这样写可能只有自己去使用自己开发的类的时候,问题不是很大。但是如果将这样的类提供给其他开发者使用的时候,别人很大可能没有办法在短时间内知道这个类该如何使用,因为当他们想去使用这个类的时候,发现一堆的 public 方法,根本搞不懂哪一个才能满足自己的需求。
而且,都设置为 public,当你需要去改动这一个类的时候,往往不知所措,因为有可能开发的时候,开发者并不是打算将那个方法提供给外部使用的,但是后面发现很多地方却用了。这样就会给后续维护带来很大的困难,尤其是某些弱类型语言。就算在其他地方调用了,你也可能发现不了。
更好的方法也许是,只将类中需要对外提供的方法设置为 public 就可以了,这样使用者也就只需要在少数几个方法中选出适合的那一个方法即可。不过将不该公开的东西设置为 private 算是 OOD 的基础要求了吧。
分层
一些常见的不那么好的做法是:
- controller 里面做了数据库查询、业务逻辑处理
- service 里面做了数据库查询
- 除了 controller 就是 service,一个 service 做完所有的事情
窃以为,一个更好的做法也许是,controller 跟 service 分开,service 跟 db 分开等,如果尝试这么去做的话,我们会发现,有一些代码变得可以复用了。
事实就是这样,如果我们将我们一些大的类拆分成一个个功能单一的小的类或者方法之后,我们就会发现原来完全不能复用的代码,在很多地方都可以复用,而不再需要将一些重复的逻辑写在 repo 的各个地方了。
分层的例子
- 协议栈:最常见的分层模型就是网络协议栈了,分了应用层、传输层、网络层、链路层。每一层负责不同的功能,底层模块在使用更低层模块提供的服务的同时,向上层提供新的功能。同时上层不需要关心下层的实现细节,可以专注于本层功能的实现。这样带来的好处是,我们今天网络通信中用的网络协议栈依然是几十年前设计出来的,非常的稳定。
- web 应用:mvc 分层,但是窃以为如果在我们日常开发中,将对 db 的访问也拆分出去也许会更好,当然业内也有很多人尝试过了,就是 repository 模式。通过这种模式,我们在做单元测试的时候,也会更加方便,因为可以直接 mock 掉 db 的访问。只需要专注于业务逻辑处理。(因为 db 是非常稳定的,基本不会发生变化,我们在单元测试也要把其考虑进去的话,这会让我们变得不堪重负。)
- MySQL:MySQL 中主要分了 Server 层和 engine 层,Server 层处理的是数据库的一些通用的逻辑,存储引擎层处理的是不同的数据存储方式,比如,MyISAM 跟 InnoDB 的存取数据的过程是不一样的,但是取出数据后如果要做一些运算,做判断等这些就一样了。
外部依赖
我们也许有时候会用到一些自己完全不了解的外部模块,而且有可能我们还很频繁地去使用,这种情况下,一旦依赖的这个外部的方法发生了改变,我们就要改动很多不同的地方。
对于这种情况,有一种方法是将这些外部的依赖都放到一个地方,这样即使外部的依赖发生了一些变更,我们只需要在一个地方修改即可。
关于这种做法,有一个更专业的名词叫做 “防腐层”。这种做法背后的逻辑其实也是很常见的一种软件设计方式,就是关注点分离,我们可以将变与不变的分离开,将不可控的部分控制在一个小范围内。
相互依赖
这里说的依赖大概是下图这种:
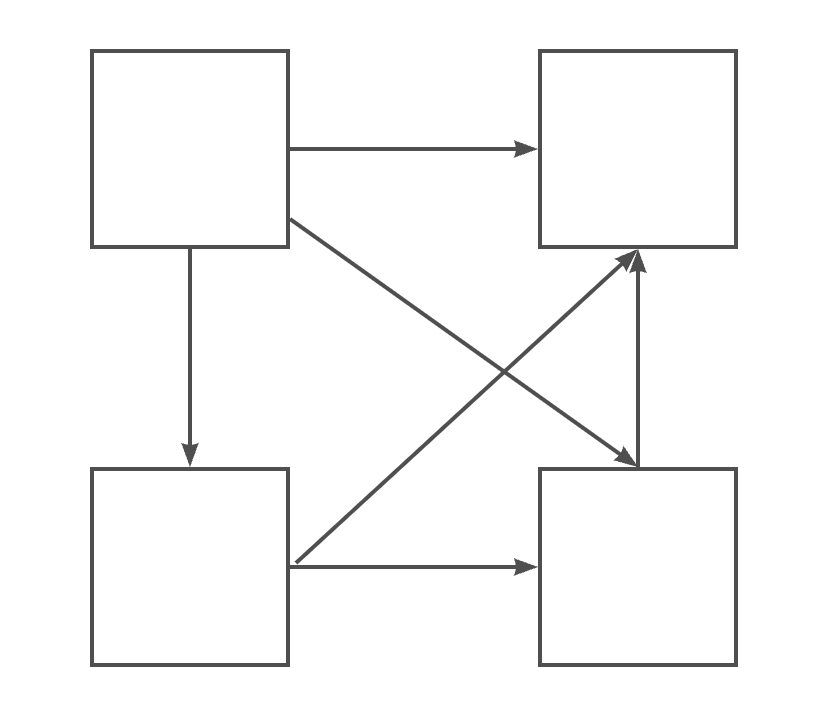
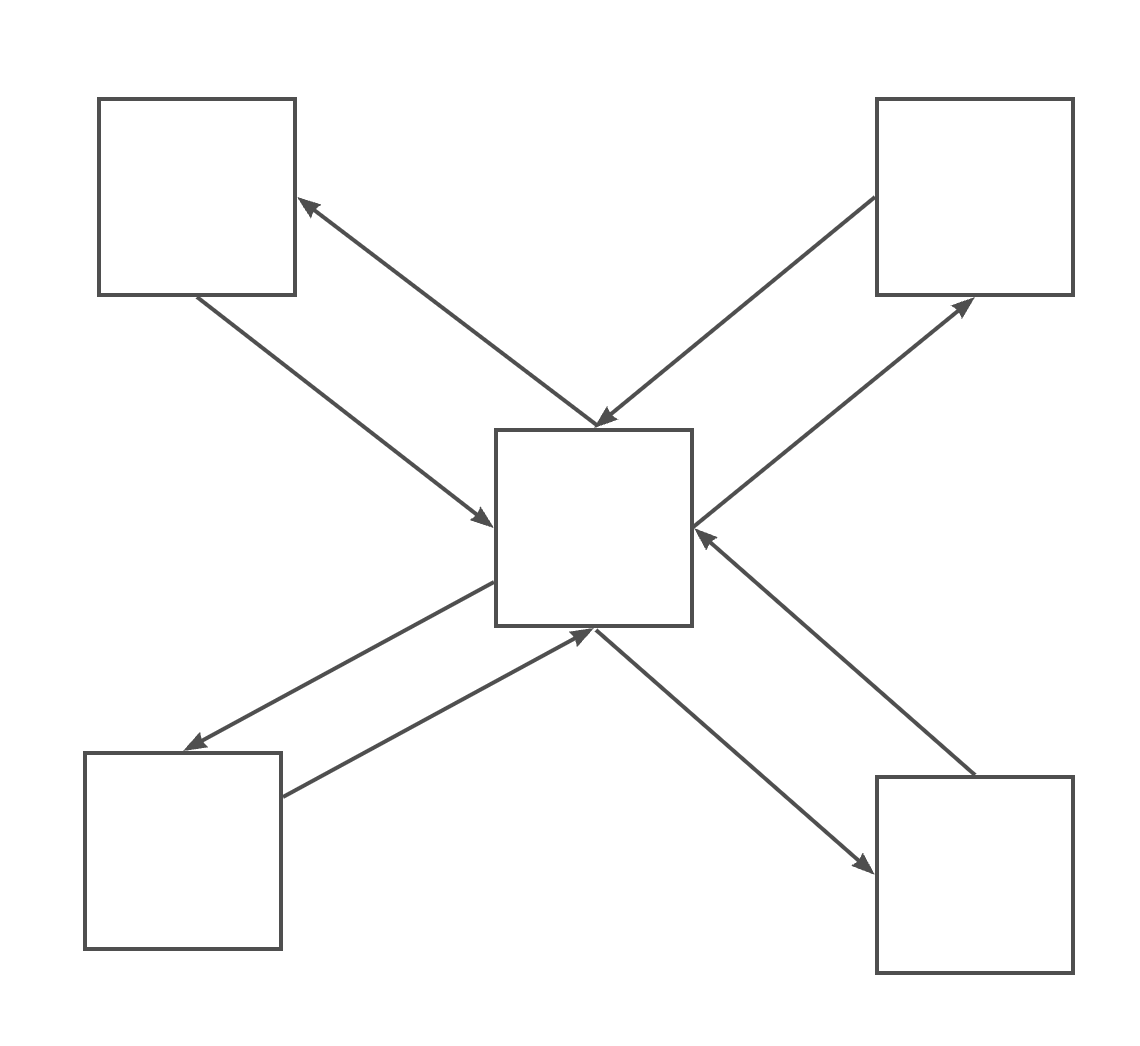
这个图中,不同模块相互依赖,有着复杂的依赖关系。对于这种情况,我们可能可以考虑将各模块都需要的东西抽取出来,新建一个类或者其他什么的,通过这个类来作为不同模块之间的沟通的桥梁,如下图这样:
CI - 持续集成
我们最常用的 gitlab、github 都提供了 ci 的功能,我们可以利用 ci 来帮助我们做很多工作:
- lint:代码规范检查修正、代码格式化等。
- 单元测试:让 ci 来完成单元测试的工作,可以让我们及时发现代码中存在的问题,及时得到反馈。同时通过提高测试覆盖率,我们可以很好地提升我们交付的软件的可靠性。而不是等到测试人员测试这一个环节再去发现问题。
- 也可以做一些集成测试、系统测试等。
错误处理
在软件开发过程中,不可避免地会有错误的产生,不管是哪里产生的,总会有错误,如果我们在错误产生的时候,完全不知道错误是从哪一行代码产生的话,会给我们修复错误的过程带来极大的困难。
对于错误处理,个人觉得有以下几点可以做好的地方: 1. 错误定义:在类似 Java、PHP 这种语言中可以通过异常来定义一些可预期的异常,然后直接在外部捕获这些异常进行处理。 2. 错误处理:捕获到异常之后,我们可能需要通过日志来记录、然后再记录一下上下文信息,只是记录错误可能很多人都能做到,但是异常抛出的上下文对我们排查错误更有帮助。 3. 错误堆栈:这个其实也算是必需的一项了,但是有些人可能会习惯性地 catch 异常之后,只记录一下错误信息就完事了,直接不管异常堆栈,这样也是会给排查错误带来很大的困难。
重构
软件这一词本身就透露出了,它是可以修改的,而硬件不一样,想修改是不大可能的,一般都是直接换掉。
在我们开发完之后,我们依然有机会来对软件的结构等做一些调整,让其性能更好、可维护性更好等。
当然重构的前提是要保证功能不受影响,如果因为我们的重构导致程序崩溃了,或者行为不一致了,那就不叫重构了,那叫搞破坏了。
要如何保证重构之后的代码依然可以维持以前的行为呢?那就是单元测试了。这个可能让很多人会觉得有点失望,因为可能我们的代码一行测试代码也没有,因为测试也是一件比较困难的事情。
但是有时候是不得不做这件事,因为原有代码可能可读性非常差、逻辑非常混乱,仿佛你从代码中就能想象到开发者在写代码时候的那种痛苦的状态。在这种情况下,我们只有通过重构来让旧的代码变得更加易读,让其变得像是可以被修改的代码,而不是那种永远不要动的代码。不管怎样,这是我们很多人必须要面对的事实。
关于重构的,没有什么别的建议,可以看看《重构》这本书。
日志级别
其实,在我能了解的编程语言里面,都有日志库,而且都会定义不同的日志级别,但是可能我们往往就是只用到其中一个日志级别,这对于开发者来说可能并不是一件好事。
也许我们可以考虑使用一下不同的日志级别,然后在不同的情况下启用不同的日志级别,一来可以减少生产环境无效日志的数量,另外也可以针对不同情况设置不同的日志级别。
比如,我们本地就直接 debug 级别,生产就 warn 级别。
后记
好了,目前能想到的就这些了,总结下来比较重要的就三点:
- 关于设计其实大多都能跟 SOLID 沾点边
- 单元测试,但实际上要写好测试,就要先设计好代码,设计不好的代码是非常难写测试的。
- ci,可以通过 ci 脚本可以做一些 lint、format、test 等工作
当然,说起来简单,做起来很难。但正是在这些一次次艰难的关于如何开发高质量软件的思考与实践中,才能慢慢体会到什么情况该如何去做,才能及时发现很多不好的设计。