我所知道的 redux
本文主要讲一下个人最近在看 redux 过程中的一点体会和总结。
redux 中的核心元素
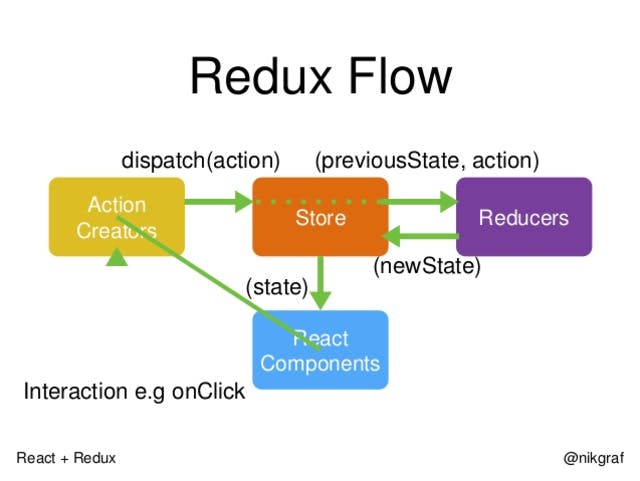
网上找的一张图,里面的内容就是本文要说的内容了。一句话说完就是:
React 组件会通过 Action 来告诉 Store 需要更新哪些状态,Store 通过调用 Reducer 来获取一个新的状态,应用最终的状态就是 reducer 返回的这个新的状态。
关于 state
在 Web 应用中,常常需要保存一些全局的状态,用来做一些 UI 上或者其他方面的控制。比如是否登录,如果已经登录,则显示用户信息,如果没有登录则显示一个登录的按钮让用户点击进行登录操作。
这些状态往往存在于应用的整个生命周期中,并且在不同的组件中可能需要公用这些状态。
现在的一些前端框架都提供了一些状态管理的组件,比如 redux 和 vuex 等,我们可以通过这些组件来方便地对应用的状态进行管理。
三个主要概念
store
store 顾名思义就是存储的对象,在 redux 中,我们会将一些需要共享的状态存储到这个对象中,而这个 store 对象在我们的应用中应该只有一个。既然 store 是一个对象,自然也有一些可以调用的方法,比如:
getState()获取当前的 state(也就是当前 store 保存的状态)dispatch(action)更新 statesubscribe(listener)注册 state 变动的监听器,返回值是注销监听器的函数
简单来说,store 的主要作用是:
- 存储 state
- state 变动的时候可以执行用户注册的回调(比如,重新渲染某一个组件)
action
在 redux 这类状态管理组件中,推荐修改 state 的方法都是通过 store 对象的 dispatch 方法来进行状态的更新,dispatch 接受的参数就叫 action,每一个 action 代表了我们想对 store 执行哪种状态的变更。都通过 dispatch 来更新状态有什么好处呢?
- 状态的变动都通过统一的接口,方便开发者调试(我们可以通过 subscribe 方法来监听到所有的 state 变动)
- 个人觉得简洁的 API 可以降低开发者的心智负担吧
reducer
上面提到了 action,说到了 dispatch 的参数是一个 action,但实际我们是如何更新 store 里面的 state 的呢?答案是通过 reducer,reducer 就是一个函数,这个函数接收当前的 state 和需要执行的 action 作为参数,返回一个新的 state(一定要返回)。
这个命名是不是有点熟悉,我们知道 js 里面数组有个 reduce 函数:
1 | const arr = [1, 2, 3, 4, 5] |
这里的 reduce 第一个函数参数的作用就是接收上一次执行的结果和数组当前下标指向的值作为参数,返回一个新的数作为此次遍历的结果,如此直到遍历完整个数组。等同于以下代码:
1 | let res = 0 |
对比一下这个 Array.redux, redux 里面的 reducer 就很好理解了,reducer 的作用就是接收上一次执行 reducer 返回的结果和当前要操作的 action 作为参数,我们会在前一个 state 的基础上执行指定的 action。比如:
1 | const reducer = (state = 0, action) => { |
这个 reducer 会依据 action 里面指定的 type 来对 store 里面的状态进行一些更新操作,然后返回一个新的 state。
store 初始化过程
做个小实验,在上述 reducer 的第一行写一个
console.log,然后我们可以发现在项目启动的时候控制台输出了我们
console.log 的东西,但实际上我们并没有调用任何的
store.dispatch 方法。
这说明一个问题是,store 里面保存的初始 state 也是通过执行 reducer
来获取的,所以我们的 recuer 里面都需要包含一个 default
分支,一方面是初始化使用,另一个原因下面会说到。
我们也可以通过 console.log 来看看 store 初始化的时候
action 是什么样的:
1 | {type: "@@redux/INITk.3.4.k.v"} |
这个一般用不上,知道有这么一个初始化的过程就好。
修改 state 的过程
上面说到了,我们修改 store 里面的 state 都是需要通过
store.dispatch 这个 API
来进行状态的更新的。这里简单说一下这个修改生效的过程:
- 拿到全局共享的 store 对象之后,假设我们的 action 是
{type: 'INCREMENT'},我们需要通过store.dispatch({ type: 'INCREMENT' })来执行一次INCREMENT操作 - store 对象拿到了这个 action(
{ type: 'INCREMENt' }) 之后,将旧的 state 和这个 action 值传递给初始化 store 时接收的 reducer 参数 - reducer 执行,依据 action 里面 type 的不同值来执行不同的操作,最后返回一个新的 state
- store 拿到 reducer 返回的新的 state,更新当前 store 的
state(实现上是
currentState = currentReducer(currentState, action)) - 执行所有监听器,结束。
也就是说,监听器的执行是在状态更新之后才执行的。我们在 listener
里面如果通过 store.getState() 获取 state 的话将会是最新的
state。
redux 里 combineReducers 的作用
这里做一个简单的假设,假设我们的应用中有两个状态需要维护,一个是姓名 name,一个是年龄 age。如果我们使用一个 reducer 来完成对这两个状态的维护的话,代码将是下面这样的:
1 | const initialState = { name: '', age: 0 } |
我们可以发现,在这个 reducer 里面维护了两个不同的状态的变更操作,在状态比较少的时候,这样写没有什么问题,一旦应用中需要共享的状态越来越多的时候,这个 reducer 也会越来越长,当我们需要对其中某一个状态的更新操作进行修改的时候就比较麻烦了。
redux 里面的 combineReducers
允许我们将不同状态的更新操作拆分到不同的 reducer
里面,这样一来在我们对某一个状态执行变更操作的代码需要修改时候,就可以很方便地找到具体的那一个
reducer 来进行修改。
将上面的两个状态拆分之后,代码如下:
1 | const name = (state = '', action) => { |
在这种写法中, 我们对 name 和 age
两个状态的维护拆分到了两个 reducer 里面,然后我们再使用
combineReducers 来将它们合并,然后传递给
createStore 创建一个 store 对象。
在这种情况下,我们调用 store.getState()
可以得到如下对象:
1 | { |
得出这个结果的过程是,combineReducers 会将 reducer
里面每一个 key 对应的值拿出来(也就是针对那个状态的
reducer),这个函数会返回一个新的函数,在这个新的函数中,会遍历所有的
reducer,执行所有的 reducer。然后将每一个 reducer
返回的结果合并到一个对象里面(也就是最终的
state)。具体实现可以看实现的源码
redux/src/combineReducers.js。下面是源代码里面的注释:
Turns an object whose values are different reducer functions, into a single reducer function. It will call every child reducer, and gather their results into a single state object, whose keys correspond to the keys of the passed reducer functions.
也就是说,虽然我们代码上是拆分成了不同的 reducer,但实际 store 在执行 reducer 的时候还是会将全部的 reducer 执行一遍。所以我们需要在 reducer 里面添加一个 default 分支返回 state。
这里有个需要非常注意的点是:store.dispatch 的时候都会触发所有 reducer 的执行。具体哪一个会修改到 store 的 state 完全是开发者自己控制的。
拆分的优势很明显,可以针对不同的状态来进行独立地维护。劣势就是,需要维护比较多的 reducer,但总的来说长期发展的时候还是建议拆分成不同的 reducer 来进行维护。
总结
- redux 通过 createStore 函数来创建 store 对象,一般只创建一个 store 对象,这个 store 对象保存了应用的状态。createStore 函数接收一个 reducer 函数作为参数
- reducer 函数接收上一个 state 和 action 作为参数,返回一个新的 state
- 修改 state 的唯一方式是
store.dispatch(action) - combineReducers 的作用是合并多个 reducer,这些被合并的 reducer 维护某一个单一的状态,实现在不同的 reducer 里面维护不同状态的更新逻辑