Elasticsearch 更新现有文档
出于不同的原因,可能需要修改现有的一篇文档。假设需要修改一个聚会分组的组织者。可以索引一篇不同的文档到相同的地方(索引、类型和 ID), 但是,如你所想,也可以通过发送给 Elasticsearch 所要做的修改,来更新文档。 Elasticsearch 的更新 API 允许你发送文档所需要做的修改,而且 API 会返回一个答复,告知操作是否成功。
比如,现在需要更新分组 2,设置 organizer 为 Roy,文档的更新包括检索文档、处理文档、并重新索引文档,直至先前的文档被覆盖:
检索现有文档。为了使这步奏效,必须打开 _source 字段,否则 Elasticsearch 并不知道原有文档的内容。
进行指定的修改。例如,如果文档是
{"name": "Elasticsearch Denver", "organizer": "Lee"},而你希望修改组织者,修改后 的文档应该是{"name": "Elasticsearch Denver", "organizer": "Roy"}删除旧的文档,在其原有位置索引新的文档(包含修改的内容)。
使用更新 API 更新文档
首先看看如何更新文档。更新 API 提供了以下几个方法。
通过发送部分文档,增加或替换现有文档的一部分。这一点非常直观:发送一个或多个字段的值,当更新完成后,你期望在文档中看到新的内容。
如果文档之前不存在,当发送部分文档或脚本时,请确认文档是否被创建。如果文档之前不存在,可以指定被索引的文档的原始内容。
发送脚本来更新文档。例如,在线商店中,你可能希望以一定的幅度增加 T 恤的库存量,而不是将其固定死。
- 发送部分文档
发送部分的文档内容,包含所需要设置的字段值,是更新一个或多个字段最容易的方法。为了实现这个操作,需要将这些信息通过 HTTP POST 请求 发送到该文档 URL 的 _update 端点。
1 | curl -XPUT 'localhost:9200/get-together/group/2/_update' -d '{ |
这条命令设置了在 doc 下指定的字段,将其值设置为你所提供的值。它并不考虑这些字段之前的值,也不考虑这些字段之前是否存在。 如果之前整个文档是不存在的,那么更新操作会失败,并提示文档缺失。
在更新的时候,需要牢记可能存在冲突。例如,如果将分组的组织者修改为 "Roy",另一位同事将其修改为 "Radu", 那么其中一次更新会被另一次所覆盖。为了控制这种局面,可以使用版本功能。
- 使用 upsert 来创建尚不存在的文档
为了处理更新文档时文档并不存在的情况,可以使用 upsert。你可能对于这个来自关系型数据库的单词很熟悉,它是 update 和 insert 两个单词的混成词。
如果被更新的文档不存在,可以在 JSON 的 upsert 部分中添加一个初始文档用于索引。命令看上去是这样的:
1 | curl -XPUT 'localhost:9200/get-together/group/2/_update' -d '{ |
- 通过脚本来更新文档
最后,来看看如何使用现有文档的值来更新某篇文档。假设你有一家在线商店,索引了一些商品,你想将某个商品的价格增加 10。 为了实现这个目标,可使用同样的 API,但是不再提供一篇文档,而是一个脚本。脚本通常是一段代码,包含于发送给 Elasticsearch 的 JSON 中。不过,脚本也可以是外部的。
默认的脚本语言是 Groovy。它的语法和 Java 相似,但是作为脚本,其使用更为简单。
由于更新要获得现有文档的 _source 内容,修改并重新索引新的文档,因此脚本会修改 _source 中的字段。使用 ctx._source 来索引 _source, 使用 ctx._source[字段名] 来引用某个指定的字段。
如果需要变量,我们推荐在 params 下作为参数单独定义,和脚本本身区分开来。 这是因为脚本需要编译,一旦编译完成,就会被缓存。如果使用不同的参数,多次运行同样的脚本,脚本只需要编译一次。 之后的运行都会从缓存中获取现有脚本。相比每次不同的脚本,这样运行会更快,因为不同的脚本每次都需要编译。
由于安全因素,通过 API 运行下面的代码可能默认被禁止,这取决于所运行的 Elasticsearch 版本。这称为动态脚本,在 elasticsearch.yml 中 将 script.disable_dynamic 设置为 false,就可以打开这个功能。替代的方法是,在每个节点的文件系统或是 .scripts 索引中存储脚本。
使用脚本进行更新:
1 | curl -XPUT 'localhost:9200/online-shop/shirts/1' -d '{ |
可以看到,这里使用的是 ctx._source.price 而不是 ctx._source['price'] 。这是指向 price 字段的另一个方法。在 curl 中使用 这种方法更容易一些,原因是在 shell 脚本中的单引号转义可能会令人困惑。
通过版本来实现并发控制
如果同一时刻多次更新都在执行,你将面临并发问题。Elasticsearch 支持并发控制,为每篇文档设置了一个版本号。最初被索引的文档版本是 1. 当更新操作重新索引它的时候,版本号就设置为 2 了。如果与此同时另一个更新将版本设置为 2,那么就会产生冲突,目前的更新也会失败。 可以重试这个更新操作,如果不再有冲突,那么版本就会被设置为 3。
为了理解这是如何运作的,我们可以看下图:
索引文档然后更新它(更新1)
更新 1 在后台启动,有一定时间的等待(睡眠)
在睡眠期间,发出另一个 update 的命令(更新 2)来修改文档。变化发送在更新 1 获取原有文档之后、重新索引回去之前
由于文档的版本已经变为 2,更新 1 就会失败,而不会取消更新 2 所做的修改。这个时候你有机会重试更新 1,然后进行版本为 3 的修改
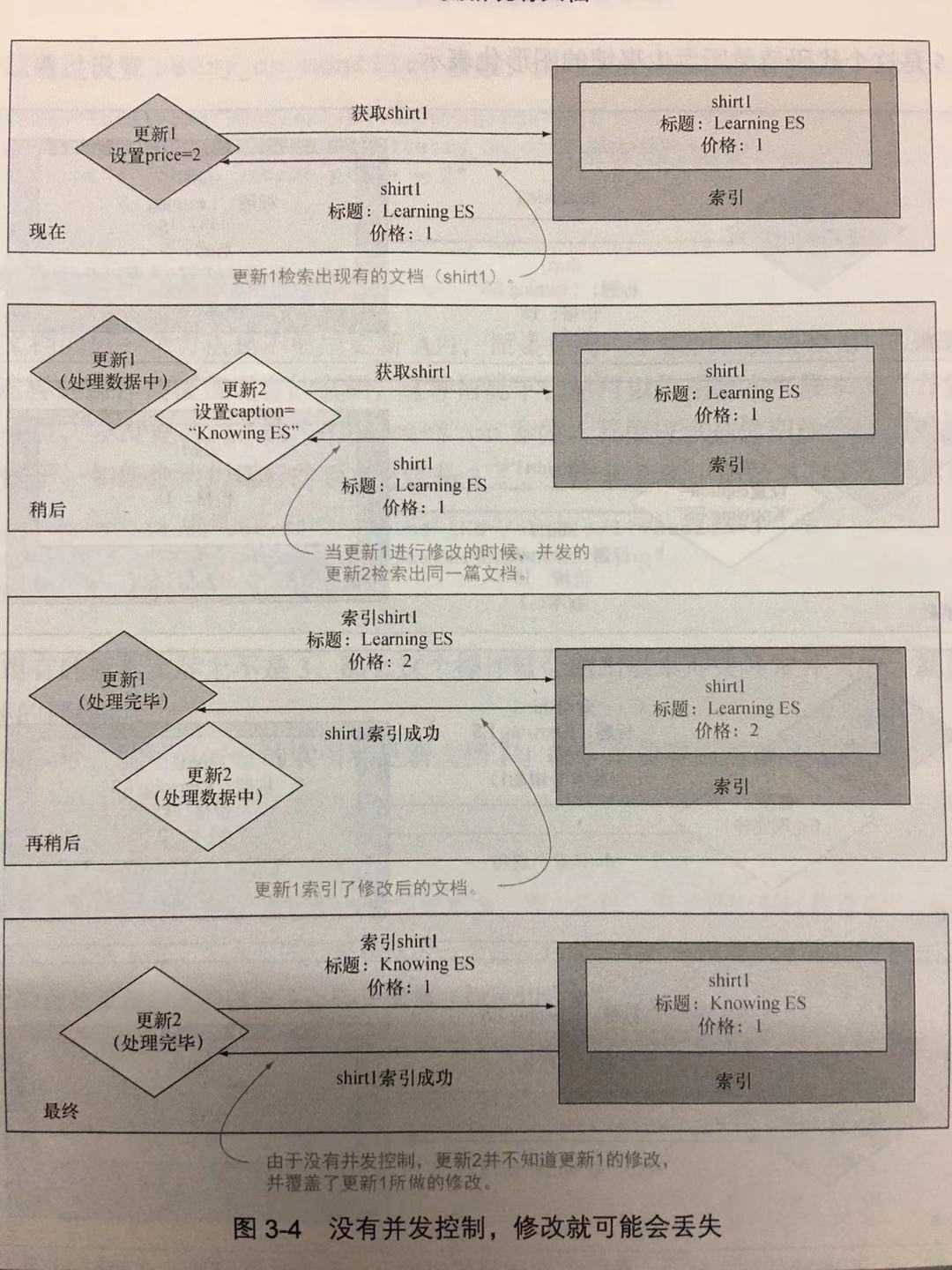
通过版本来管理两个并发更新:其中一个失败了
1 | # 更新 1 等待 10 秒,在后台运行 |
这种并发控制称为乐观锁,因为它允许并行的操作并假设冲突使很少出现的,真的出现时就抛出错误。它和悲观锁是相对的, 悲观锁通过锁住可能引起冲突的操作,第一时间预防冲突。
- 冲突发生时自动重试更新操作
当版本冲突出现的时候,你可以在自己的应用程序中处理。如果是更新操作,可以再次尝试。
但是也可以通过设置 retry_on_conflict 参数,让 Elasticsearch 自动重试。
1 | SHIRTS='localhost:9200/online-shop/shirts' |
- 索引文档的时候使用版本号
更新文档的另一个方式是不使用更新 API,而是在同一个索引、类型和 ID 之处索引一个新的文档。这样的操作会覆盖现有的文档,这种情况下 仍然可以使用版本字段来进行并发控制。为了实现这一点,要设置 HTTP 请求中的 version 参数。其值应该是你期望该文档要拥有的版本号。 举个例子,如果你认为现有的版本已经是 3 了,一个重新索引的请求看上去是这样:
1 | curl -XPUT 'localhost:9200/online-shop/shirts/1?version=3' -d '{ |
如果现有的版本实际上不是 3,那么这个操作就会抛出版本冲突异常并失败。
有了版本号,就可以安全的索引和更新文档了。
使用外部版本
目前为止都是使用的 Elasticsearch 的内部版本,每次操作,无论是索引还是更新,Elasticsearch 都会自动地增加版本号。如果你的数据源 是另一个数据存储,也许在那里有版本控制系统。例如,一种基于时间戳的系统。这种情况下,除了文档,你可能还想同步版本。
为了使用外部版本,需要为每次请求添加 "version_type=external",以及版本号:
1 | DOC_URL='localhost:9200/online-shop/shirts/1' |
这将使得 Elasticsearch 接受任何版本号,只要比现有的版本号高,而且 Elasticsearch 也不会自己增加版本号。