Elasticsearch 索引、更新和删除数据
本文主要内容
使用映射类型来定义同一个索引中的多种文档类型
可以在映射中使用的不同字段类型
使用预定义的字段及其选项
本文内容是关于如何在 ElasticSearch 中存入和获取数据,并且维护这些数据:索引、更新和删除文档。 我们知道,ElasticSearch 是基于文档的,而文档是由字段和其值组成的,这些使得文档是自我完备的,就好像一张数据表中有行和列一样。 在第 2 章中,你看到可以通过 Elasticsearch 的 REST API 来索引一篇文档。这里,我们将观察文档中的字段以及它们所包含的内容, 来深入理解索引过程的细节。例如,当索引一篇这样的文档时:
1 | {"name": "Elasticsearch Denver"} |
由于 Elasticsearch Denver 是一个字符串,所以 name 字段是字符串类型。其他的字段可能是数值型、布尔型等。本文将介绍以下 3 种类型的字段。
核心 - 这些字段包括字符串和数值型
数组和多元字段 - 这些字段在某个字段中存储相同核心类型的多个值。例如,tags 字段可以拥有多个标签
预定义 - 这些字段包括 _ttl(time to live) 和 _timestamp。
可以认为这些字段是元数据,Elasticsearch 会自动地管理它们,提供更多额外地功能。 举例来说,可以配置 Elasticsearch,让其自动地将新数据加入文档集合(如时间戳),或者可以使用 _ttl 字段让过期的文档自动删除。
我们已经知道了文档中可以有的字段类型,以及如何索引这些字段,现在我们将看看如何更新已经存在的文档。鉴于存储数据的方式,当 Elasticsearch 更新现存文档的时候,它会检索出这篇文档,然后按照需求进行修改。然后 Elasticsearch 再次索引更改后的文档,并删除 相应的旧文档。这些更新操作会引起并发问题,你将看到如何通过文档版本自动地解决这些问题。 你将看到删除文档地不同方法,某些方法比其他的运行速度更快。Elasticsearch 索引使用的主要程序库是 Apache Lucene, Lucene 在磁盘上存储数据的特殊方法又导致了这些差异。
使用映射来定义各种文档
每篇文档属于一种类型,而每种类型属于一个索引。从数据的逻辑划分来看,可以认为索引是数据库,而类型是数据库中的表。 例如,第 2 章介绍了聚会网站的分组和活动使用了不同的类型,因为它们拥有不同的数据结构。注意一下,如果这个站点也有博客, 可能要将博客帖子和评论保存在分开的索引中,因为它们是完全不同的数据集。
类型包含了映射中每个字段的定义。映射包括了该类型的文档中可能出现的所有字段,并告诉 Elasticsearch 如何索引一篇文档的多个字段。 例如,如果一个字段包含日期,可以定义哪种日期格式是可以接受的。
- 类型只提供逻辑上的分离
在 Elasticsearch 中,不同类型的文档没有物理上的分离。在同一个 Elasticsearch 索引中的所有文档,无论何种类型, 都是存储在属于相同分片的同一组文件中。一份分片就是一个 Lucene 的索引,类型的名称是 Lucene 索引中一个字段,所有 映射的所有字段都是 Lucene 索引中的字段。
索引的概念是针对 Elasticsearch 的一层抽象,但不属于 Lucene。这使得你可以轻松地在同一个索引中拥有不同类型的文档。 Elasticsearch 负责分离这些文档,例如,在某个类型中搜索时,Elasticsearch 会过滤出属于那个类型的文档。
这种方法产生了一个问题:当多个类型中出现同样的字段名称时,两个同名的字段应该有同样的设置。 否则,Elasticsearch 将很难辨别你所指的是两个字段中的哪一个。最后,两个字段都是属于同一个 Lucene 索引。 例如,如果在分组和活动文档中都有一个 name 字段,两个都应该是字符串类型,不能一个是字符串而另一个是整数类型。 在实际使用中,这种问题很少见,但是还是需要记住这一点,防止意外发生。
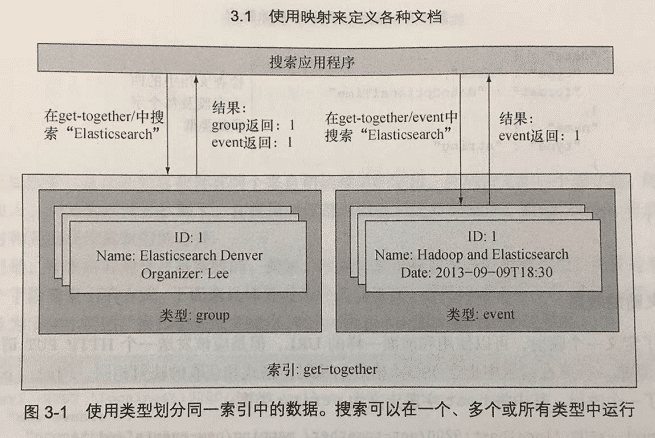
在上图中,group 和 event 存储在不同的类型中。然后应用程序可以在特定的类型中搜索,如 event 类型。 Elasticsearch 也允许每次在多种类型中搜索,甚至是在搜索时仅仅指定索引的名称,这样就可以在某个索引的所有类型中搜索。
上图中,当我们在 get-together 这个索引中搜索的时候,返回的结果同时有 group 和 event 类型。 当我们在 get-together 这个索引的 event 分组中搜索的时候,返回的结果只包含了 event 分组的结果。
检索和定义映射
当学习 Elasticsearch 的时候,通常不用担心映射,因为 Elasticsearch 会自动识别字段,并相应地调整映射。 在一个生产应用中,你常常想预先定义自己地映射,这样就没有必要依赖于自动的字段识别。
获取目前的映射
为了查看某个字段类型当前的映射,向该类型 URL 的 _mapping 接口发送一个 HTTP GET 请求:
1 | curl 'localhost:9200/get-together/group/_mapping?pretty' |
首先索引一个来自聚会网站的新文档,指定一个名为 new-events 的类型,然后 Elasticsearch 会自动地创建映射。 接着,检索创建的映射,结果展示了文档的字段,以及 Elasticsearch 为每个字段所识别的字段类型。
创建文档,索引一篇新的文档
1 | curl -XPUT 'localhost:9200/get-together/new-events/1' -d '{ |
输出:
1 | { |
获取当前映射
1 | curl 'localhost:9200/get-together/_mapping?pretty' |
输出:
1 | { |
定义新的映射
为了定义一个映射,可以使用和前面一样的 URL,但是应该发送一个 HTTP PUT 请求而不是 GET 请求。 需要在请求中指定 JSON 格式的映射,格式和获取的映射相同。 例如,下面的请求设置了一个映射,其中将 host 字段定义为 string 类型:
1 | curl -XPUT 'localhost:9200/get-together/_mapping' -d '{ |
可以在创建索引之后,向某类型中插入任何文档之前定义一个新的映射。
扩展现有映射
如果在现有的基础上再设置一个映射,Elasticsearch 会将两者进行合并。
1 | { |
这个映射目前含有两个来自初始映射的字段,外加一个新字段。随着新字段的加入,初始的映射被扩展了,在任何时候都可以进行这样的操作。 Elasticsearch 将此称为现有映射和先前提供的映射合并。
但是,并非所有的合并是奏效的。例如,你无法改变现有字段的数据类型,而且通常无法改变一个字段被索引的方式。
试图将现有的字段类型从字符串改变为长整型:
1 | curl -XPUT 'localhost:9200/get-together/_mapping' -d '{ |
报错
MergeMappingException[Merge field with failures]
避免这个错误的唯一方法是重新索引 new-events 里的所有数据,包括如下步骤:
将 new-events 类型里的所有数据移除。移除数据的同时也会移除映射
设置新的映射
再次索引所有的数据
为了理解为什么可能需要重新索引数据,想象一下已经索引了一个活动,host 字段是字符串。 如果现在希望将 host 字段变为 long,Elasticsearch 不得不改变 host 在现有文档中的索引方式。 编辑现存的文档意味着删除和再次索引。
正确的映射,理想情况下只需要增加,而无需修改。
用于定义文档字段的核心类型
Elasticsearch 中一个字段可以是核心类型之一,如字符串或者整型,也可以是一个从核心类型派生的复杂类型,如数组。
还有些其他的类型本章没有涉及。例如,嵌套类型允许在文档中包含其他文档,或 geo_point 类型存储了地球上的经度和纬度位置。
除了文档中定义的字段,如名称和日期,Elasticsearch 还使用一组预定义的字段来丰富文档。 例如,有一个 _all 字段,索引了文档中的所有字段。这对于用户未指定字段的搜索很有帮助, 他们可以在所有字段中搜索,这些预定义的字段有其自己的配置选项。
Elasticsearch 的核心字段类型:
| 核心类型 | 取值示例 |
|---|---|
| 字符串 | "Lee", "Elasticsearch Denver" |
| 数值 | 17, 3.2 |
| 日期 | 2013-03-15T10:02:26.231+1:00 |
| 布尔 | 取值可以是 true 或 false |
字符串类型
字符串是最直接的:如果在索引字符,字段就应该是 string 类型。
解析文本、转变文本、将其分解未基本元素使得搜索更为相关,这个过程叫做分析。先看看基本原理:
1 | curl -XPUT 'localhost:9200/get-together/new-events/1' -d '{ |
当这篇文档索引后,在 name 字符串字段里搜索单词 late。
1 | curl 'localhost:9200/get-together/new-events/_search?pretty' -d '{ |
结果:
1 | { |
Elasticsearch 通过分析连接了字符串 "late" 和 "Late Night with Elasticsearch"。如下图所示, 当索引 "Late Night with Elasticsearch" 时,默认的分析器将所有字符转化为小写,然后将字符串分解为单词。
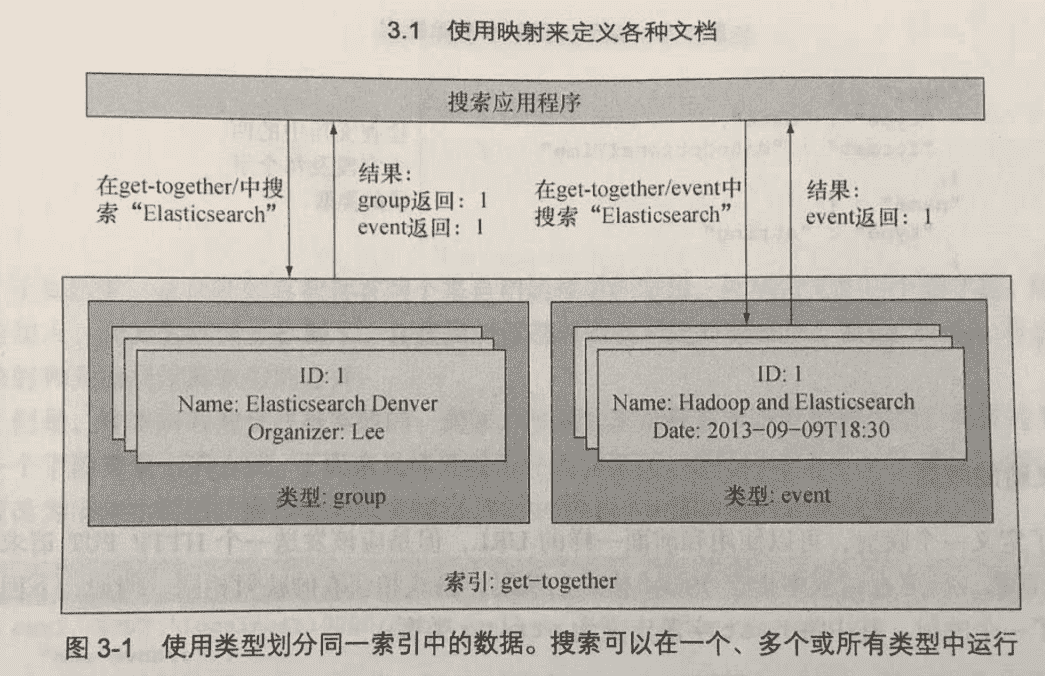
分析过程生成了 4 个词条,即 late、night、with 和 elasticsearch。查询的字符串经过同样的处理过程, 但是这次,"late" 生成了同样的字符串 -- "late"。因为查询生成的 late 词条和文档生成的 late 词条匹配了, 所以文档(doc1)匹配上了搜索。
定义:一个词条是文本中的一个单词,是搜索的基本单位。在不同的情境下,单词可以意味着不同的事务,例如, 它可以是一个名词,也可以是一个 IP 地址。如果只想严格匹配某个字段,应该将整个字段作为一个单词来对待。
另一方面,如果索引 "latenight",默认的分析器只创建了一个词条 -- latenight。 搜索 "late" 不会命中 doc2 文档,因为它并不包含词条 late。
映射会对这种分析过程起到作用。可以在映射中指定许多分析的选项。例如,可以配置分析, 生成原始词条的同义词,这样同义词的查询同样可以匹配。
现在来看看 index 选项,它可以设置为 analyzed(默认)、not_analyzed 或 no。 例如,将 name 字段设置为 not_analyzed,映射可能看上去像这样:
1 | curl -XPUT 'localhost:9200/get-together/_mapping/new-events' -d '{ |
默认情况下,index 被设置为 analyzed,并产生了之前看到的行为:分析器将所有字符转换为小写,并将字符串分解为单词。 当期望每个单词完整匹配时,请使用这种选项。举个例子,如果用户搜索 "elasticsearch",他们希望在结果列表里看到 "Late Night with Elasticsearch"。
将 index 设置为 not_analyzed,将会产生相反的行为:分析过程被略过,整个字符串被当作单独的词条进行索引。 当进行精准的匹配时,请使用这个选项,如搜索标签。 你可能希望 "big data" 出现在搜索 "big data" 的结果中,而不是出现在搜索 "data" 的结果中。 同样,对于多数的词条计数聚集,也需要这个。如果想知道最常出现的标签,可能需要 "big data" 作为一整个词条统计, 而不是 "big" 和 "data" 分开统计。
如果将 index 设置为 no,索引就被略过了也没有词条产生,因此无法在那个字段上进行搜索。 当无须在这个字段上搜索时,这个选项节省了存储空间,也缩短了索引和搜索的时间。 例如,可以存储活动的评论。尽管存储和展示这些评论是很有价值的,但是可能并不需要搜索它们。 在这种情况下,关闭那个字段的索引,使得索引的过程更快,并节省了存储空间。
在搜索未经过分析的字段时,检查你的查询是否被分析过
对于某些查询,如之前使用的 query_string,分析过程是运用于搜索条件的。了解这种情况是否发生是非常重要的,否则可能产生无法预料的结果。
例如,如果索引 "Elasticsearch" 而它又没有被分析过,系统就会生成词条 "Elasticsearch"。 像这样查询 "Elasticsearch" 的时候:
1 | curl 'localhost:9200/get-together/new-events/_search?q=Elasticsearch' |
URI 请求被分析之后,词条 elasticsearch(小写) 就会生成。但是索引中并没有词条 elasticsearch。 你只有 Elasticsearch(首字母 E 大写),于是不会命中结果。
数值类型
数值类型可以是浮点数,也可以是非浮点数。如果不需要小数,可以选择 byte、short、int 或者 long。如果确实需要小数,你的选择是 float 和 double。 这些类型对应于 Java 的原始数据类型,对于它们的选择将会影响索引的大小,以及能够索引的取值范围。 例如 long 需要 64 位,而 short 只需要 16 位。但是 short 只能存储 -32768 到 32767 之间的数字, long 却可以存储其万亿倍的数值。
如果不知道所需要的整型数字的取值范围,或者是浮点数字的精度,让 Elasticsearch 自动检测映射更为安全: 为整数值分配 long,为浮点数值分配 double。索引可能变得更大、变得更慢, 因为这两种类型占据了更多的空间,但是,在索引的过程中 Elasticsearch 不会发生超出范围的错误。
日期类型
date 类型用于存储日期和时间。它是这样运作的:通常提供一个表示日期的字符串,例如 2013-12-25T09:00:00。 然后,Elasticsearch 解析这个字符串,然后将其作为 long 的数值存入 Lucene 的索引。 该 long 型数值是从 1970年1月1日 00:00:00 UTC 到所提供的时间之间已经过去的毫秒数。
当搜索文档的时候,你仍然提供 date 的字符串,在后台 Elasticsearch 将这些字符串解析并按照数值来处理。 这样做的原因是和字符串相比,数值在存储和处理时更快。
另一方面,只需要考虑 Elasticsearch 是否理解你所提供的 date 字符串。 这里 date 字符串的数据格式是通过 format 选项来定义的,Elasticsearch 默认解析 ISO 8601 的时间戳。
ISO 8601
ISO 8601 是一种交流日期和时间相关数据的国际标准,ISO 8601 日期看上去像这样:
1 | 2013-12-12T10:32:00.453-03:00 |
它拥有一个良好时间戳应该具备的要素:信息是从左到右阅读,从最重要的部分到最次要的部分; 年份是 4 位数字;时间包含了亚秒和时区。这种时间戳中的大多数信息是可选的; 例如,无须给出毫秒,还可以省略整个时间部分。
使用 format 选项来指定日期格式的时候,有以下两种选择。
使用预定义的日期格式。例如,date 格式解析 2013-05-23 这样的日期。有很多预定义的格式供选择。
设置自己定制的格式。可以指定时间戳所遵循的模式。例如,指定 MMMYYYY 来解析 Jul 2001 这样的日期。
为了使用所有的日期信息,在映射中添加一个称为 weekly-events 的新映射类型。 然后,如下所示,增加首次活动的名称和日期,然后为这个日期指定 ISO 8601 的时间戳。 同时,添加下次活动的日期字段,并为其设置定制的日期格式。
1 | // 定义定制化的日期格式。其他日期是被自动化地检测,无需显式定义。 |
布尔类型
boolean 类型用于存储文档中的 true/false(真/假)。例如,你可能期望一个字段表明活动的视频是否可以下载。 一个样例的文档可以像这样进行索引:
1 | curl -XPUT 'localhost:9200/get-together/new-events/1' -d '{ |
其中 downloadable 字段被自动地映射为 boolean,在 Lucene 的索引中被存储为代表 true 的 T,或者代表 false 的 F。 就像日期类型,Elasticsearch 解析你在源文档中提供的值,将 true 和 false 分别转化为 T 和 F。
数组和多字段
有的时候,在文档中仅仅包含简单的字段-值配对是不够的。有可能在同一个字段中需要拥有多个值。 如:假设你正在索引博客帖子,为帖子设计了一个标签字段,字段中有一个或者多个标签。
数组
如果要索引拥有多个值的字段,将这些值放入方括号中,例如:
1 | curl -XPUT 'localhost:9200/blog/posts/1' -d '{ |
映射将 tags 字段定义为字符串型,和单个值同样处理。
1 | curl 'localhost:9200/blog/_mapping/posts?pretty' |
所有核心类型都支持数组,无须修改映射,既可以使用单一值,也可以使用数组。 例如,如果下一个博客帖子只有 1 个标签,可以这样索引:
1 | curl -XPUT 'localhost:9200/blog/posts/2' -d '{"tags": "second"}' |
对于 Lucene 内部处理而言,这两者基本是一致的,在同一个字段中索引或多或少的词条,完全取决于你提供了多少个值。
多字段
如果说数组允许你使用同一个设置索引多项数据,那么多字段允许使用不同的设置,对同一项数据索引多次。 举个例子,上面的帖子标签类型使用两种不同的选项来配置 tags 字段: analyzed、针对每个单词进行匹配,以及 not analyzed、针对完整标签名称的精确匹配。
无须重新索引数据,就能将单字段升级到多字段。
字符串类型的多字段:一次是 analyzed、一次是 not_analyzed
1 | curl -XPUT 'localhost:9200/blog/_mapping/posts' -d '{ |
要搜索 analyzed 版本的标签字段,就像搜索其他字符串一样。如果要搜索 not_analyzed 版本的字段(仅仅精确匹配原有的标签), 就要指定完整的路径:tags.verbatim。
多字段和数组字段都允许在单一字段中拥有多个核心类型的值。
使用预定义的字段
Elasticsearch 提供了一些预定义的字段,可以使用并配置它们来增加新的功能。和之前看到的字段相比,这些预定义的字段在 3 个方面有所不同。
通常,不用部署预定义的字段,Elasticsearch 会做这件事情。例如,可以使用 _timestamp 字段来记录文档索引的日期。
它们揭示了字段相关的功能。例如,_ttl 字段使得 Elasticsearch 可以在指定的时间过后删除某些文档。
预定义的字段总是以下划线(_)开头。这些字段为文档添加新的元数据,Elasticsearch 将这些元数据用于不同的特性,从存储原始的文档, 到存储用于自动过期的时间戳信息。
我们将重要的预定义字段分为以下几种类别。
控制如何存储和搜索你的文档。_source 在索引文档的时候,存储原始的 JSON 文档。_all 将所有的字段一起索引。
唯一识别文档。有些特别的字段,包含了文档索引位置的数据:_uid、_id、_type 和 _index
为文档增加新的属性。可以使用 _size 来索引原始 JSON 内容的大小。类似地,可以用 _timestamp 来索引文档索引时间, 并且使用 _ttl 来告知 Elasticsearch 来告知 Elasticsearch 在一定时间后删除文档。
控制文档路由到哪些分片。相关字段是 _routing 和 parent。
控制如何存储和搜索文档
先从 _source 开始,它可以在索引中存储文档。还有 _all,使用它可以在单个字段上索引所有内容。
- 存储原有内容的 _source
_source 字段按照原有格式来存储原有的文档。这一点可以让你看到匹配某个搜索的文档,而不仅仅是它们的 ID。
_source 字段的 enabled 可以设置为 true 或者 false,来指定是否想要存储原始的文档。默认情况下是 true,在许多情况下这是非常棒的, 因为 _source 的存在允许你使用其他重要的 Elasticsearch 特性。例如,使用更新 API 来更新文档的内容需要 _source。 同样,默认的高亮实现需要 _source。
警告:由于许多功能都依赖于 _source,而且从空间和性能的角度来看存储的成本相对低廉。在版本 2.0 中将无法关闭 _source 选项。
为了理解这个字段是如何工作的,来看看当检索某篇之前索引的文档时,Elasticsearch 通常返回什么:
1 | curl 'localhost:9200/get-together/new-events/1?pretty' |
搜索的时候,同样会获得 _source 的 JSON,因为这是默认设置会返回的内容。
- 仅仅返回源文档的某些字段
当检索或者搜索某篇文档的时候,可以要求 Elasticsearch 只返回特定的字段,而不是整个 _source。一种实现的方法是在 fields 参数中提供用逗号分隔的字段列表,例如:
1 | curl -XGET 'localhost:9200/get-together/group/1?pretty&fields=name' |
如果 _source 已经被存储,Elasticsearch 从那里获取所需的字段。也可以通过设置 store 选项为 yes 来存储个别的字段。 举个例子,如果只需存储 name 字段,映射看上去可能是这样:
1 | curl -XPUT 'localhost:9200/get-together/_mapping/events_stored' -d '{ |
向 Elasticsearch 请求特定的字段时,这样做可能会很有帮助,原因是相对于检索整个 _source 然后再抽取而言,检索单一的存储字段要更快一些,尤其是在文档很大的时候。
当存储单独的字段的时候,应该考虑到存储的越多,索引越大。更大的索引经常意味着更慢的索引和搜索速度。
就其内部来看,_source 只是另一个 Lucene 中存储的字段。Elasticsearch 将原始的 JSON 存储于其中,然后按需抽取字段的内容。
- 索引一切的 _all
就好像 _source 是存储所有的信息,_all 是索引所有的信息。当搜索 _all 字段的时候,Elasticsearch 将在不考虑是哪个字段匹配成功的情况下, 返回命中的文档。当用户不知道在哪里查询某些内容的时候,这一点非常有用。例如,搜索 “elasticsearch” 可能匹配上组名 "Elasticsearch Denver", 也有可能是其他分组的 elasticsearch 标签。
从 URI 上运行搜索时如果不指定字段名称,系统默认情况下将会在 _all 上搜索:
1 | curl 'localhost:9200/get-together/group/_search?q=elasticsearch' |
如果总是在特定的字段上搜索,可以通过设置 enabled 为 false 来关闭 _all:
1 | "events": { |
如此设置会使得索引的规模变得更小,而且索引操作会变得更快。
默认情况下,include_in_all 隐含地设置为 true,每个字段都会包含在 _all 之中。可以使用这个选项来控制哪些字段被 _all 包含,而哪些不被 _all 包含。
1 | curl -XPUT 'localhost:9200/get-together/_mapping/custom-all' -d '{ |
使用 include_in_all 地选项,将赋予你更高的灵活性。灵活性不仅提现在空间存储上, 同样体现在查询的表现方式上。如果一次搜索在没有指定字段的情形下运行,Elasticsearch 只会匹配 _all 所包含的字段。
下面的一组预定义字段,包括了这些用于识别文档的字段:_index、_type、_id 和 _uid。
识别文档
为了识别同一个索引中的某篇文档,Elasticsearch 使用 _uid 中的文档类型和 ID 结合体。 _uid 字段是由 _id 和 _type 字段组成,当搜索或者检索文档的时候总是能获得这两项信息:
1 | curl 'localhost:9200/get-together/group/1/fields&pretty' |
现在你可能好奇:“为什么 Elasticsearch 要在两个地方存储同样的数据?已经有了 _id 和 _type,为什么还要 _uid?”
由于所有的文档都位于同一个 Lucene 的索引中,Elasticsearch 内部使用 _uid 来唯一确定文档的身份。类型和 ID 的分离是一种抽象, 通过类型的区分使得针对不同结构的运作更为容易。正是因为如此,_id 通常从 _uid 抽取出来,但是 _type 必须单独索引, 这样当搜索特定类型时,系统才能轻松地根据类型来过滤文档。
_id 和 _type 字段的默认设置
| 字段名称 | 是否存储 | 是否索引 | 观测 |
|---|---|---|---|
| _uid | yes | yes | 用于识别整个索引中的某篇文档 |
| _id | no | no | 该字段没有被索引,也没有被存储。如果搜索它,实际上使用的是 _uid。当你获得了结果,也同样是从 _uid 抽取内容 |
| _type | no | not_analyzed | 该字段是被索引的,并且生成一个单一的词条。Elasticsearch 用它来过滤指定类型的文档。也可以搜索这个字段 |
- 为文档提供 ID
目前为止,多数是通过 URI 的一部分来手动提供 ID。例如,为了索引 ID 为 1st 的文档,运行类似下面的命令:
1 | curl -XPUT 'localhost:9200/get-together/manual_id/1st?pretty' -d '{ |
可以在回复中看到 ID:
1 | { |
或者,也可以依靠 Elasticsearch 来生成唯一的 ID。如果尚无唯一的 ID ,或者没有必要通过某种特定的属性来识别文档,这一点就很有帮助。 通常而言,当索引应用程序的日志时,你会这么做:这些数据没有唯一的属性来识别它们,而且它们也不会被更新。
为了让 Elasticsearch 生成 ID,使用 HTTP Post 请求并省去 ID。
1 | curl -XPOST 'localhost:9200/logs/auto_id/?pretty' -d '{ |
可以在回复中看到自动生成的 ID:
1 | { |
- 在文档中存储索引名称
除了 ID 和类型,为了让 Elasticsearch 在文档中存储索引的名称,请使用 _index 字段。和 _id、_type 一样,可以在搜索或者是 GET 请求的结果中看到 _index, 它也不是来源于字段的内容,默认情况下 _index 是关闭的。
Elasticsearch 知道每个结果来自哪个索引,所以它可以展示 _index 的值,但是默认你自己是无法搜索 _index 的。
为了打开 _index,要将 enabled 设置为 true。映射看上去像下面这样:
1 | curl -XPUT 'localhost:9200/get-together/_mapping/with_index' -d '{ |
如果在这个类型中添加文档,然后重新运行之前的搜索请求,你将会发现新的文档。
正如你已经尝试的,通过索引 URI 来搜索属于特定索引的文档可能很容易,但是在更为复杂的用例中 _index 字段可能体现出其价值。 例如,对于多租户的环境而言,可能为每位用户创建一个索引。在多个索引中进行搜索时,可以使用 _index 字段上的词条聚集来展示 每位用户所拥有的文档数量。