好吧,我承认有点标题党了。写这个其实主要是记录一下近期对于实现协程的一些实践以及遇到的一些问题(em... 还没有实现),这里的近期是指9月21日至今。过去的这段里,一直在尝试着自己实现一个协程,事实证明,有些事的确就是你想象中的那么难(也许比你想象中还要困难,不过恰巧说明它值得去做)。
故事的开始
故事还得从几个星期前说起,那几天心血来潮,想着自己去实现一个协程,然后顺便把这个过程记录下来。按照自己的猜测,协程切换的机制应该是非阻塞 io 加上操作系统提供的让出 cpu 使用权的一个特性(这个时候还不知道具体是什么特性,但是基本可以肯定是这样)。开始实现的时候,刚好看到 swoole 官方文档里面提到 swoole 2.0 实现协程使用的是 setjmp longjmp,

这个时候,自以为实现协程的两大技术难题已经有解决方案了,便开始我的公众号文章的编写,一边写文章一边去写代码,目的就是为了将自己实现的这个过程的一些想法,整个的思考过程记录下来,这样也许别人也可以更好地理解我所写的东西,同时也可以更容易理解协程的实现机制。
setjmp 和 longjmp
在此之前,有必要先说一下 setjmp 和 longjmp 是个什么东西,先看看 linux 官方文档的描述:
The functions described on this page are used for performing "nonlocal gotos": transferring execution from one function to a predetermined location in another function. The setjmp() function dynamically establishes the target to which control will later be transferred, and longjmp() performs the transfer of execution.
setjmp、longjmp 示例代码:
1 |
|
输出:
1 | (A1) |
很直观的效果就是,longjmp 实现在在两个函数之间来回跳转。
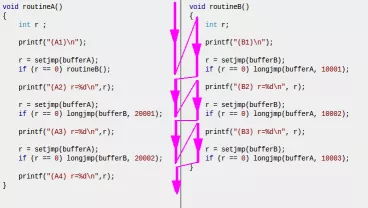
简单来说,就是操作系统提供了这两个函数供开发者实现函数间的 goto 功能,也就是它的功能就是让你可以在一个函数里面可以 goto 到另一个函数内部。这种想法是挺好的,不过 setjmp 和 longjmp 本身的实现有挺多问题,下面会细说。
事实证明,我有点低估了使用 setjmp 和 longjmp 来实现协程的难度,虽然使用 setjmp longjmp 的一些 demo 可以很容易地跑起来,可是当我将这两个函数用于实现自己想法的时候,出现了各种各样的意外情况。比如,不能使用 wrapper 的方式来封装这两个函数,只能直接调用这两个函数才能正常运行,可是这显然不是我们想要的结果,谁也不想为了追求那么一些性能来将代码写得复杂无比。因为相比将代码写复杂,直接换一门高性能的语言来的更靠谱一些。比如换 go 啥的或许会更香。
为了了解为什么自己代码出现了这么多奇奇怪怪的异常,只有去看它们的实现了,正所谓源码之下了无秘密。看了它们的源码发现了一个问题,它们的实现只是保存了 callee-saved 寄存器,以及当前栈指针 bp(base pointer) 和 sp(stack pointer),以及 ip(instruction pointer) 及返回地址。而 ip 和返回地址是由 call 指令隐式写入栈的(这里参考一下下面的函数调用规则)。忘了说了,它们的实现是汇编实现,因为只有汇编才能直接操作寄存器和堆栈。
函数调用规则
这里说的内容是汇编层面的操作,为了使得编译器编译出来的动态连接库等文件里面提供的函数可以相互调用,操作系统有一个叫做 abi(application binary interface)的东西,也就是一个规范,里面定义了一个关键的内容就是,函数调用的时候,怎么保存参数、怎么返回结果,返回之后怎么还原之前的上下文等。
我错了,这东西几句话说不清楚。随便说几句吧,详细可以搜索 calling convention 以及 abi。在函数执行的时候,会有一个栈空间来保存传递给函数的参数,同时函数内的局部变量也会占用栈空间,在一个函数调用另外一个函数的时候(用户态的调用是 call 指令,当然指的是汇编指令,系统调用是 syscall 指令),这里说的是 call 指令,会先将函数调用的下一条指令的地址入栈,然后再跳转到被调用的函数处执行(call 指令隐式修改了 ip)。
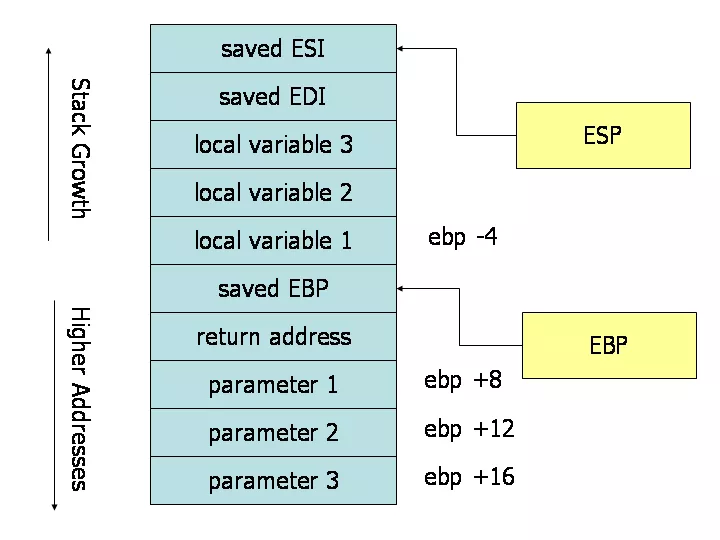
图片来源:https://flint.cs.yale.edu/cs421/papers/x86-asm/asm.html
当然这个链接不只有这个图,它是 x86 汇编一个大概的指南,yale edu 出品。
先说一下这个图(函数栈示意图): 1. 在 x86 汇编里面,栈地址是递减的,也就是说入栈的时候,栈地址需要减去对应的字节数。 2. 调用函数的时候,会在栈里面先保存返回地址 3. 再保存 ebp(e 是寄存器前缀,e 前缀代表的是 32 位寄存器),也就是 base pointer,只不过用了一个 32bit 的寄存器来保存,如果是 80x86 就没有 e 前缀了 4. 为被调用函数的局部变量开辟空间 5. 保存被调用函数的参数
在被调函数里面,有一个操作是:pushq %rbp,这个操作是记录上一个栈的 bp,目的是为了在这个被调用函数执行完毕的时候,恢复之前的 bp。然后将当前的 sp 设置为被调函数的 bp,这个时候一个新的栈出现了,不过这个叫做栈帧,这个栈帧在函数调用的时候产生,函数调用结束的时候销毁(不过这里的销毁并不是什么特别的操作,只是将 sp 移动了),并且在函数结束的时候将之前的 bp 恢复,然后返回到之前的函数调用处。
说完了 bp 和 sp,函数调用还有另外一个关键的地方是,calling convention 里面约定了一部分寄存器是 callee-saved 寄存器,这部分寄存器是被调用者保存的。也需要被调用函数保存。(所以 setjmp 和 longjmp 实现里面包含了这些操作。)
说了这么多,其实关键在于 bp 和 sp,如果我们想通过 wrapper 的方式来调用 setjmp,那在 setjmp 的时候,bp 和 sp 实际上是当前 wrapper 函数的栈帧,然后当我们使用 longjmp 来实现函数间 goto 的时候,就只能恢复到 setjmp wrapper 函数的栈帧,以及那时候的 ip(instruction pointer)。
问题来了,在我们使用 setjmp wrapper 函数的时候,调用完的时候,setjmp 时的栈帧已经销毁了,当我们在后面再去使用 longjmp 来尝试跳转到 setjmp 时候的地方就肯定有问题了。当然 ip 可能可以正常设置,但是 bp 和 sp 肯定是完全不对的。
当然除了这个,setjmp 和 longjmp 还有个问题就是,不会保存浮点数寄存器等。也就是如果使用 setjmp 和 longjmp 我们做浮点运算的相关数据会丢失。
makecontext 登场
在这个时候,stackoverflow 上的一个答案给了我新的方向,上面提到,我们可以使用 makecontext 来实现用户级的上下文切换,这不正是我想要的结果吗。然后这个时候有个念头冒了出来,swoole 该不会也是用这个来实现的吧,上 github 搜了一下 swoole 源码,协程里面的确用到了 makecontext,也就是说 swoole 也是用这个 makecontext 以及相关其他函数实现的了。
至此为止总算有了一个突破性的进展了。到这里也许有的人会说,为什么不直接去看 swoole 的实现,这有点像说,你怎么不去抄答案。毕竟我的目的不是为了实现协程这个功能本身,而是想通过实现它来了解协程整个实现的机制,毕竟作为一项对 php 产生了深远影响的技术,了解它本身可以让我们更好地去使用它,了解它的长处、劣势等,甚至,当我们意识到其局限性的时候,我们也会有对应的解决方案。比如替代方案等。又或者了解它本身,协助我们解决实际使用中遇到的各种问题。
在得知 swoole 的实现是使用了 makecontext 之后,又开始了新一轮的探索,还是依照之前的想法来实现。将之前使用 setjmp 和 longjmp 的地方使用 ucontext 相关的函数来代替。demo 代码写完,开始运行,毫无意外报错了,还是 sigsegv,我直接好家伙,又是这种无法直接从代码找到错误的报错。难怪需要 gdb 这种这么高级的 debugger,有些 bug 实在是无法通过简单的观测就可以得到答案,还必须深入 CPU 和内存内部才能勉强找到一点有用的信息。
这个问题没有办法从代码本身找到答案,因为代码好像没有啥问题(或者说我不知道有什么问题,因为用的 C++ 实现,C++ 本身也带来了一定的复杂度),只有先去看看那几个函数是怎么实现的了。getcontext 和 makecontext 还好,都是一些常规的操作,比如保存通用寄存器、保存浮点数寄存器、保存当前系统信号等。而 swapcontext 着实把我看懵了,又整出什么 shadow stack 这些新概念。使用 shadow stack 的代码看不太懂,不使用 shadow stack 的代码看起来跟 longjmp 有点类似,恢复寄存器,bp 和 sp 等。
先歇一会吧,明天继续
陆陆续续又看了一个星期了,依旧没有找到答案,今晚刚好从老家回来又折腾了一晚上,依旧很多问题,改了几版,都有 bug,还原回国庆前的版本,放这里纪念一下吧:
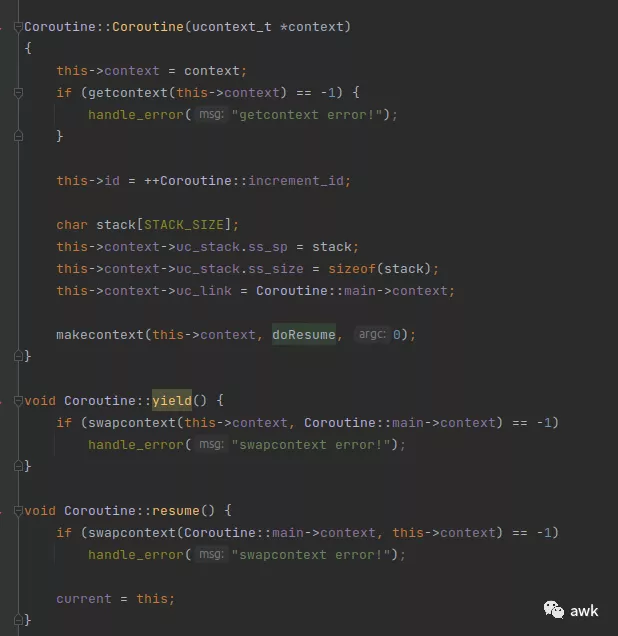
明天起来用 C 来看看能不能实现一个简单的版本,调用麻烦一点也行,先去掉 C++ 本身复杂性的影响。再不行就参考一下答案了,比如 swoole,或者云风10年前的一个实现~
困了困了,放假就应该好好休息,睡了~