基本在所有的编程语言中,都有 map 这种数据结构,Go 语言也不例外。 我们知道 Go 是一门对并发支持得比较好的语言,但是 map 并不支持并发读写。 比如,下面这种写法是错误的:
1 | var m = make(map[int]int) |
这样写会报错:
1 | fatal error: concurrent map writes |
为什么 Go map 不支持并发读写
这跟 map 的实现有关,根本原因是:map 的底层是支持自动扩容的,在添加元素的时候,如果发现容量不够,就会自动扩容。 如果允许扩容和访问操作同时发生,那么访问到的数据就不一定就是我们之前存放进去的了,所以 Go 从设计上就禁止了这种操作。 也就是 fail fast 的原则。
至于具体为什么,我们可以看看 map 在扩容时做了什么操作:
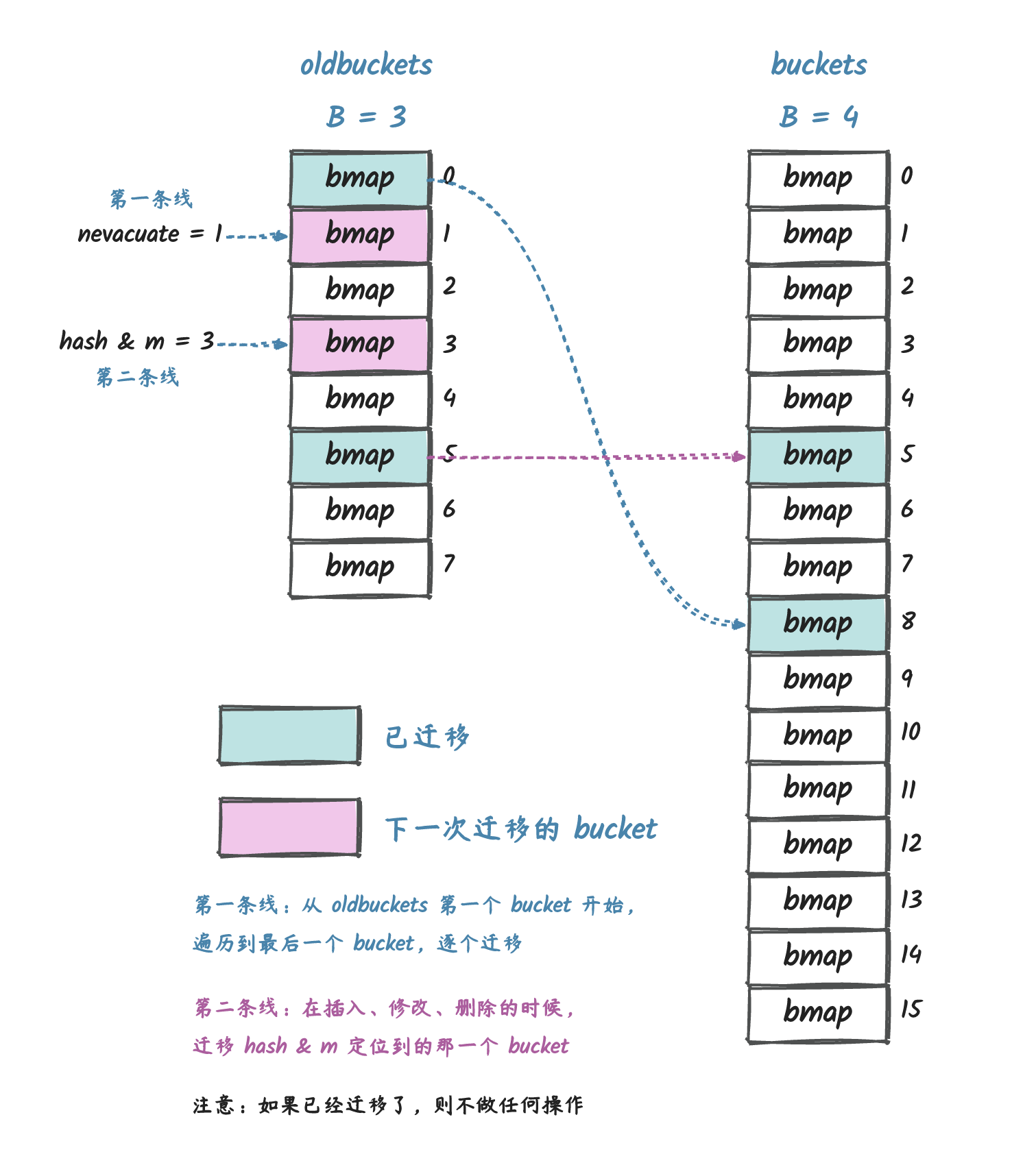
上图来源于我之前写的一篇文章:go map 设计与实现
Go 中 map 的扩容是一个渐进的过程,在我们访问 map 的时候,会对 map 底层实际存储数据的桶进行迁移。
如果支持并发读写,就有可能会导致底层定位到的桶是扩容前的,但是实际上数据已经迁移到了新的桶中,这样就会导致访问到的并不是我们想要的数据。
Go map 设计上的考虑
在 Go 官网的博客上有专门针对 Go 不支持并发读写的说明,大概意思是:
经过长时间讨论,Go 团队认为,多数情况下,我们并不需要从多个 goroutine 来对 map 进行安全访问, map 可能是已经实现了同步的某些较大数据结构或计算的一部分。因此,如果底层再去实现 map 的互斥操作, 就会减慢大多数程序的速度,而只能增加少数程序的安全性。
也就是说,他们认为大多数情况下,
map通常是我们自定义数据结构的一部分,而对这个自定义数据结构的访问时,我们一般已经有了锁去保证并发读写安全了,所以没有必要再在底层的map上加锁,从而可以保证大多数程序的速度。
但是从语言层面上来说,我们依然可以自行通过互斥锁来实现 map 的的互斥访问。 仅当对 map 在进行更新的时候,map 的读才是不安全的,但是 map 是支持并发读的。
如何解决这个问题 - 互斥锁
关于这一点,同样可以在 Go 官方博客中找到相关的说明,在 Go map 并发这一节也给了对应的 demo。具体来说就是将一般锁跟 map 关联起来,要读写 map 的时候,得先获取这个锁才能访问,这样就避免了对 map 的并发读写了。这是最典型的一种解决方案,也是最简单的。
下面的结构体定义了一个匿名结构体 counter,这个结构体中包含了一个 sync.RWMutex 互斥锁和一个 map:
1 | var counter = struct{ |
读的时候,我们可以使用 RLock 获取读锁,然后访问 m 这个 map:
1 | counter.RLock() |
RLock是读锁,多个 goroutine 可以同时获取读锁,读锁释放之前,其他 goroutine 无法获取写锁。
写的时候,我们可以使用 Lock 获取写锁:
1 | counter.Lock() |
Lock是写锁,只有一个 goroutine 可以获取写锁,并且写锁释放之前,其他 goroutine 无法获取读锁,也无法获取写锁。
另一种解决方法 - sync.Map
除了使用互斥锁,我们也可以使用 Go 语言自带的 sync.Map 来解决这个问题:
1 | var m sync.Map |
虽然 sync.Map 可以实现并发的读写,但是底层上依然会有较多的竞态条件,所以性能上并不是最好的,本质上还是操作一个 map, 只是通过一些原子操作 + 自旋锁来实现并发安全的读写。
而且 sync.Map 设计出来的时候是为了应对一些特定的场景的,具体来说有以下两个场景:
- 当给定
key的条目只写入一次但读取多次时,如在只会增长的缓存中。(读多写少) - 当多个 goroutine 读取、写入和覆盖不相交的键集的条目。(不同 goroutine 操作不同的 key)
在这两种情况下,可以获得比用 Mutex + map 或 RWMutex + map 更好的性能,因为很多的锁操作都变成了原子操作。
具体细节可参考我此前的一篇文章:《深入理解 go sync.Map - 基本原理》
互斥锁、sync.Map 还不是最优的解决方案
使用互斥锁或者 sync.Map 的方式,虽然都可以解决 map 并发读写的问题,但是性能上都不是最优的。
因为它们底层还是会有互斥锁的竞争。这就意味着,在进行写 map 操作时,可能会存在较多的锁竞争,从而导致性能下降。
map 分片
如果我们有了解过 MongoDB,就会知道,MongoDB 中也有分片的概念,当数据量过大时, 单个 MongoDB 实例可能无法存储所有的数据,或者单个实例无法处理过多的读写请求, 这时候就需要将数据分片存储到多个 MongoDB 实例中,也就是按照一定的规则将数据存储到不同的机器上, 然后读写数据的请求也会依据一定规则被路由到对应的机器上。
同样的,如果我们的 map 并发请求过多,那么我们也可以将 map 分片, 将不同的 key 存储到不同的 map 中,这样就可以避免 map 的并发读写了。
我们需要做的是:通过 key 来计算其 hash 值,然后根据 hash 值来决定将 key 存储到哪个 map 中, 同时,我们每一个 map 都需要加上互斥锁,这样就可以保证每一个 map 的并发安全了。
具体如下图:
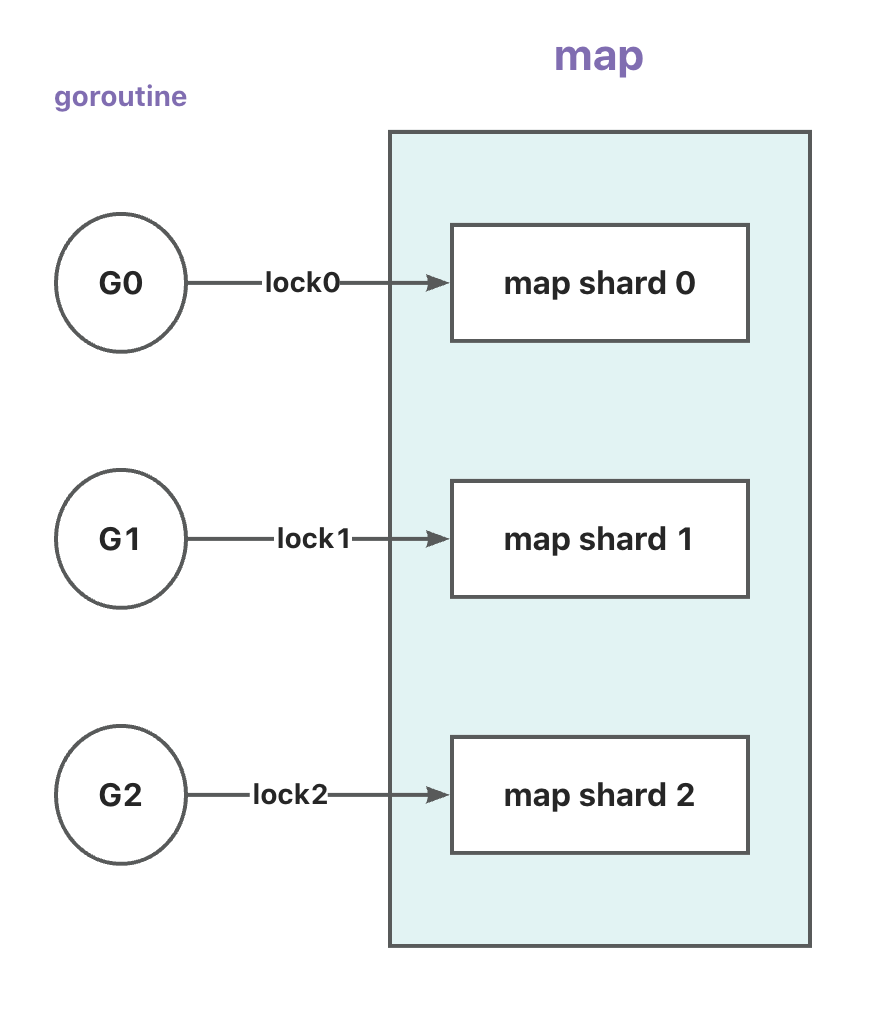
说明:
- 图中的
G0~2表示goroutine,lock0~2表示不同的互斥锁,map shard 0~2表示多个map分片。 goroutine中会根据key计算出hash值,然后根据hash值来决定将key存储到哪个map分片中,然后获取这个分片对应的锁,然后进行读写操作。
虽然上图画起来是 G1 不会访问到 shard 0 或者 shard 2,但实际上是有可能的,上图只是想说明: 多个 goroutine 可以多个锁来访问多个 map 分片,而不用像之前那样多个 goroutine 都来竞争同一把锁了。 也就减少了锁的竞争和等待。
代码实现
具体实现已经有一个开源的库了:orcaman/concurrent-map, 可以在 github 上搜到。
下面是它的部分代码:
1 | var SHARD_COUNT = 32 |
说明:
SHARD_COUNT是分片数量,也就是底层会有多少个map分片。ConcurrentMap表示一个支持并发读写的map,它底层包含了多个map分片,以及有一个根据key计算分片的函数。ConcurrentMapShared表示一个map分片,也就是上面提到的map + RWMutex组合。GetShard根据key获取对应的map分片。
单从代码的角度,它封装了更多的东西,性能相比单纯的
map + RWMutex自然会差一点, 但是从并发读写的角度来说,它比单纯map + RWutex要好很多。 因为它将原本只支持一个协程写的map转换为了支持多个协程写操作的map,一定程度上提高了并发
但是需要注意的是,我们需要频繁写同一个 key 的操作,上面这种分片的方式也不能带来性能上的提升。 分片的方式更适合那些 key 区分度高的、写操作频繁的场景。
总结
最后再简单回顾一下本文所讲内容:
- Go 的
map设计上不支持并发读写,如果我们有并发读写操作会直接panic。 - Go 的设计者们认为,多数情况下,我们并不需要从多个 goroutine 来对
map进行安全访问,所以他们没有在底层实现map的互斥操作。 - 有两种方法可以解决
map并发读写的问题:互斥锁、sync.Map。但是sync.Map设计上是应对某些特定场景的,并不合适所有场景。 - 我们可以通过分片的方式来解决
map并发读写的问题,这样可以减少锁的竞争,提高并发读写性能。目前已经有现成的开源库可以使用了。